




最近因工作原因,和ES接触的比较多;ES之前了解过,不怎么熟悉,故打算系统学习之。
以下文章转载之如下链接:
https://www.modb.pro/db/390323
正文如下:
目录
一、概述
1.1、什么是ES
1.2、倒排索引
1.2.1、什么是倒排索引
1.2.2、倒排索引的核心组成
1.3、核心概念
二、安装
2.1、Linux下安装
2.1.1、安装ElasticSearch
2.1.2、安装kibana
2.2、Docker安装
2.2.1、安装Elasticsearch
2.2.2、安装kibana
一、概述
1.1、什么是ES
一个开源的高扩展的分布式全文检索引擎,可近乎实时的存储、检索数据,可扩展性强,可处理PB级别的数据。
通过简单的Restful API, 来隐藏Luncee的复杂性,从而让全文搜索变得简单
1.2、倒排索引
1.2.1、什么是倒排索引
倒排索引是一种数据结构
Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤。
1、把每个文档拆分为独立的词
2、创建一个包含所有且不重复的词条列表
3、记录每个词条出现在哪些文档中
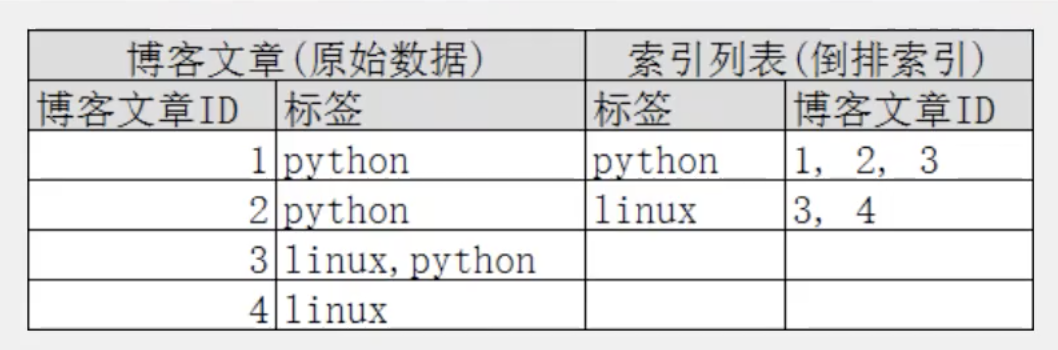
这样,搜索linux,就能快速定位到3、4文档
1.2.2、倒排索引的核心组成
倒排索引包含2个部分:单词字典、倒排列表
单词字典(Term Dictionary)
单词字典记录所有文档的单词和倒排列表的关联关系
单词字典一般比较大,可以通过B+树或哈希拉链表实现,以满足高性能的插入和查询
倒排列表(Posting List)
倒排列表由索引项组成
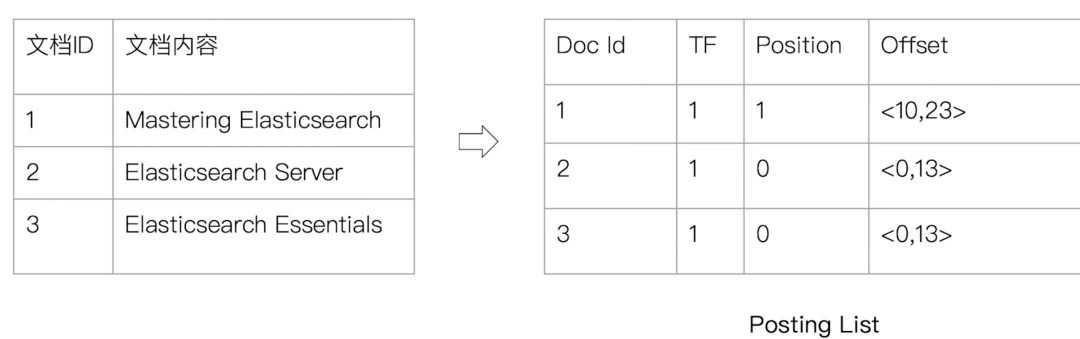
文档id
词频TF:该单词在文档中出现的次数,用于相关性评分
位置:单词在文档中的分词位置,用于语句搜索
偏移:记录单词的在文档中的起始和结束位置,用于高亮显示
索引项
1.3、核心概念
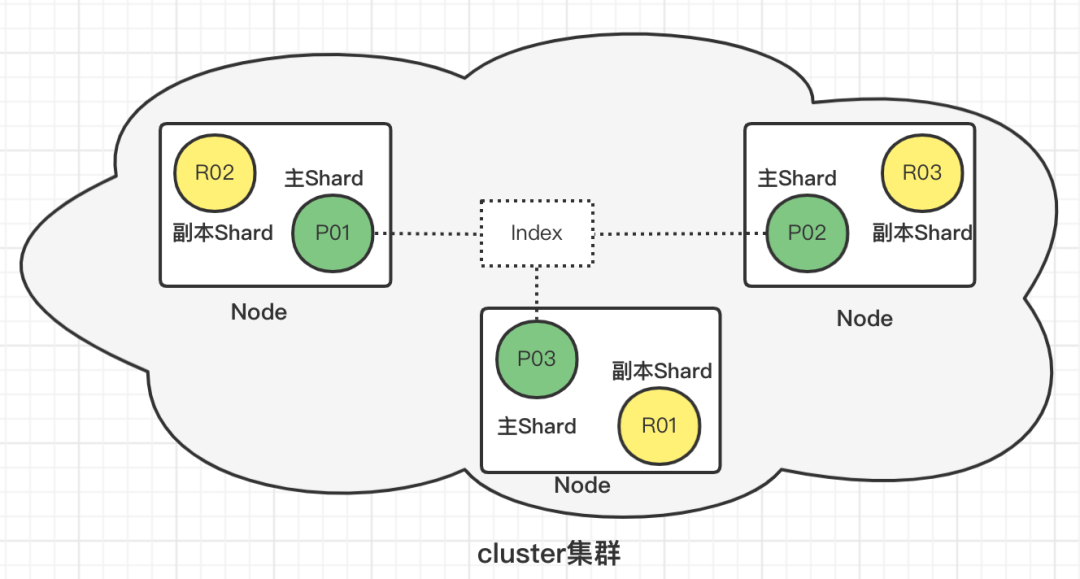
1、es提供了分布式集群(Cluster)的方式,保证高可用
2、多个节点(Node)组成一个集群
