




首先了解四个基本概念:
文档(document):索引与搜索的主要数据载体,它包含一个或多个字段,存放将要写入索引或将从索引搜索出来的数据。
字段(field):文档的一个片段,它包括两个部分:字段的名称和内容。
词项(term):搜索时的一个单位,代表文本中的某个词。
词条( token):词项在字段中的一次出现,包括词项的文本、开始和结束的位移以及类型。
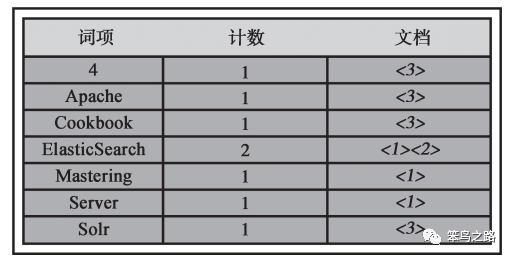
Apache Lucene 将写入索引的所有信息组织成一种名为倒排索引( inverted index)的结构。该结构是一种将词项映射到文档的数据结构,其工作方式与传统的关系数据库不同,你大可以认为倒排索引是面向词项而不是面向文档的。接下来我们看看简单的倒排索引是什么样的。例如,我们有一些只包含 title 字段的文档,如下所示:
ElasticSearch Server(文档 1)
EasteringElasticSearch(文档 2)
Apache solr 4 Cookbook(文档 3)
而索引后的结构示意图如下所示。
可用于搜索的词项的?这个转换过程称为分析(analysis)。
小写过滤器:
将所有词条转化成小写。
ASCII过滤器:
移除词条中所有非ASCII字符。
同义词过滤器:根据同义词规则,将一个词条转化为另一个词条。
多语言词干还原过滤器:将词条的文本部分归约到它们的词根形式,即词干还原。
在索引期, Lucene 会使用你选择的分析器来处理文档中的内容,并可以对不同的字段使用不同的分析器,例如,
ElasticSearch 提供的一些查询类型( query type)支持 Apache Lucene 的查询解析语法,因此,我们应该深入了解 Lucene 的查询语言并加以描述。
在 Lucene 中,一个查询通常被分割为词项与操作符。Lucene 中的词项可以是单个词,也可以是一个短语(用双引号括起来的一组词)。如果设置了查询分析过程,那么预先选定的分析器将会对查询中的所有词项进行处理。
查询中也可以包含布尔操作符,用于连接多个词项,使之构成从句( clause)。有以下这些布尔操作符:
AND :它的含义是,文档匹配当前从句当且仅当 AND 操作符左右两边的词项都在文档中出现。例如,执行 apache AND lucene 这样的查询,只有同时包含 apache 和Lucene 这两个词项的文档才会返回给用户。 OR :它的含义是,包含当前从句中任意词项的文档都会被视为与该从句匹配。例如,执行 apache OR lucene 这样的查询,任意包含词项 apache 或词项 lucene 的文档都会返回给用户。 NOT :它的含义是,与当前从句匹配的文档必须不包含 NOT 操作符后面的词项。例如,执行 lucene NOT elasticsearch 这样的查询,只有包含词项 lucene 且不包含词项 elasticsearch 的文档才会返回给用户。
+ :它的含义是,只有包含 + 操作符后面词项的文档才会被认为是与从句匹配。例如,查找那些必须包含 lucene,但是 apache 可出现可不出现的文档,可执行查询:
+lucene apache。- :它的含义是,与从句匹配的文档不能出现 - 操作符后的词项。例如,查找那些包含 lucene 但不包含 elasticsearch 的文档,可以执行查询:+lucene-elasticsearch。如果查询中没有出现前面提到过的任意操作符,那么默认使用 OR 操作符。
另外,你还可以使用圆括号对从句进行分组,以构造更复杂的从句,例如:
elasticsearch AND (mastering OR book) 。
本章小结:
Apache Lucene 是什么。
Lucene 的整体架构。
文本分析过程是如何实现的。
Apache Lucene 的查询语言。
