




canal是阿里开源的一个同步mysql到其他存储的一个中间件,它的原理如下:首先伪装成一个mysql的slave服务器消费mysql的binlog,然后在本地根据需要提供tcp服务供下游消费,或者转发到kafka等消息队列中,供下游使用。
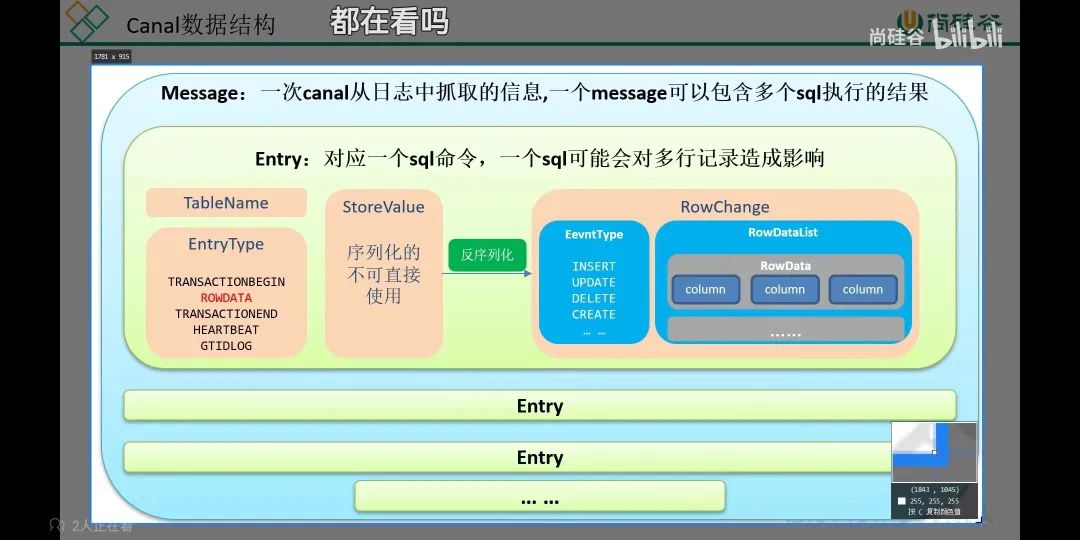
canal收到binlog后会解析成entry,一条sql 增删改命令对应一个entry,entry的内容包括表名,操作类型等信息,rowdata是具体的数据内容,由于一个更新语句可能影响多行,所以它是一个list。通过解析entry我们可以自己进行过滤,转化等操作然后存储到下游系统。本文操作的同步mysql到es的系统架构是:mysql->canal->kafka->elasticsearch.
首先搭建我们的服务,在踩了很多坑以后,我整理成了docker.compose.yml文件,方便快速启动,它和k8s的deployment很像。
version: "2"services:zookeeper:image: docker.io/bitnami/zookeeper:3.8ports:- "2181:2181"volumes:- "zookeeper_data:/bitnami"environment:- ALLOW_ANONYMOUS_LOGIN=yeskafka:image: docker.io/bitnami/kafka:3.3ports:- "9092:9092"volumes:- "kafka_data:/bitnami"environment:- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181- ALLOW_PLAINTEXT_LISTENER=yes# client 要访问的 broker 地址- KAFKA_ADVERTISED_HOST_NAME=127.0.0.1# 通过端口连接 zookeeper#- KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181# 每个容器就是一个 broker,设置其对应的 ID#- KAFKA_BROKER_ID=0# 外部网络只能获取到容器名称,在内外网络隔离情况下# 通过名称是无法成功访问 kafka 的# 因此需要通过绑定这个监听器能够让外部获取到的是 IP- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092# kafka 监听器,告诉外部连接者要通过什么协议访问指定主机名和端口开放的 Kafka 服务。- KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092# Kafka默认使用-Xmx1G -Xms1G的JVM内存配置,由于服务器小,调整下启动配置# 这个看自己的现状做调整,如果资源充足,可以不用配置这个#- KAFKA_HEAP_OPTS: "-Xmx256M -Xms128M"# 设置 kafka 日志位置#- KAFKA_LOG_DIRS: "/kafka/logs"#volumes:# - var/run/docker.sock:/var/run/docker.sock# 挂载 kafka 日志# :前面的路径是你电脑上路径 后面是kafka容器日志路径# - ~/data/docker/kafka/logs:/kafka/logsdepends_on:- zookeepermysql:image: docker.io/mysql:5.7ports:- "3306:3306"volumes:- "~/learn/canal-server/mysql/log:/var/log/mysql"- "~/learn/canal-server/mysql/data:/var/lib/mysql"- "~/learn/canal-server/mysql/conf/my.cnf:/etc/mysql/my.cnf"- "~/learn/canal-server/mysql/mysql-files:/var/lib/mysql-files"environment:- MYSQL_ROOT_PASSWORD=canalcanal-server:image: docker.io/canal/canal-serverports:- "11111:11111"volumes:- "~/learn/canal-server/instance.properties:/home/admin/canal-server/conf/example/instance.properties"- "~/learn/canal-server/canal.properties:/home/admin/canal-server/conf/canal.properties"- "~/learn/canal-server/meta.dat:/home/admin/canal-server/conf/example/meta.dat"- "~/learn/canal-server/logs/:/home/admin/canal-server/logs/"depends_on:- mysql- kafkaelasticsearch:image: docker.io/elasticsearch:7.17.6ports:- "9200:9200"- "9300:9300"volumes:- "~/learn/elasticsearch/config/config:/usr/share/elasticsearch/config"- "~/learn/elasticsearch/data/node1/:/usr/share/elasticsearch/data/"environment:- "discovery.type=single-node"- "ES_JAVA_OPTS=-Xms512m -Xmx512m"kibana:image: docker.io/kibana:7.17.6ports:- "5601:5601"depends_on:- kafka#docker run -d --name kibana --net canal -p 5601:5601 kibana:8.4.3# docker run -p 3306:3306 --name mysql --network canal -v ~/learn/canal-server/mysql/log:/var/log/mysql -v ~/learn/canal-server/mysql/data:/var/lib/mysql -v ~/learn/canal-server/mysql/conf/my.cnf:/etc/mysql/my.cnf -v ~/learn/canal-server/mysql/mysql-files:/var/lib/mysql-files -e MYSQL_ROOT_PASSWORD=canal mysql:5.7# docker run --privileged --name canal-server --network host -p 11111:11111 \# -v ~/learn/canal-server/instance.properties:/home/admin/canal-server/conf/example/instance.properties \# -v ~/learn/canal-server/canal.properties:/home/admin/canal-server/conf/canal.properties \# -v ~/learn/canal-server/meta.dat:/home/admin/canal-server/conf/example/meta.dat \# -v ~/learn/canal-server/logs/:/home/admin/canal-server/logs/ \# canal/canal-server# docker run -d --name elasticsearch --net canal -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:8.4.3volumes:zookeeper_data:driver: localkafka_data:driver: local
