




国产数据库梳理
当前国产数据库百花齐放,几乎每隔半年就会冒出一家数据库,各大厂商在去年也都更新了自己的数据库产品线名称,太多的数据库让人混淆。
本文是对几大巨头厂商产品的一个梳理,给大家做个普及。
背景介绍及架构介绍
网上对这些数据库介绍有些误导,流传各种说法,比如:流传OB基于MySQL、GaussDB 200/300 和openGauss有啥区别,没办法谁让当前国产数据库太多…
| Tidb | PolarDB | TDSQL | GaussDB | OceanBase | |
|---|---|---|---|---|---|
| 公司 | PingCap | 阿里云 | 腾讯 | 华为 | 阿里 |
| 历史 | 基于Google Spnner论文实现的原生分布式数据库 | PolarDB现在也是一个系列,分别是:PolarDB-X分布式数据库从DRDS升级过来的,PolarDB-O兼容Oracle数据库,PolarDB-MySQL/PostgreSQL Shared-Storage架构对比AWS Aurora但实现有所不同,Aurora对内核改动更大,完全取消了数据文件,PolarDB则是用redo进行节点之间的传输 | 现在做了名字修改,分为TDSQL-MySQL和PG,PG版是以前的TBase。TDSQL-C对标的是Aurora | GaussDB现在是一个系列,现在常说的就是PG这个版本,以前叫做100,200,300对应现在的openGauss(交易型),GaussDB DWS(分析型),GaussDB for openGauss(HTAP)。GaussDB for MySQL对标Aurora) | 100%自研,没有基于任何开源数据库模块,经历开源->闭源->开源 |
从架构相似看各个厂家之间产品对标:
- MySQL系列
| PingCap | 腾讯 | 阿里 | 华为 | 备注 | |
|---|---|---|---|---|---|
| Tidb | TDSQL-新敏态引擎 | ||||