3、一个节点中分布着多个索引(index)/索引的一部分(分片Shard)
4、节点间多个分片组成一个index
Near Realtime(近实时)
Elasticsearch是一个近乎实时的搜索平台,这意味着从索引文档到可搜索文档之间只有一个轻微的延迟(通常是一秒钟)。
Cluster(集群)
群集是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个群集都有自己的唯一群集名称,节点通过名称加入群集。
Node(节点)
节点是指属于集群的单个Elasticsearch实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为elasticsearch
的群集。
1.2.4、Index(索引)
索引是一些具有相似特征的文档集合,类似于MySql中数据库的概念。但是在Elasticsearch 6.0.0及更高的版本中,一个index只能包含一个type,其实也类似于一个Index就是一个表。
Type(类型)
类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似MySql中表的概念。
注意:在Elasticsearch 6.0.0及更高的版本中,一个索引只能包含一个类型。
Document(文档)
文档是可被索引的基本信息单位,以JSON形式表示,类似于MySql中行记录的概念。
Shards(分片)
当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力、并允许跨分片分发和并行化操作,从而提高性能和吞吐量。
主分片
主分片用于解决数据水平扩展问题。通过主分片,可以将数据分布到集群内的不同节点上。主分片在创建索引时指定,后续不允许修改
在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。
副本分片(Replicas)
副本分片用于解决数据高可用问题。是主分片的拷贝。副本分片数可以动态调整。
================================
转文至此。
以下是个人微信公众号,欢迎关注:

