




Mysql一直以来都是使用innodb的自增列功能产生表级别的唯一id序列,innodb把自增列值存储在该列所在的索引中(必然是其第一列),每次mysqld启动后首次打开这个表时候,把这个索引的最大值取出来作为自增列的起始值并且存储在内存中,然后mysqld运行期间即可维护和使用这个自增列值。
这个功能有不少缺陷,包括:
1. 每个表只能有一个自增列,并且这个自增列必须是一个索引 的第一列。同时,一个自增序列无法给多个表使用。
2. 自增列可能会成为一个性能瓶颈。当innodb_autoinc_lock_mode是0时,一个自增列会在一个插入语句执行期间被一直锁住,这样它就成为一个严重的性能瓶颈,对该表的插入是在语句级别排队执行的。后来较新的版本支持了1模式后,问题大大减轻,但是对于insert into ... Select from 这样的语句仍然有性能瓶颈。使用2的话无法保证insert into ... Select from 这样的语句在SBR复制模式下的主备数据一致。
3. 无法独立引用(refer to)一个表的自增列的当前值(last_insert_id无法指定某个表)
4. 其他存储引擎需要实现自己的自增列功能。
由于TDSQL的不少金融业用户之前使用Oracle数据库,他们希望我们支持Oracle sequence,因此,我在TDSQL的percona数据库内核中实现了Oracle sequence功能,该功能与oracle原版sequence功能完全相同,没有任何省略和遗漏。Oracle sequence的详细功能介绍在这里(https://docs.oracle.com/cd/B28359_01/server.111/b28310/views002.htm#ADMIN11792)
TDSQL sequence 完全解决了上述mysql 自增列的缺陷,sequence完全独立与表而存在,不需要作为表的索引第一列;一个表的不同字段可以使用多个sequence产生序列值;一个sequence可以给任意多个表使用产生自增序列值,也可以脱离表的insert/update语句而单独使用。所有存储引擎上面的表都可以使用sequence功能。当然,对于SBR复制模式来说,与mysql自增列一样,使用sequence仍然会导致主备数据不一致。TDSQL使用RBR复制,所以不存在这个问题。