| TDSQL-MySQL | PolarDB-X(以前的DRDS) | DDM | |||
| TDSQL-C for MySQL | Polardb for MySQL | GaussDB for MySQL | 这一类需要带云底座,依赖于底层文件系统 |
- PG系列
| PingCap | 腾讯 | 阿里 | 华为 | 备注 | |
|---|---|---|---|---|---|
| TDSQL-PG | GaussDB for openGauss | ||||
| TDSQL-C for PostgreSQL | Polardb for PostgreSQL | 这一类需要带云底座,依赖于底层文件系统 |
架构上划分
产品太多,如果从各家产品做划分介绍会有很大重复性,从架构角度看会比较清晰
分库分表类
这类架构相信大家很熟悉了,发展到现在也很长时间了,通过Proxy进行数据路由和分片,数据节点存放具体数据一般是主备数据库架构,由于历史原因这类架构下MySQL版本与PG版本会有不同:
-
MySQL
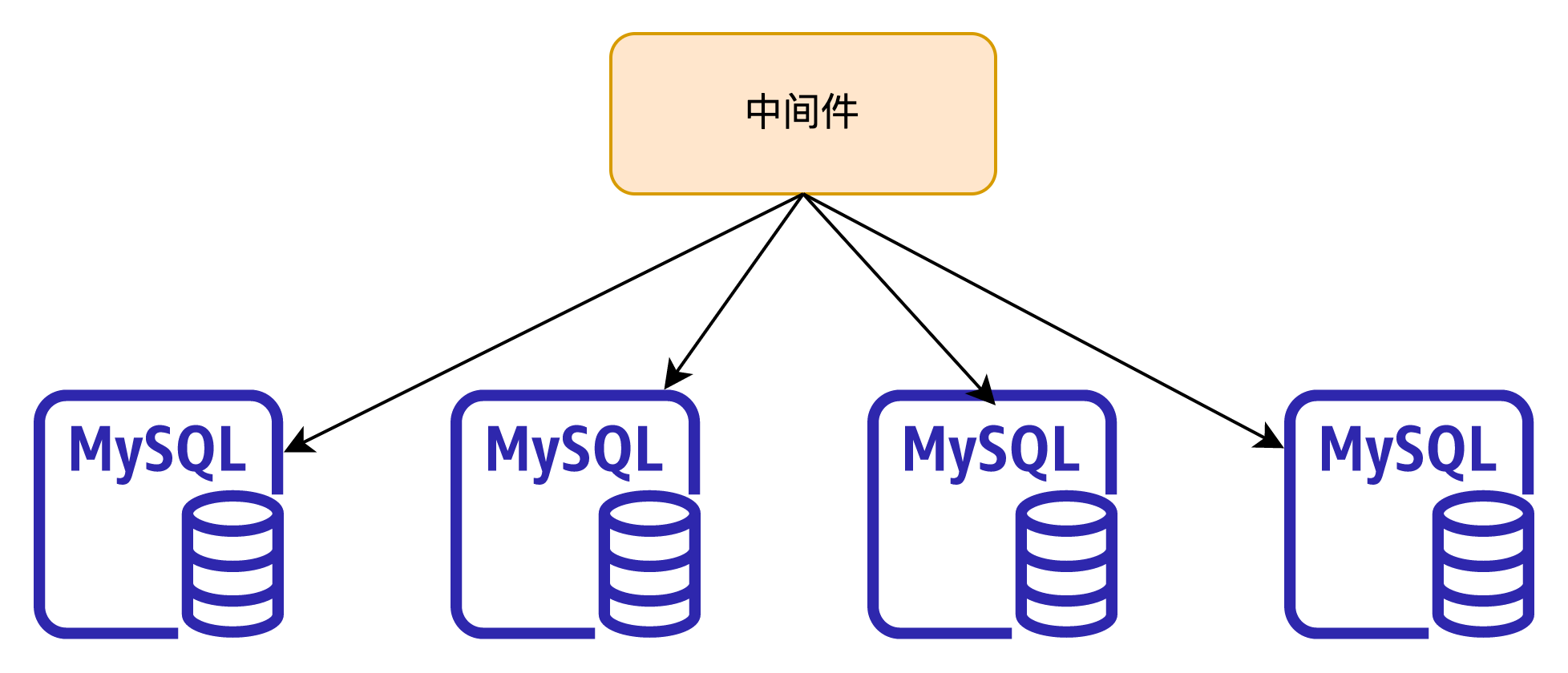
-
PG
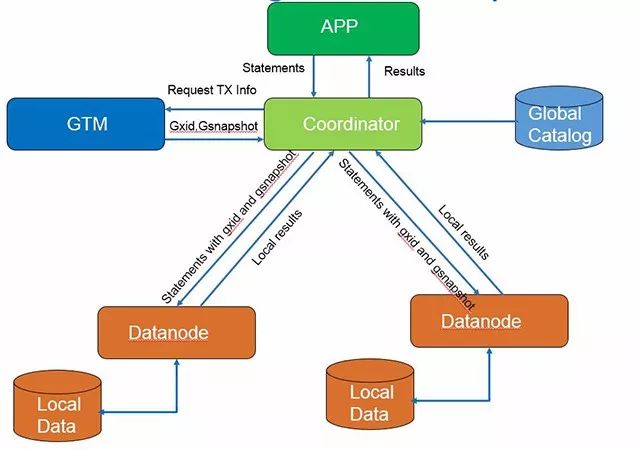
这类分库分表架构优缺点明显,数据按表中某一个字段做水平拆分,对于业务简单查询维度单一,每次都能带有这个分片键,性能上会有很大优势,随着数据节点增加会有很好的线性上升,但问题也很明显对复杂SQL语句的支持,跨节点查询数据需要汇总到Proxy或者Coordinator节点,对网络和CPU都会有较大压力,通常都需要应用做改造适配可能还会做一些业务妥协。
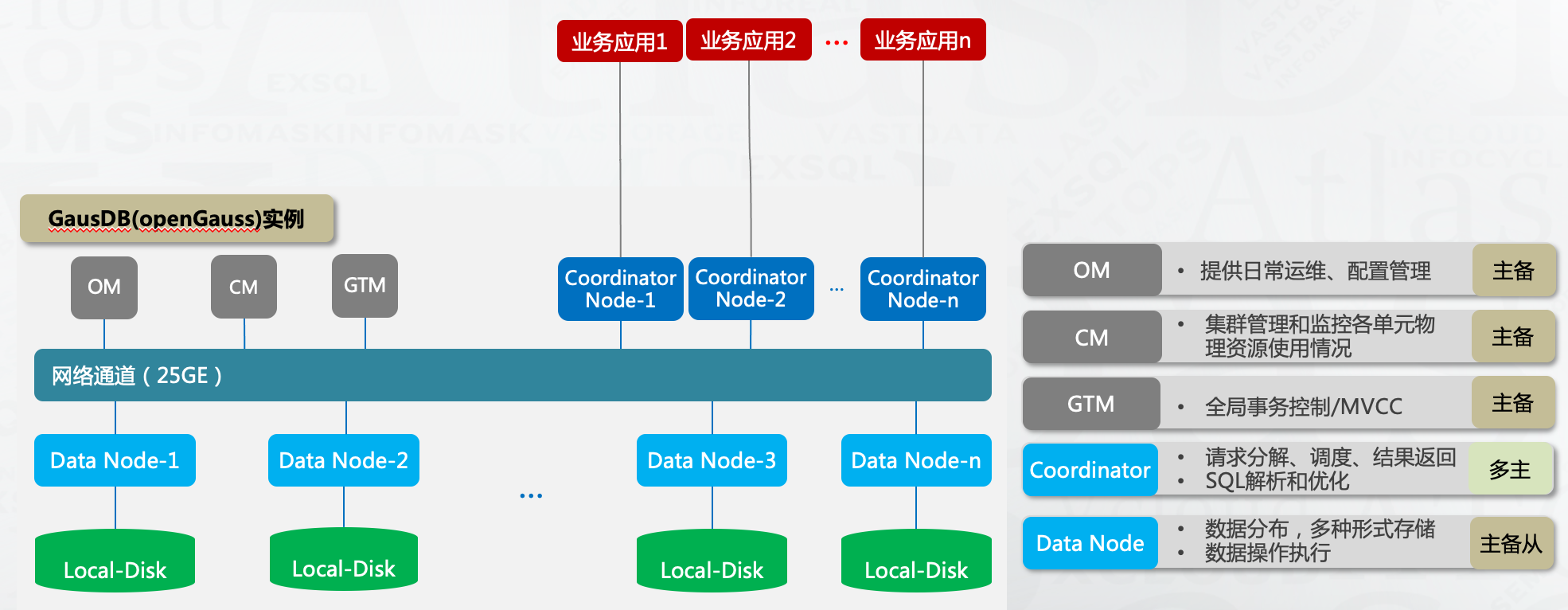
目前PG版本的分库分表架构已知的都是来自于PGXC,相比MySQL多了GTM节点负责全局一致性快照管理,且Coordinator节点是一个完整的PG数据库,天然支持SQL语法词法解析,相对来说对于复杂SQL的支持会好一些。
