





云原生数据库管控
探索和实践

无法利用云上 IaaS 层的资源池和弹性扩缩容的能力,以及 IaaS 层成本和性能优化的红利; 缺少统一的数据库 PaaS 平台,对多个产品、多个环境进行统一管控和调度; 业务功能复用程度低,造成人力资源浪费; 无法利用云原生红利,平台无法标准化,运维和交付成本比较高;
腾讯云数据库云上SaaS
生态演进

DTS数据迁移是面向单次的数据库迁移上云、下云,支持常见的链路,可以实现历史全量和动态增量的迁移,同时它还支持一致性校验,可以在迁移前随时发起一致性校验,帮助客户预知迁移效果。在迁移中,DTS能够保证数据的正确性以及做到对源库无感知,潘怡飞表示这也是客户最关注的点。 DTS数据同步是指两个数据源之间的数据长期实时同步,具有多种高级特性,例如库表重映射、DML/DDL过滤,Where条件过滤;主要适用于云上云下多活、异地多活,跨境数据同步、实时数据仓库等场景。 DTS数据订阅是指实时按需获取数据库中关键业务的数据变化信息,将这些信息包装为消息对象推送到内置Kafka中,方便下游实时消费应用;适用于异构数据更新等。
大规模在线数仓技术
构架分享

TDSQL升级版引擎架构和关键技术介绍

兼容性:建表需要手动指定shardkey; 运维:存储层扩容,需要DBA发起,部分事务会中断; 模式变更:online DDL依赖Pt等工具。
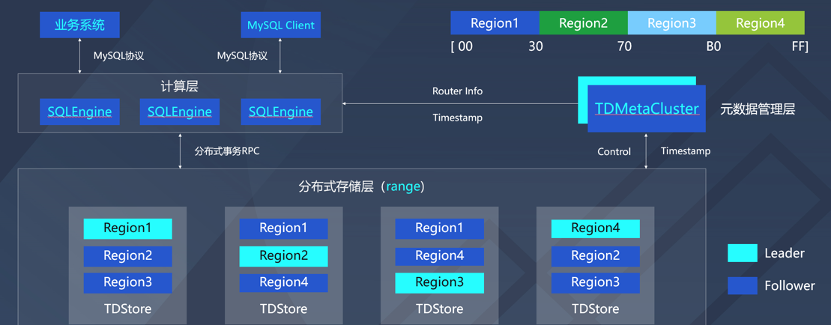
兼容性:具有TDSQL兼容性,升级版的架构是原生分布式结构,数据以key range打散和路由,成本比较低;存储层采用LSM-Tree结构,压缩比有量级的提升,非常适合于大规模业务量的业务。 可扩展性强:首先计算层是多主模式,每个SQLengine均可读写,同时是无状态化设计,可根据业务流量随时灵活添加或减少一些计算节点。存储层也是根据业务数据存储量需求,去做平滑的添加或者移除TDstore节点,通过数据自动迁移,实现容量弹性伸缩,做到业务层无感知。 一致性:事务模型具有全局读一致性,围绕管理层TDmetacluster统一分配全局唯一递增事务时间戳来做数据的一致性的判断。 支持在线变更:计算节点支持在线模式变更,目前已经支持了在线操作、索引操作等。
﹀
﹀
﹀

金融场景下,分布式数据库如何精准选型和快速落地?
文章转载自腾讯云数据库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