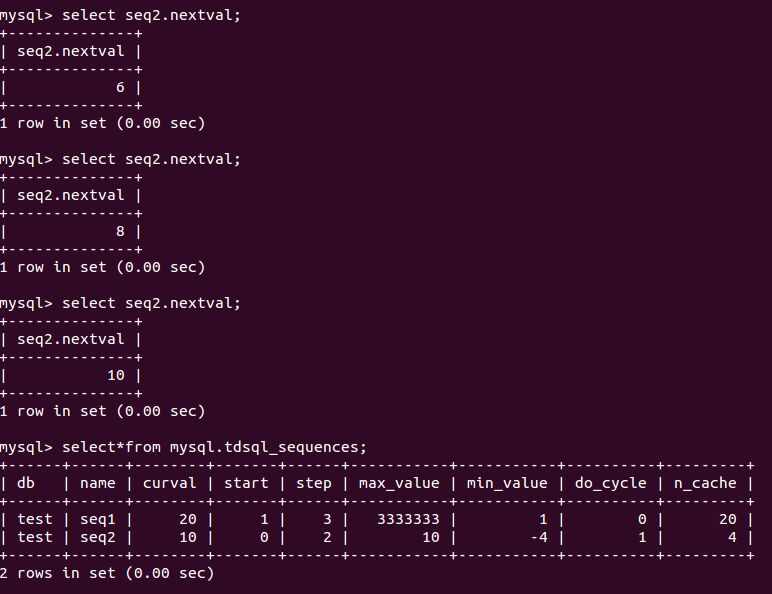
在本文文末我会介绍一下TDSQL sequence的性能,下面我先把sequence的常用功能的执行截图贴出来供读者参考。
TDSQL sequence的功能展示
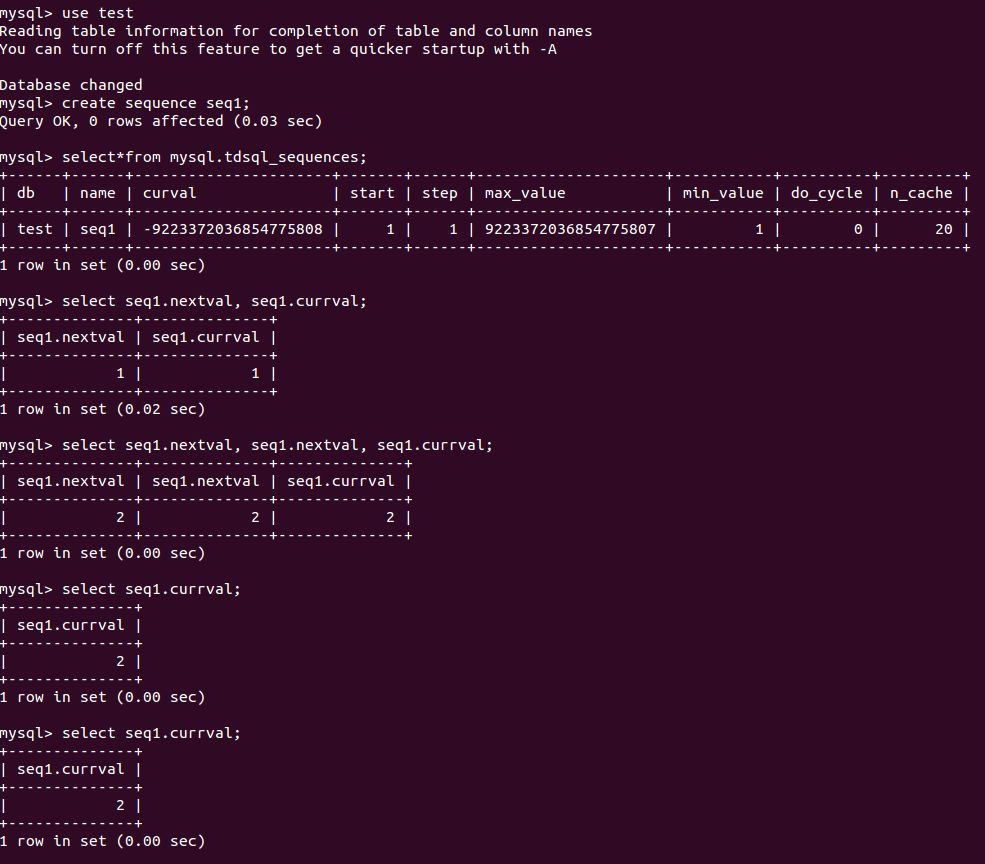
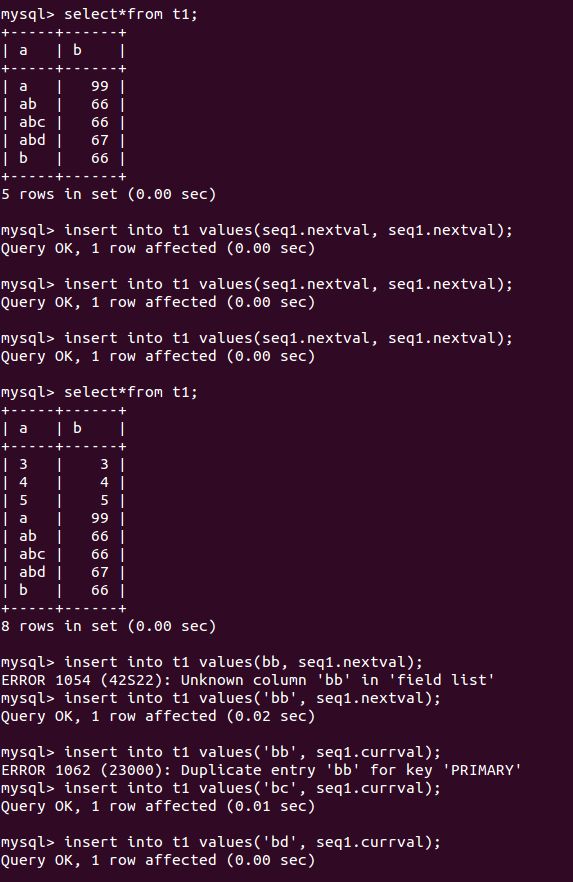
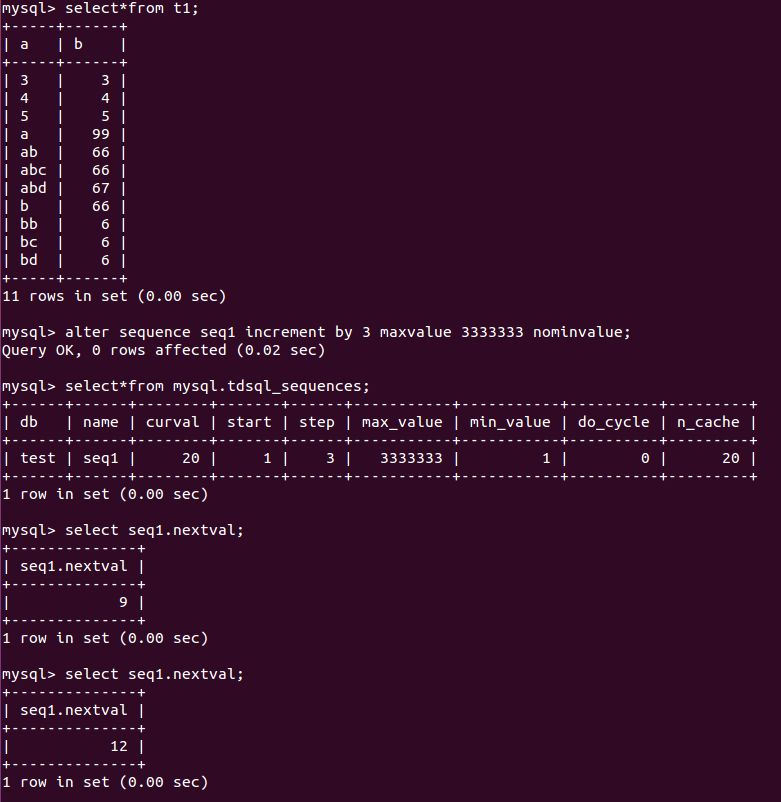
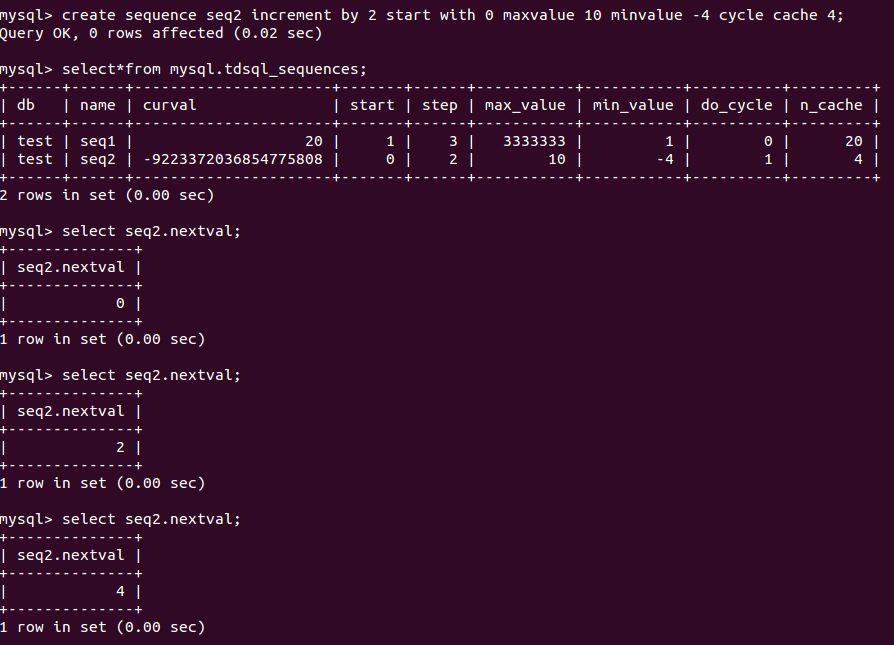
TDSQL sequence的性能
影响sequence性能的因素主要是sequence的cache数值,cache越大,每次修改mysql.tdsql_sequence表中该sequence的元数据后可以产生越多的sequence值,因而性能越好。当然,与Oracle的sequence一样,如果mysqld crash了,那么下次重启后,sequence将从mysql.tdsql_sequences表的curval字段记录的值开始增长,可能就跳过了很多个sequence值。因此,用户通常需要选择一个合适的cache值。另外,事务回滚也不会归还占用的sequence值,这也与oracle sequence相同。
这个性能测试机器使用一个48核的intel cpu,sysbench与mysqld在同一台机器运行。我预先执行create sequence mysql.seq1;创建一个sequence,然后使用sysbench,500个连接,每个连接执行下面这个简单的测试脚本如下:
-bash-4.2$ cat tests/db/select-seq.lua
pathtest = string.match(test, "(.*/)") or ""
dofile(pathtest .. "common.lua")