首先部署依赖的kafka,但是kafka依赖zookeeper,然后是es和kibana,刚开始尝试8.3.4的时候发现跑不通改为低版本了。最后部署mysql 5.7和canal最新版本,中间也尝试过mysql8.0但是支持不太完善,中间有坑。
由于我们需要修改这些中间件的配置文件,所以将这些配置文件挂载在宿主机防止重启后丢失。接着我们开始配置。首先修改mysql的binlog格式为row(row,statement,mixed),基于声明的最省空间,但是部分函数会导致主从不一致,所以改成行格式,每次dml操作会产生最多两条数据,对于插入是更新后的,删除是更新前的,修改是前后各一条。
learn/canal-server/mysql/conf/my.cnf
log-bin=mysql-bin # 开启 binlogbinlog-format=ROW # 选择 ROW 模式server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
设置账号信息
mysql> CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';Query OK, 0 rows affected (0.04 sec)mysql>grant all privileges on *.* to 'canal'@'%'IDENTIFIED BY 'canal';Query OK, 0 rows affected, 1 warning (0.02 sec)mysql>flush privileges;Query OK, 0 rows affected (0.01 sec)
重启mysql检查下
select * from mysql.user where User="canal"\G*************************** 1. row ***************************Host: %User: canalSelect_priv: YInsert_priv: YUpdate_priv: YDelete_priv: YCreate_priv: YDrop_priv: YReload_priv: YShutdown_priv: YProcess_priv: YFile_priv: YGrant_priv: NReferences_priv: YIndex_priv: YAlter_priv: YShow_db_priv: YSuper_priv: YCreate_tmp_table_priv: YLock_tables_priv: YExecute_priv: YRepl_slave_priv: YRepl_client_priv: YCreate_view_priv: YShow_view_priv: YCreate_routine_priv: YAlter_routine_priv: YCreate_user_priv: YEvent_priv: YTrigger_priv: YCreate_tablespace_priv: Yssl_type:ssl_cipher: 0xx509_issuer: 0xx509_subject: 0xmax_questions: 0max_updates: 0max_connections: 0max_user_connections: 0plugin: mysql_native_passwordauthentication_string: *E3619321C1A937C46A0D8BD1DAC39F93B27D4458password_expired: Npassword_last_changed: 2022-10-16 01:38:41password_lifetime: NULLaccount_locked: N1 row in set (0.01 sec)show variables like 'binlog_rows%';+------------------------------+-------+| Variable_name | Value |+------------------------------+-------+| binlog_rows_query_log_events | OFF |+------------------------------+-------+1 row in set (0.08 sec)
接着配置canal将serverMode改成kafka,如果我们想通过sdk访问可以使用默认的tcp
learn/canal-server/canal.properties
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQcanal.serverMode = kafk
learn/canal-server/instance.properties
canal.instance.mysql.slaveId=10canal.instance.master.address=127.0.0.1:3306canal.instance.dbUsername=canalcanal.instance.dbPassword=canal
canal.mq.topic=example
配置完毕后我们启动服务,在mysql里编辑内容就可以看到kafka已经可以消费了
mysql> insert into orders values(11,'c');Query OK, 1 row affected (0.00 sec)
% docker exec -it 19b6f42ad805 kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic example{"data":[{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"},{"id":"5","name":"b"}],"database":"test","es":1665905655000,"id":66,"isDdl":false,"mysqlType":{"id":"int(11)","name":"varchar(255)"},"old":[{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"},{"id":"4"}],"pkNames":null,"sql":"","sqlType":{"id":4,"name":12},"table":"orders","ts":1665908723520,"type":"UPDATE"}
至此完成了一半工作了,接下来就是比较熟悉的消费kafka写入es的工作