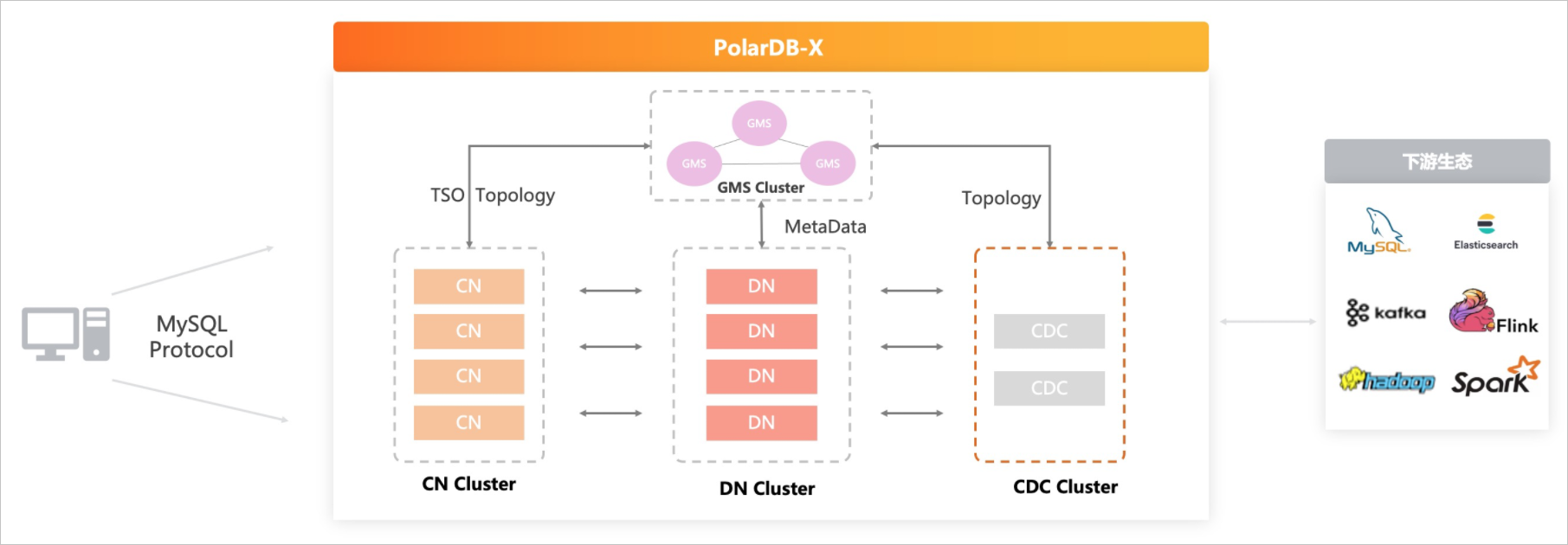
当然阿里的PolarDB-X则有些不同,提供GMS节点作为全局时间戳管理
代表产品:
| 公司 | MySQL | PG |
|---|---|---|
| 腾讯 | TDSQL-MySQL | TDSQL-PostgreSQL |
| 华为 | DDM分布式中间件 | GaussDB for openGauss |
| 阿里 | PolarDB-X |
针对跨节点查询的SQL,GaussDB for openGauss与TDSQL-PostgreSQL分别提供了Stream流(广播流、聚合流和重分布流)和数据重分布(Data Redistribution)减少跨节点查询性能问题,以GaussDB for openGauss为例:
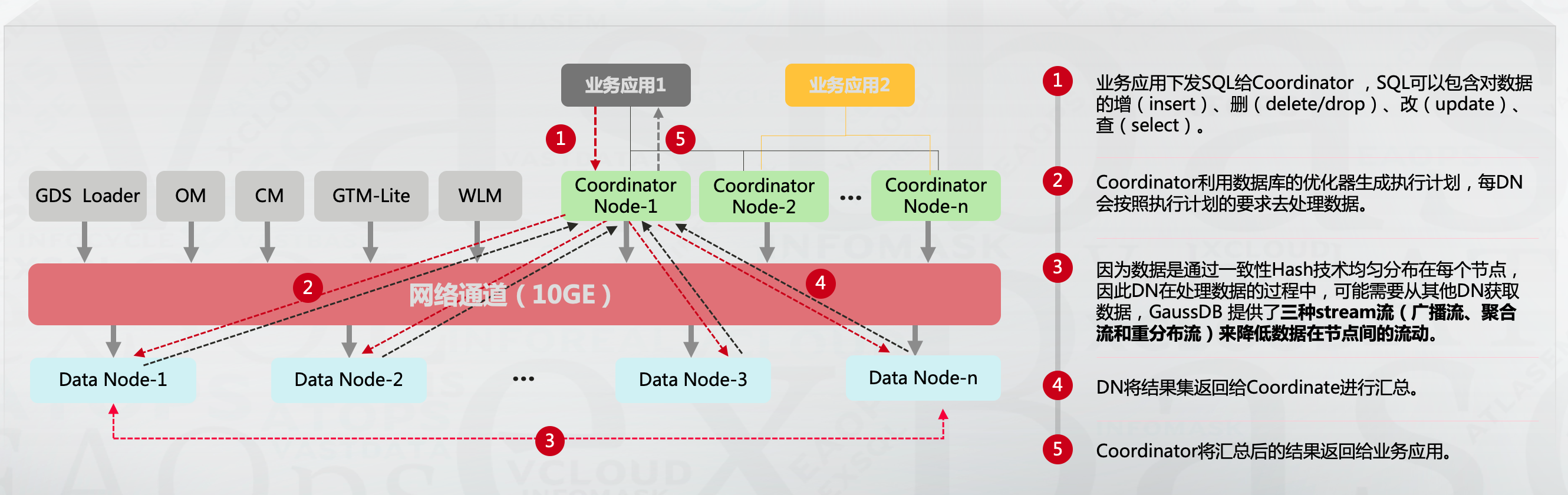
节点之间会做数据交互,尽可能将计算操作offload到数据节点,减少CN节点计算压力和CN,DN之间网络流量压力。这是当前场景的优化方法卸载计算资源压力。
此外Polardb-X还通过只读节点,将AP与TP流量进行物理隔离,提供HTAP处理能力
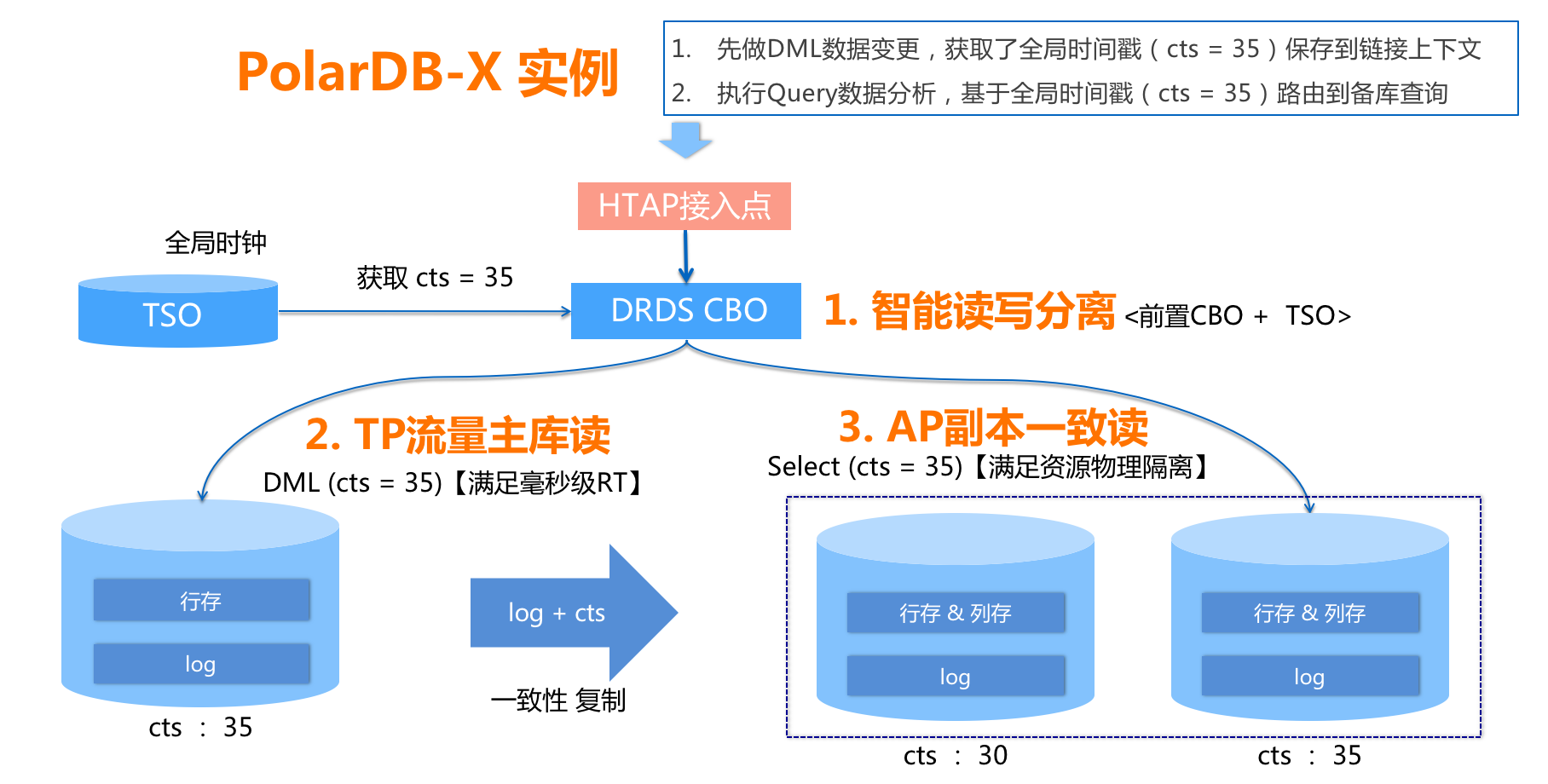
这类架构扩容是比较大的挑战,根据已有资料的了解MySQL和PG这两个系列扩容不相同:
MySQL系通常做法是创建表时默认创建256个分片,后面再添加DN节点时通过迁移分片完成扩容,这种做法方便但DN节点数有上限。
PG系的做法是数据重分布,并不是提前在一个DN上创建多个分片,重分布过程通过全量+增量的方式,实现比较麻烦但理论上没有上限
| TDSQL-MySQL | TDSQL-PostgreSQL | GaussDB for openGauss | PolarDB-X(兼容MySQL) | |
|---|---|---|---|---|
| 动态扩展 | 支持 | 支持 | 支持,需要对等比例扩容 | 支持 |
| 存储过程 | 不支持 | 支持 | 支持 | 不支持 |
| 物化视图 | 不支持 | 支持 | 支持 | 不支持 |
| 全局索引 | 不支持 | 不支持 | 不支持 | 支持 |
| 临时表 | 不支持 | 支持 | 支持 | 不支持 |
| 多租户(线下部署不带云底座) | 支持,通过多实例方式 | 不支持 | 不支持 | |
| 触发器 | 不支持 | 支持 | 支持 | 不支持 |
| 闪回 | 支持 | 不支持 | 不支持 | 支持 |
| Oracle兼容性 | 不支持 | 支持 | 不支持 | 不支持 |
| 节点之间分布式执行 | 不支持 | 支持 | 支持 | 支持 |
| 列存 | 不支持 | 支持 | 支持 | 支持(通过搭建只读实例) |
TDSQL-MySQL使用限制:https://cloud.tencent.com/document/product/557/47511
PolarDB-X 使用限制:https://help.aliyun.com/document_detail/313262.html
Spanner 架构
Tidb根据Google Spanner和F1做的实现,是一个具备易扩展、高性能、高可靠的NewSQL分布式数据库,相比分库分表架构在动态扩容上更加友好,且用户不需要再考虑分片键的选择,业务不会有很大的改造。
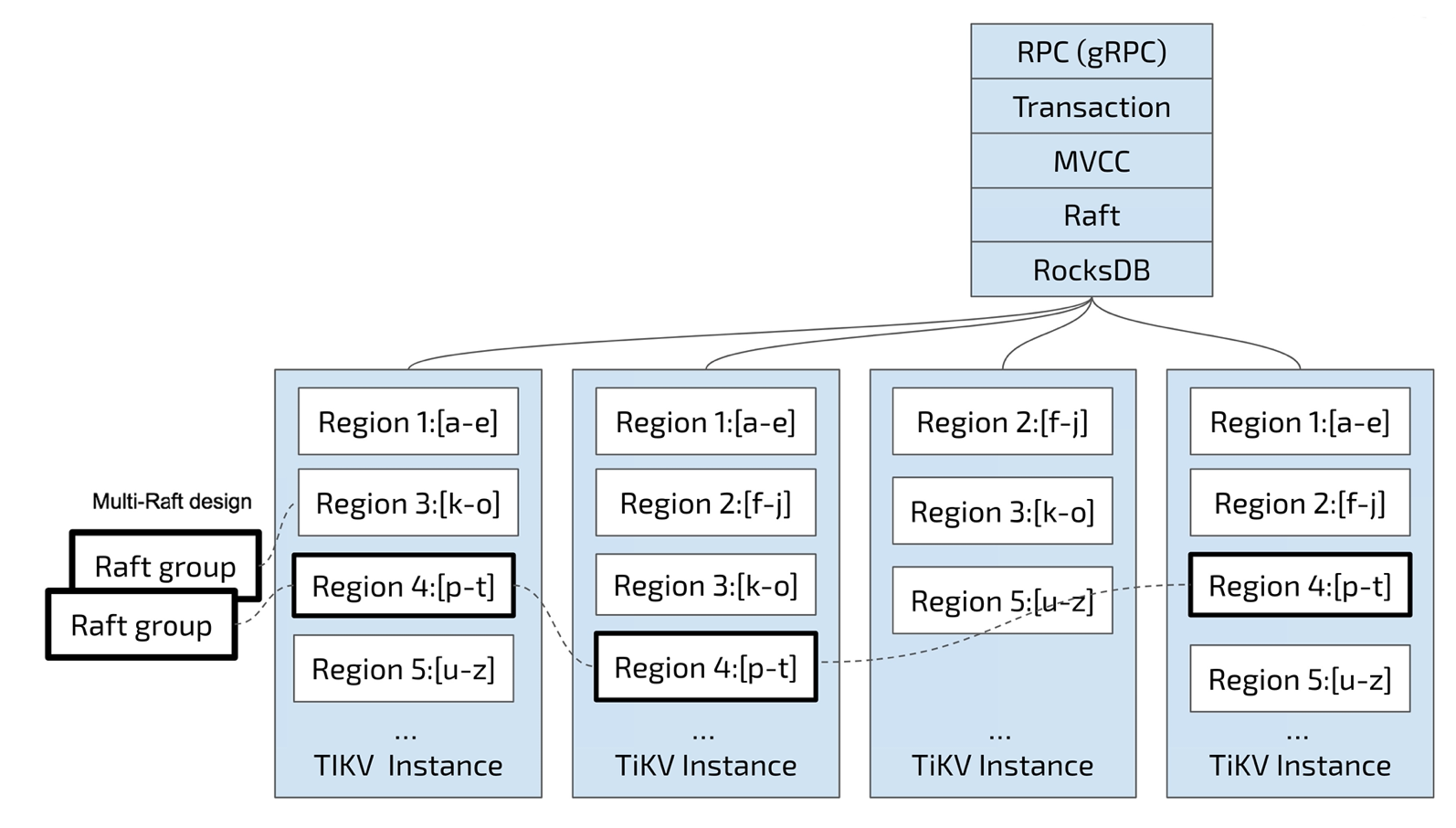
从架构上是 Share Nothing 架构,计算存储分离,PD负责调度和存储元数据信息,TIKV存储层,Tidb接入层
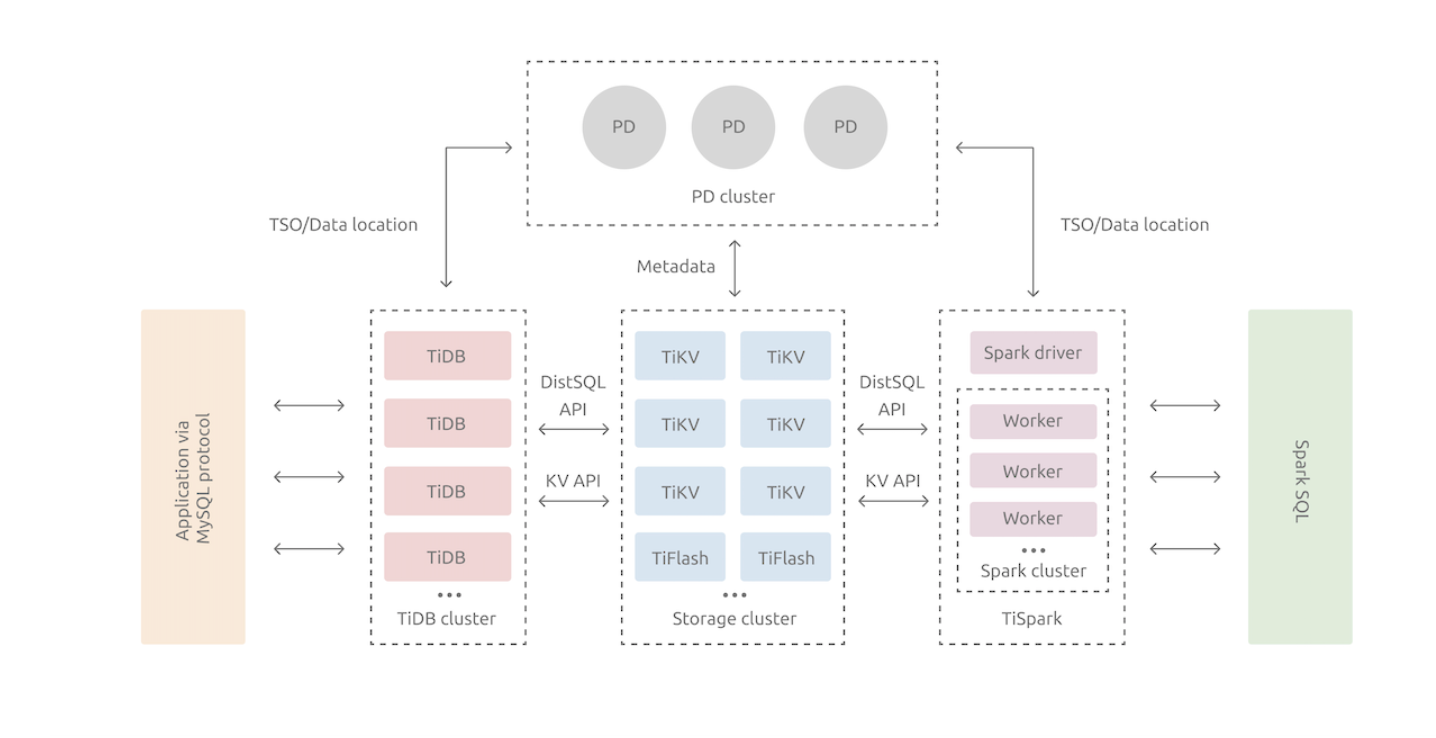
将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且 会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey, EndKey) 这样一个左闭右开区间来描述
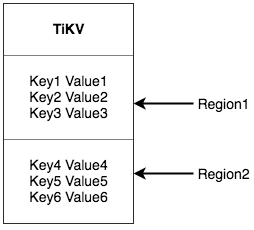
数据按Key切分为多个Region,PD负责将Region尽可能分布到不同的机器上,方便日后的扩容和Region的负载均衡,在Region内部数据是连续存储的,Region是三副本,使用Raft协议保证了一致性。
PD记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪 个 Region 中,以及这个 Region 目前在哪个节点上(即 Key 的位置路由信息。
表数据与Key-Value映射关系是将TableID+RowID组成Key,字段作为Value,TableID全局内唯一
Key: tablePrefix{TableID}_recordPrefixSep{RowID} Value: [col1, col2, col3, col4]
索引数据和 Key-Value 的映射关系,主键和唯一索引可根据key直接查找对应的RowID定位一条记录
Key: tablePrefix{tableID}_indexPrefixSep{indexID}_indexedColumnsValue Value: RowID
普通索引存在多个值,所以根据索引确定一个RowID范围,再根据RowID查询到对应Region查询数据:
Key: tablePrefix{TableID}_indexPrefixSep{IndexID}_indexedColumnsValue_{RowID} Value: null
这点会比分库分表架构下,没有根据分片键查询效率高一些。但可能存在热点数据问题,Region内的数据是顺序增长的,很有可能访问的数据都在一个Region内。
Tidb5.0之后新推出了Tiflash引擎,结合之前的Tikv提供HTAP处理能力,Tidb的这种方案与解析MySQLBinlog同步到具有AP能力的数据库不同,使用Raft直接同步到Tiflash中,数据一致性上有很大保障
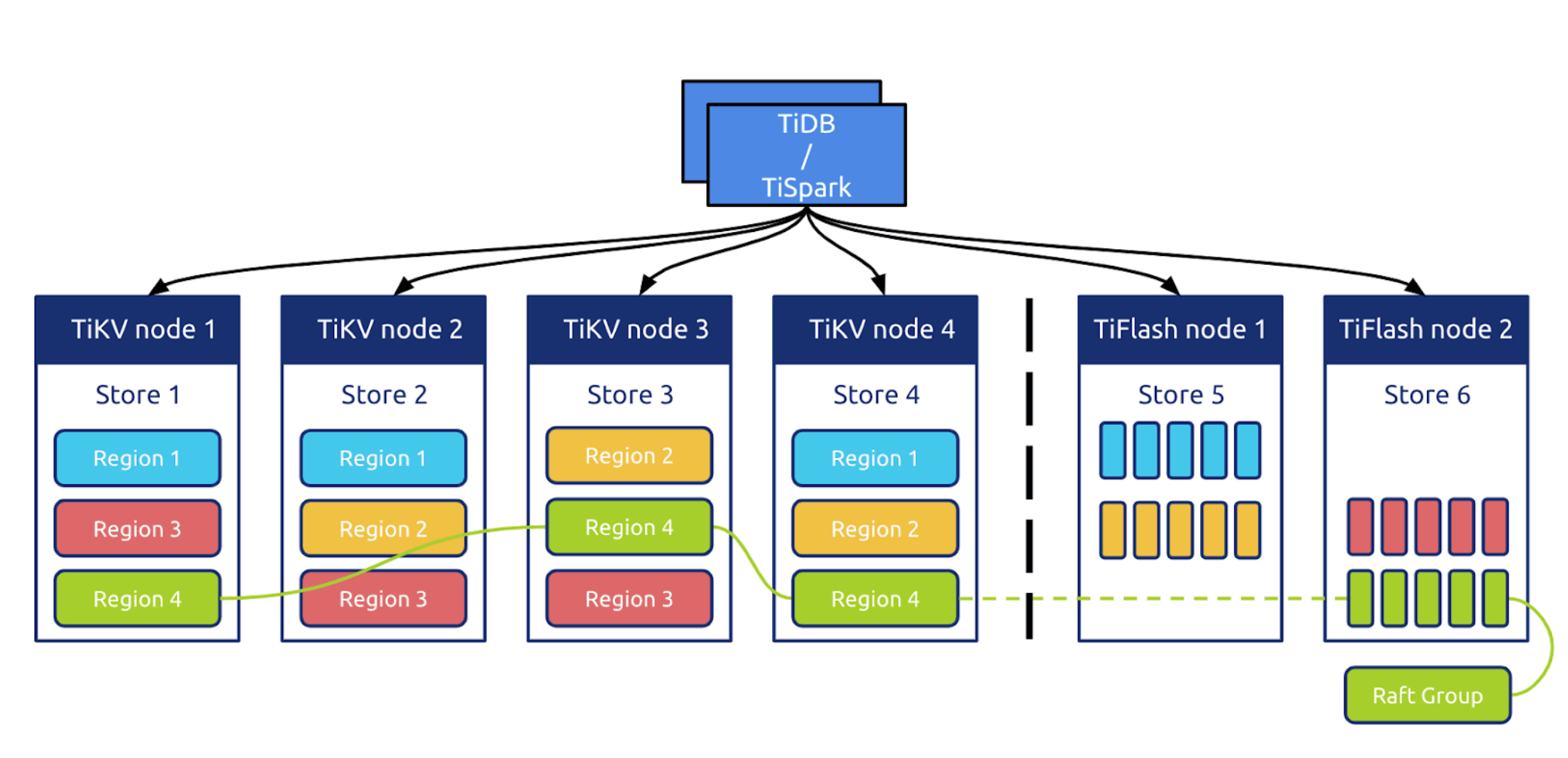
Tidb限制:https://docs.pingcap.com/zh/tidb/dev/tidb-limitations
Tidb与MySQL兼容性对比: https://docs.pingcap.com/zh/tidb/dev/mysql-compatibility
腾讯目前也推出了类架构,TDStore存储引擎
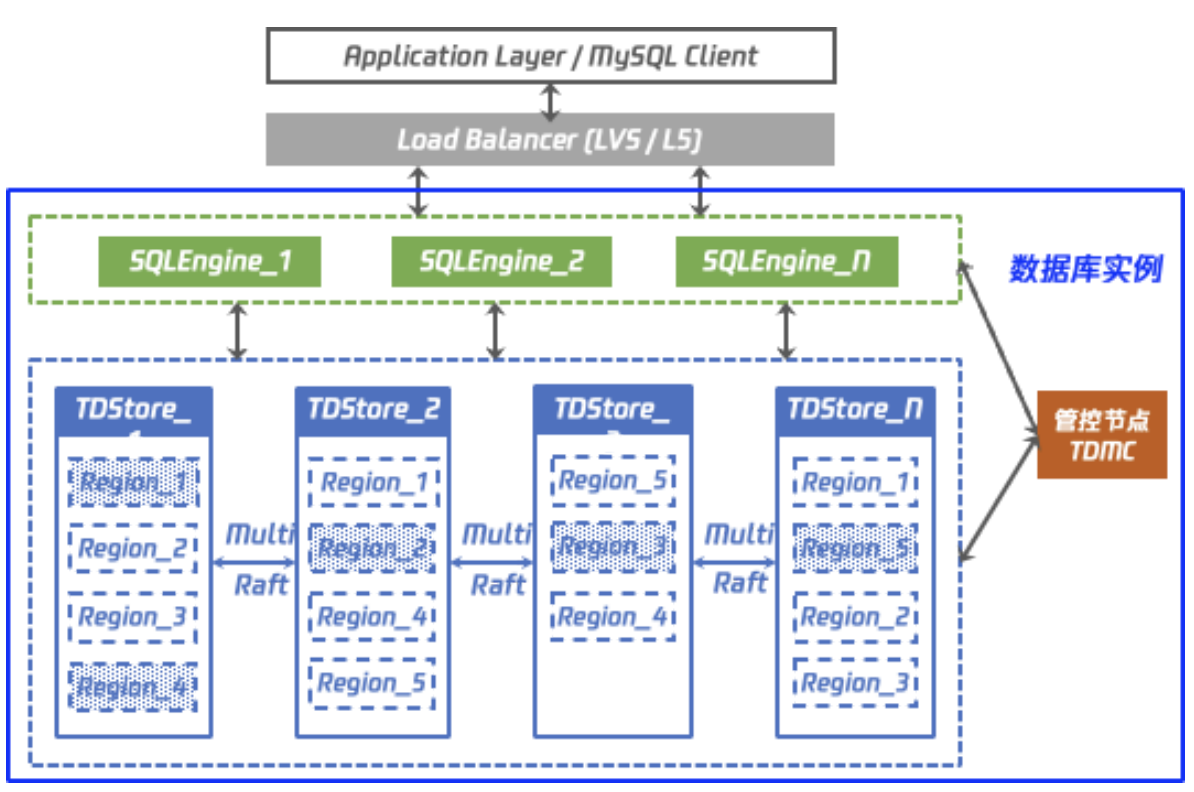
使用限制:https://cloud.tencent.com/document/product/557/63523
这种架构扩容可以通过迁移Region方式,PD节点来负责这个的调度,迁移Region这种会比做数据重分布简单方便,并且Region也有大小控制,超过阈值后会进行分裂,所以理论上扩容节点是没有上限。
OceanBase
OB是蚂蚁自研的分布式数据库,OB可以说与国内其它厂商都不同,OB是100%自研并没有使用任何开源存储引擎、优化器模块是真正意义自主可控。架构上OB也与其它架构不同,感觉介于分库分表和Tidb这两种架构之间。
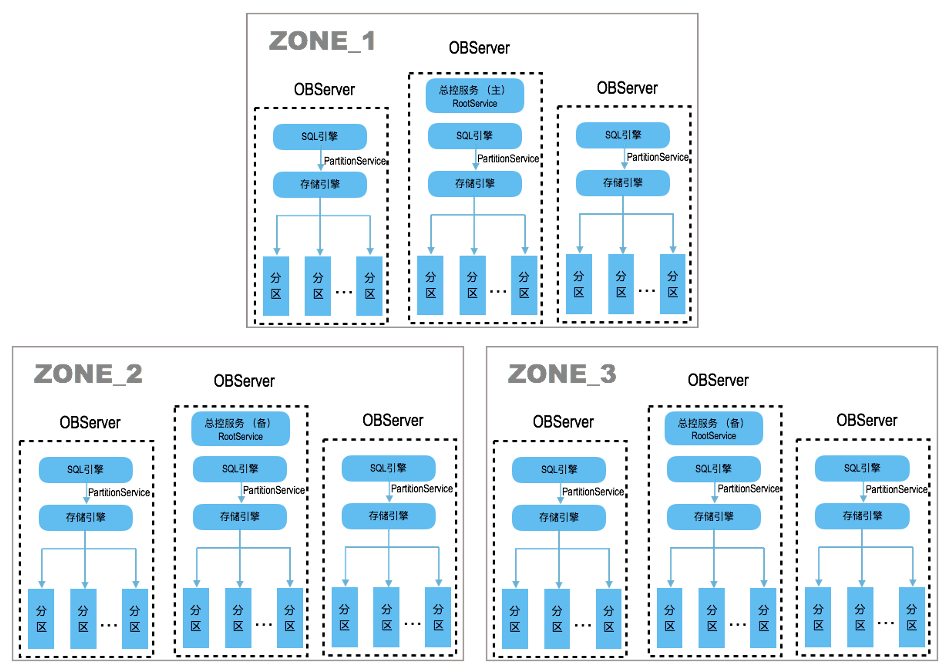
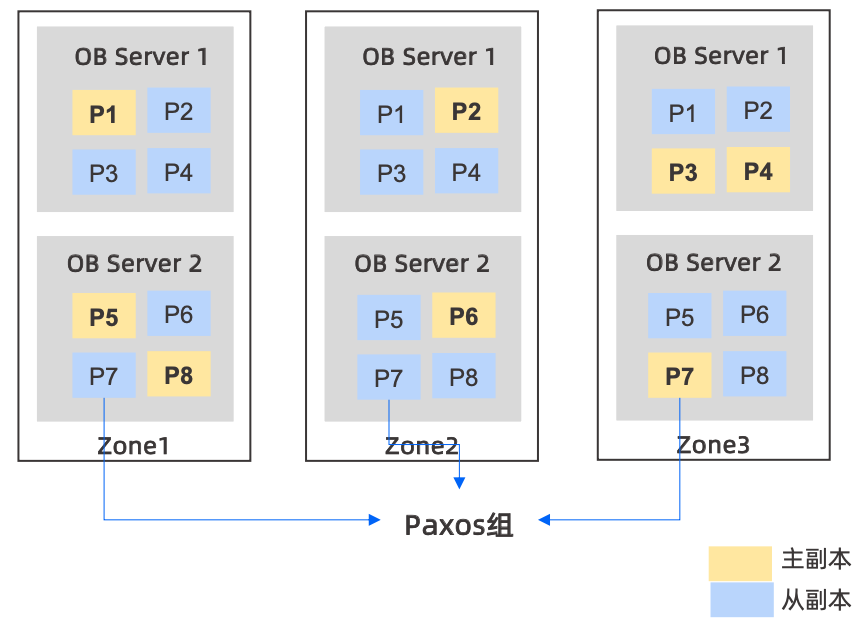
如上图所示,做一些解释:
- Zone可认为是不同地区或者不同机房,也可以是同一个机房不同机架,甚至也可以是同一个机架,根据系统和物理环境而定
- 每个Zone内可以是一台或者多台OBServer
- 针对每张表可以做分区表,不同的分区表打散到不同的OBServer节点上,所以分区是OB中最小的单元
- 如果不创建分区表,也可以设置以表的维度拆分到不同的OBServer上
下图更为直观一些
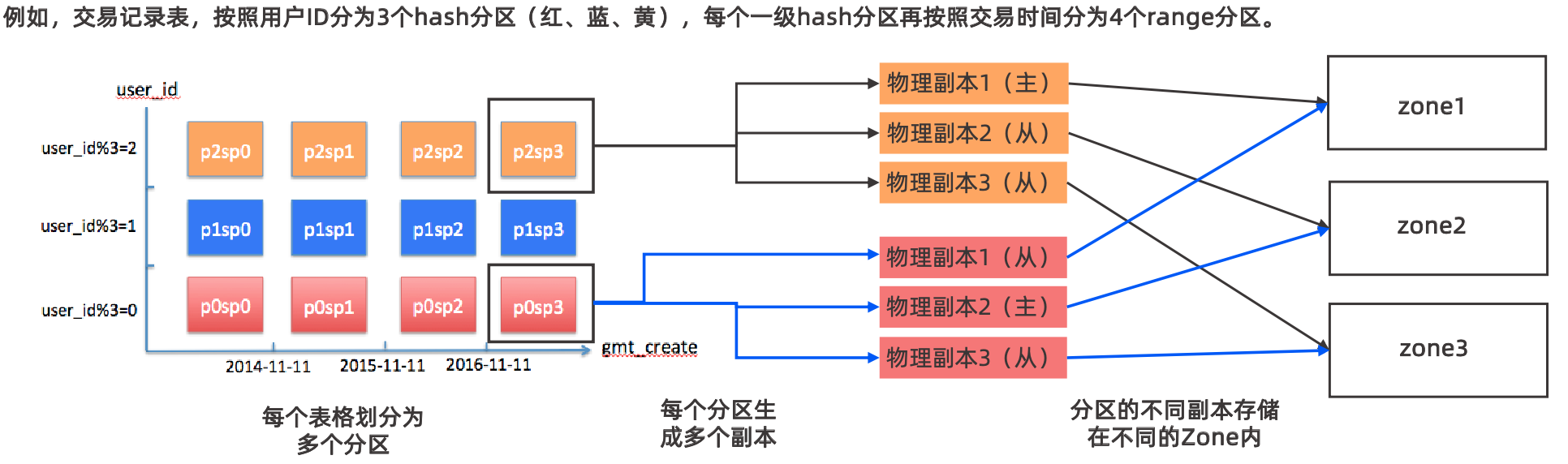
如上图有3个zone,8个分区,每个zone中有两个OBServer,每个分区都有三个副本,分布在不同zone中的OBServer上,OB以分区为最小单位组成Paxos组,通过Paxos保证了多副本之间的数据一致性,但Paxos需要多数派提交性能上不一定会比分库分表好。
这里就需要应用开发阶段考虑到分区键,其实和分库分表架构有点像了,都是要用分片键定位到某一个分区,如果不带有分片键则可能需要扫描所有分区,当然OB中针对这种问题提供了全局索引功能,解决这种不带有分区键的SQL语句,但全局索引会涉及到分布式事务,对性能有一定影响。
如果不是分区表则会如下图这种,三个副本之间也是通过Paxos协议保证数据一致性:
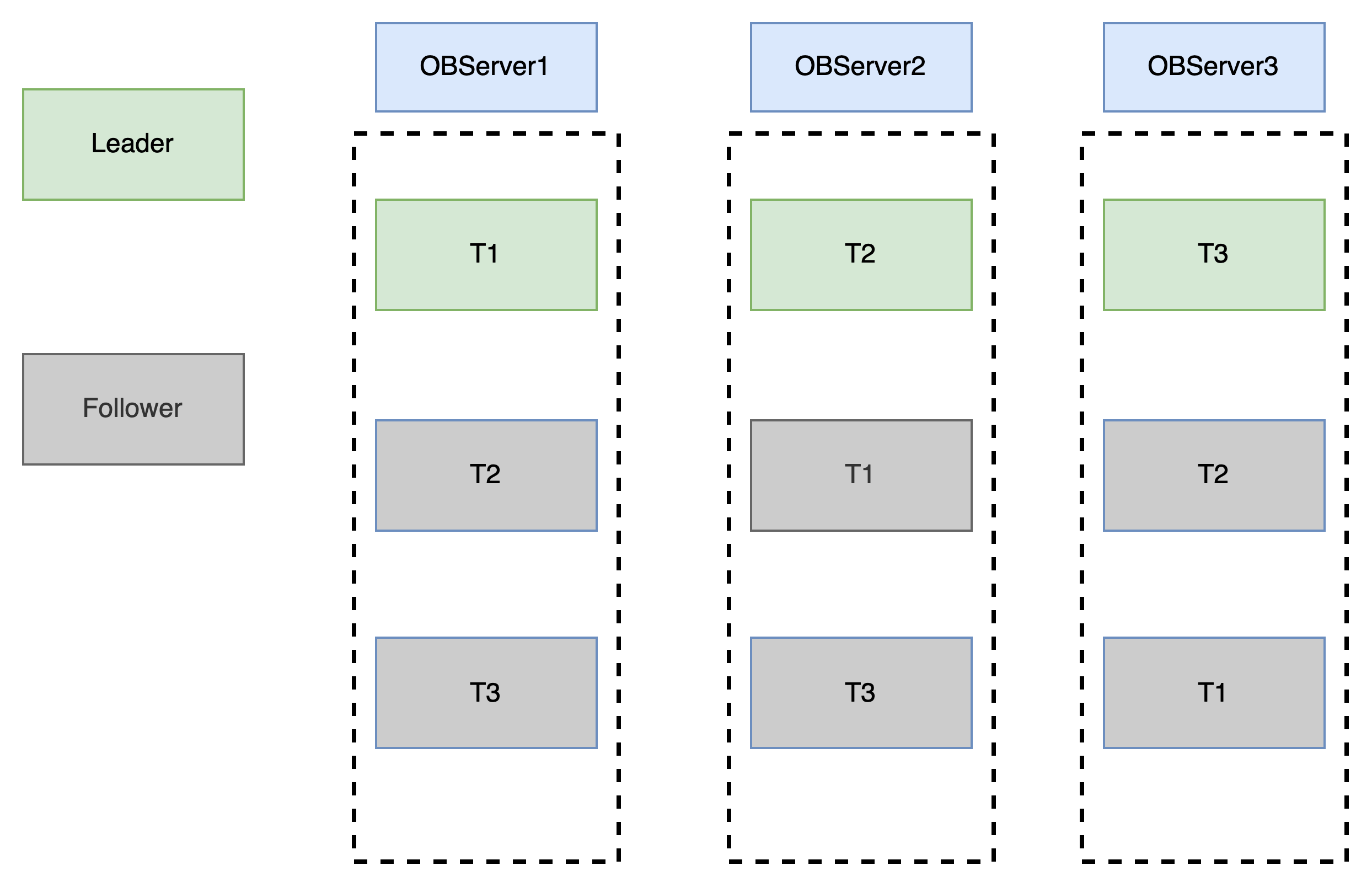
这里可以了解到OB如果的分布式性能提升有两个维度,表级别和分区级别,表级别这个维度如果所有表访问流量都很均衡会且每台机器负载都很高的情况下,有一定负载均衡效果,但如果某几张表流量很大,那可能效果就不是很明显,而且还会有远程通信的延迟。
OB中另外一个特性就是多租户,类似于Oracle中的PDB,即可在一个OBServer进程内不同的租户之间资源相互隔离,每个租户内都有自己的DataBase、Table、View等,这样在一个OBServer中运行多个应用且相互之间互不干扰,租户资源都可动态调整。
Tidb与OB存储引擎是LSM-TREE,针对写场景均为顺序写会有比较大的优势,缺点是查询可能需要扫描多个版本,但OB中有布隆过滤尽量较少这方面影响。另外就是SSTable文件的合并操作会对磁盘IO和集群有一定影响,默认情况下在凌晨2点出发合并操作,需要与跑批时间错开
Shared-Storage
这类架构灵感来自于AWS 的Aurora,采用计算存储分离架构,利用软硬件结合提供高弹性(NVME,RDMA)、高性能、高可用的数据库服务。
计算存储分离架构下,底层是分布式文件系统。为保证Partial Transaction(未提交的数据有可能从buffer pool中刷新到磁盘上,导致Secondary节点读到未提交的数据),Primary节点写入数据利用Redo同步到Secondary节点,加上利用新型硬件跨越了用户态的交互。
虽然是单写,但可满足大部分应用场景,同时具备以下优点:
- 兼容性:此架构多数的修改都是在存储引擎层,所以可以100%兼容原有数据库,应用无需改造,其它分布式架构多数都会需要做一些应用改造。
- 低成本:计算存储分离,相比以前的一主多备架构,计算资源可单独增加,无需多购买多余的存储资源。简单说:以前一主多备10T的数据库,在计算资源不够需要在增加一个备库提升读能力,此时需要购买的资源包括计算(8C)和存储(10T),但这种架构下可单独沟通一个8C的计算资源即可。
- 弹性扩展:相比主备架构扩展计算资源,不再需要通过备份恢复方式,可做到快速弹性扩展,在一些大促场景下很有用。可以想象一个3T的库备份去搭建一个从库多费时间。
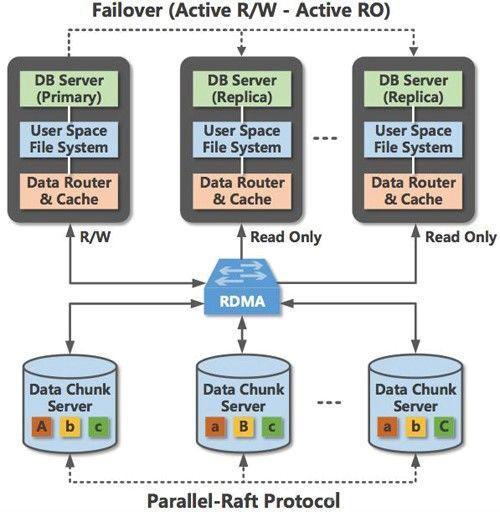
这类架构的产品通常都需要云底座,依赖于底层硬件和文件系统,各厂商代表产品:
| MySQL | PostgreSQL | |
|---|---|---|
| 腾讯 | TDSQL-C MySQL | TDSQL-C PG |
| 阿里 | PolarDB MySQL | PolarDB PG |
| 华为 | GaussDB MySQL |
总结
从国产数据库发展来看,从分库分表架构发展时间较长,技术相对成熟且一些ISV厂商已熟悉这类架构开发模式,在一些行业中各类系统已形成了解决方案。Tidb这种NewSQL可作为替代MySQL较好的一种解决方案,在某些行业中ISV开发相对比较薄弱很难做业务改造,Tidb是一个不错的选择。PolarDB则充分利用了软硬件结合,即使在单点写入情况下也可以得到很好性能,其实国产数据库当前厂商众多,如果还延续20年前的架构和存储引擎很难做到差异化,如果能抓到新硬件带来的红利,做出差异化的产品则能领先一大步,从AWS一些资料中发现软硬件结合也是AWS一直研究和探索的方向。