function thread_init(thread_id)
set_vars()
end
function event(thread_id)
rs = db_query("SELECT mysql.seq1.nextval ");
end
sysbench测试命令如下:
-bash-4.2$ cat seq.sh
./sysbench --max-time=300 --test=tests/db/select-seq.lua --mysql-host=xxx --mysql-port=xx --mysql-db=test1 --oltp_tables_count=10 --oltp-table-size=50000000 --oltp-read-only=off --init-rng=on --num-threads=500 --max-requests=0 --oltp-dist-type=uniform --mysql-user='abc' --mysql-password='abc' --oltp_auto_inc=off --report-interval=1 --db-driver=mysql $1
Cache值 | QPS | CPU idle | 95% 延时 |
20 | 40w/s | 约35% | 约2ms |
500 | 35w/s | 约30% | 约1.8ms |
2000 | 54w/s | <3% | 约1.5ms |
10000 | 60w/s | <3% | 约1.5ms |
这几个cache值设定下,sysbench期间QPS和延时都非常稳定。有趣的是500个连接时,cache值是500的qps比cache值为20还低一些,我反复试过几次都是这样。似乎发生了某种共振导致的。这个95%延时值是包含了数据包往返(sysbench与mysqld在同一个机器上面),以及线程池调度开销的,并不只是执行select seq1.nextval的耗时,也就是说如果这个seq1.nextval是一个insert语句的一部分的话,那么执行seq1.nextval这个部分的耗时是远远低于2ms的。
