主要内容:
Elasticseach介绍
Elasticseach使用场景
Elasticseach数据清理
1.1 导语
Elasticsearch(文中简称ES)是分布式全文搜索引擎,产品提供高可用、易扩展以及近实时的搜索能力,广泛应用于数据存储、搜索和实时分析。很多服务的可用性对ES重度依赖。以下为es的核心概念。

1.2 Elasticsearch数据写入
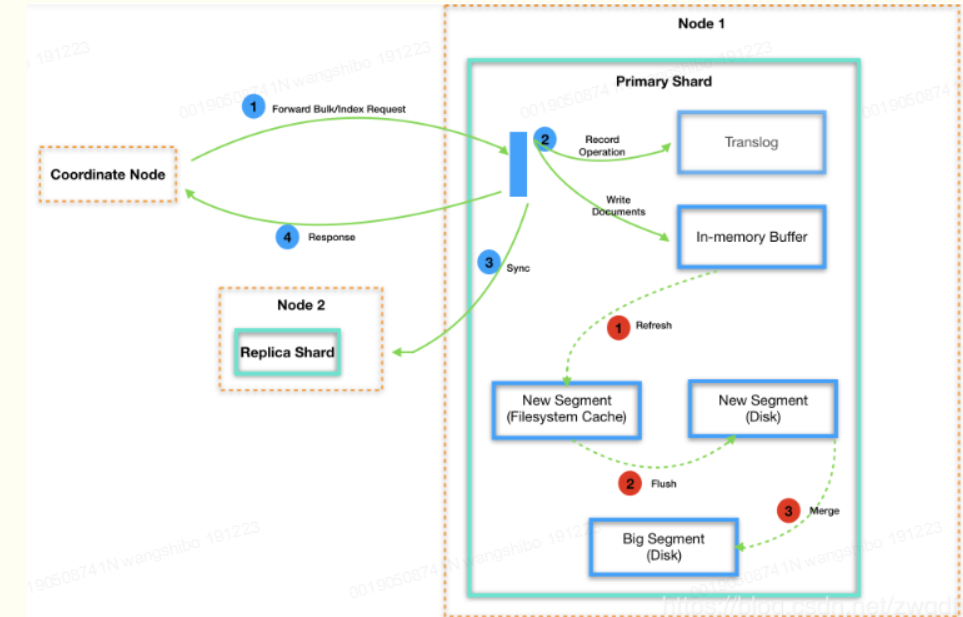
Elasticsearch数据写入过程包含同步与异步两个过程,如下图所示:
同步过程:是指在请求返回前做的事情,即包含在一个HTTP请求的过程中,客户端需要等其做完才能拿到结果。简单来看,这个过程需要完成三件事:第一,将操作记录写入到translog中,我们后面再来谈它的作用;第二,根据数据生成相应的数据结构,并写入到in-memorybuffer,注意是写入到一个内存buffer中,不是磁盘;第三,将数据同步到所有replicashard中。完成这些之后,就会生成相应的结果返回给coordinate节点了。
异步过程:一般来说,写磁盘很慢,且非常耗费CPU与IO,在同步过程中,为了让请求尽快返回,并没有将数据直接落盘。Elasticsearch的最小数据单元是segment,而此时数据还在in-memorybuffer中,因此这部分数据是不能被查询请求访问到的。只有当发生refresh动作,才会产生一个新的segment,将内存buffer中的数据写入到里面,同时清空buffer。默认refresh的时间间隔是1秒,可以配置,需要在实时性与性能之间进行权衡。此时虽然已经生成了新的segment文件,但是只是停留在filesystemcache中,并没有真正的落到磁盘中。这些动作的目的都是为了将"写磁盘"这件事尽可能的延后并变得低频,但是数据一直留在内存中始终是不安全的,很容易因为断电等原因导致数据丢失,因此每隔一段时间,Elasticsearch会真正做一次磁盘flush,完成数据的持久化。
Master配置elasticsearch.yml

Slave配置elasticsearch.yml
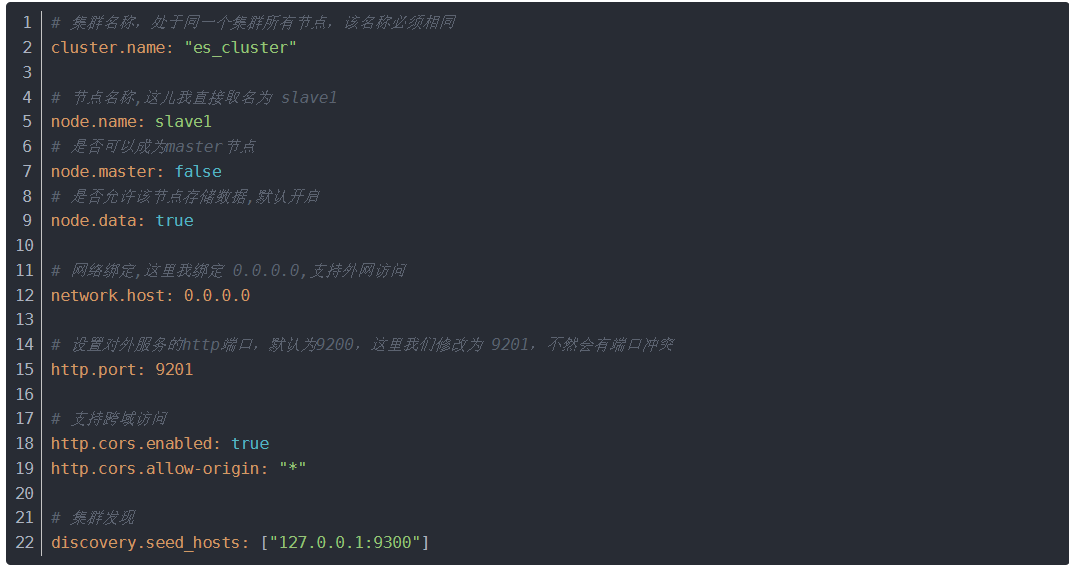
通过root加入如下配置,否则会报错


后台启动$ES_HOME/bin/elasticseach-d
3.1 Elasticsearch的应用
国外:
(1)维基百科,类似百度百科,全文检索,高亮,搜索推荐
(2)TheGuardian(国外新闻网站),用户行为日志(点击,浏览,收藏,评论)+社交网络数据,数据分析
(3)日志数据分析,logstash采集日志(1)维基百科,类似百度百科,全文检索,高亮,搜索推荐
(4)TheGuardian(国外新闻网站),用户行为日志(点击,浏览,收藏,评论)+社交网络数据,数据分析
(5)StackOverflow(国外的程序异常讨论论坛)
(6)GitHub(开源代码管理)
(7)电商网站,检索商品
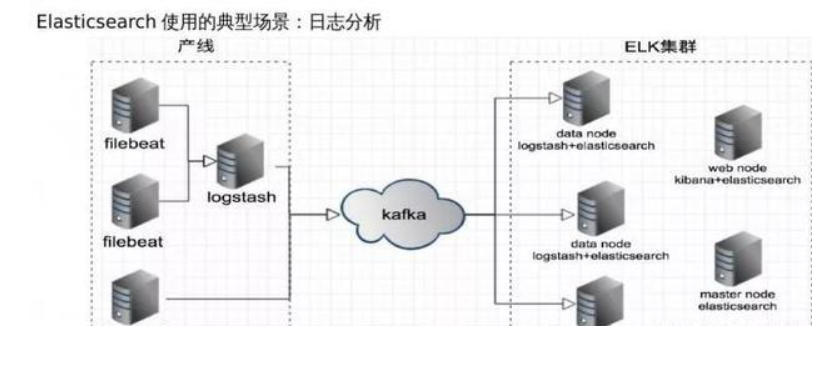
(8)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(9)商品价格监控网站
(10)BI系统,商业智能,BusinessIntelligence。
国内:
站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析。
3.2 Elasticseach全家桶
Kibana: 数据可视化,与elasticsearch交互。Elasticsearch:存储,索引,搜索。Logstash:数据收集,过滤,转换。Beats:比logstash更轻巧,更多样。

基于ELK和Kafka的日志分析系统
情景再现:
某个主机es进程挂掉,登录主机发现安装目录(data目录)使用率100%(当前是已清理的截图)。

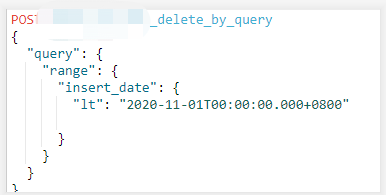
通过es命令curlhttp://ip:端口号/_cat/indices查询到所有索引大小
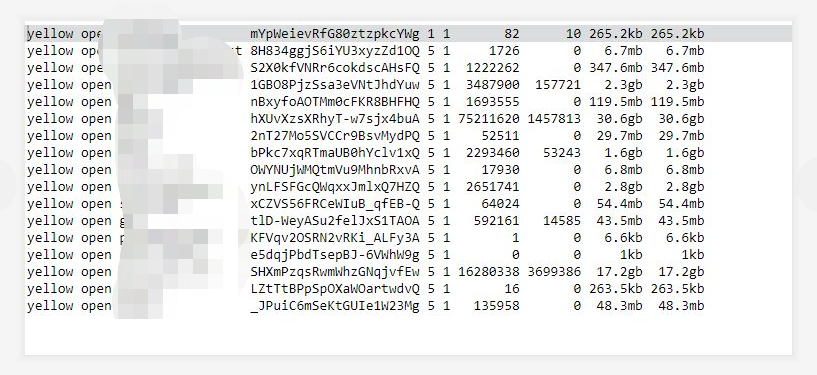
通过post索引名/_delete_by_query按条件删除索引较大的历史数据