package mainimport ("encoding/json""fmt""learn/learn/elasticsearch/es""learn/learn/elasticsearch/kafka""strconv")func main() {var brokers, topics, group stringbrokers = "127.0.0.1:9092" //"docker.for.mac.host.internal:9092"topics = "example"group = "canal-es-4"consumer := kafka.NewConsumer(brokers, topics, group, true)esClient := es.NewClient(topics)go func() {for message := range consumer.GetMessages() {fmt.Println(string(message.Value))if message.Topic != topics {continue}canal := &Canal{}if err := json.Unmarshal(message.Value, &canal); err != nil {fmt.Println(err)}for _, v := range canal.Data {id, _ := strconv.ParseInt(v.ID, 10, 10)esClient.Insert(&es.Orders{Id: int64(id), Name: v.Name})}}}()consumer.Consume()}
package kafkaimport ("context""log""os""os/signal""strings""sync""syscall""github.com/Shopify/sarama")// Consumer represents a Sarama consumer group consumertype Consumer struct {ready chan boolbrokers, topics, group stringoldest boolclient sarama.ConsumerGroupmessages chan *sarama.ConsumerMessage}func NewConsumer(brokers, topics, group string, oldest bool) *Consumer {/*** Construct a new Sarama configuration.* The Kafka cluster version has to be defined before the consumer/producer is initialized.*/config := sarama.NewConfig()assignor := "roundrobin"switch assignor {case "sticky":config.Consumer.Group.Rebalance.GroupStrategies = []sarama.BalanceStrategy{sarama.BalanceStrategySticky}case "roundrobin":config.Consumer.Group.Rebalance.GroupStrategies = []sarama.BalanceStrategy{sarama.BalanceStrategyRoundRobin}case "range":config.Consumer.Group.Rebalance.GroupStrategies = []sarama.BalanceStrategy{sarama.BalanceStrategyRange}default:log.Panicf("Unrecognized consumer group partition assignor: %s", assignor)}if oldest {config.Consumer.Offsets.Initial = sarama.OffsetOldest}/*** Setup a new Sarama consumer group*/consumer := &Consumer{ready: make(chan bool),brokers: brokers,topics: topics,group: group,messages: make(chan *sarama.ConsumerMessage, 10),}client, err := sarama.NewConsumerGroup(strings.Split(brokers, ","), group, config)if err != nil {log.Panicf("Error creating consumer group client: %v", err)}consumer.client = clientreturn consumer}func (c *Consumer) GetMessages() chan *sarama.ConsumerMessage {return c.messages}func (c *Consumer) Consume() {ctx, cancel := context.WithCancel(context.Background())consumptionIsPaused := falsewg := &sync.WaitGroup{}wg.Add(1)go func() {defer wg.Done()for {// `Consume` should be called inside an infinite loop, when a// server-side rebalance happens, the consumer session will need to be// recreated to get the new claimslog.Println(strings.Split(c.topics, ","), c.brokers, c.topics)if err := c.client.Consume(ctx, strings.Split(c.topics, ","), c); err != nil {log.Panicf("Error from consumer: %v", err)}// check if context was cancelled, signaling that the consumer should stopif ctx.Err() != nil {return}c.ready = make(chan bool)}}()<-c.ready // Await till the consumer has been set uplog.Println("Sarama consumer up and running!...")sigusr1 := make(chan os.Signal, 1)signal.Notify(sigusr1, syscall.SIGUSR1)sigterm := make(chan os.Signal, 1)signal.Notify(sigterm, syscall.SIGINT, syscall.SIGTERM)keepRunning := truefor keepRunning {select {case <-ctx.Done():log.Println("terminating: context cancelled")keepRunning = falsecase <-sigterm:log.Println("terminating: via signal")keepRunning = falsecase <-sigusr1:toggleConsumptionFlow(c.client, &consumptionIsPaused)}}cancel()wg.Wait()if err := c.client.Close(); err != nil {log.Panicf("Error closing client: %v", err)}}// Cleanup is run at the end of a session, once all ConsumeClaim goroutines have exitedfunc (consumer *Consumer) Cleanup(sarama.ConsumerGroupSession) error {return nil}// Setup is run at the beginning of a new session, before ConsumeClaimfunc (consumer *Consumer) Setup(sarama.ConsumerGroupSession) error {// Mark the consumer as readyclose(consumer.ready)return nil}// ConsumeClaim must start a consumer loop of ConsumerGroupClaim's Messages().func (consumer *Consumer) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {// NOTE:// Do not move the code below to a goroutine.// The `ConsumeClaim` itself is called within a goroutine, see:// https://github.com/Shopify/sarama/blob/main/consumer_group.go#L27-L29for {select {case message := <-claim.Messages():log.Printf("Message claimed: value = %s, timestamp = %v, topic = %s", string(message.Value), message.Timestamp, message.Topic)session.MarkMessage(message, "")consumer.messages <- messagesession.Commit() //// Should return when `session.Context()` is done.// If not, will raise `ErrRebalanceInProgress` or `read tcp <ip>:<port>: i/o timeout` when kafka rebalance. see:// https://github.com/Shopify/sarama/issues/1192case <-session.Context().Done():return nil}}}func toggleConsumptionFlow(client sarama.ConsumerGroup, isPaused *bool) {if *isPaused {client.ResumeAll()log.Println("Resuming consumption")} else {client.PauseAll()log.Println("Pausing consumption")}*isPaused = !*isPaused}
然后就是写入es的逻辑
package esimport ("context""fmt""log""os""strconv"elastic "github.com/olivere/elastic/v7")type Client struct {*elastic.Clientindex string}func NewClient(index string) *Client {errorlog := log.New(os.Stdout, "APP ", log.LstdFlags)// Obtain a client. You can also provide your own HTTP client here.client, err := elastic.NewClient(elastic.SetErrorLog(errorlog), elastic.SetSniff(false))// Trace request and response details like this// client, err := elastic.NewClient(elastic.SetTraceLog(log.New(os.Stdout, "", 0)))if err != nil {// Handle errorpanic(err)}// Ping the Elasticsearch server to get e.g. the version numberinfo, code, err := client.Ping("http://127.0.0.1:9200").Do(context.Background())if err != nil {// Handle errorpanic(err)}fmt.Printf("Elasticsearch returned with code %d and version %s\n", code, info.Version.Number)// Getting the ES version number is quite common, so there's a shortcutesversion, err := client.ElasticsearchVersion("http://127.0.0.1:9200")if err != nil {// Handle errorpanic(err)}fmt.Printf("Elasticsearch version %s\n", esversion)return &Client{Client: client, index: index}}type Orders struct {Id int64 `json:"id"`Name string `json:"name"`}func (c *Client) Insert(orders *Orders) {// Use the IndexExists service to check if a specified index exists.exists, err := c.Client.IndexExists(c.index).Do(context.Background())if err != nil {// Handle errorpanic(err)}if !exists {// Create a new index.mapping := `{"settings":{"number_of_shards":1,"number_of_replicas":0},"mappings":{"properties":{"id":{"type":"integer"},"name":{"type":"text","store": true,"fielddata": true}}}}`createIndex, err := c.Client.CreateIndex(c.index).Body(mapping).Do(context.Background())if err != nil {// Handle errorpanic(err)}if !createIndex.Acknowledged {// Not acknowledged}}// Index a tweet (using JSON serialization)//tweet1 := Orders{User: "olivere", Message: "Take Five", Retweets: 0}put1, err := c.Client.Index().Index(c.index).Id(strconv.FormatInt(orders.Id, 10)).BodyJson(orders).Do(context.Background())if err != nil {// Handle errorpanic(err)}}
至此我们完成了简单的mysql同步到es的部署。


