




提示:公众号展示代码会自动折行,建议横屏阅读
背景
客户发现一个非预期内的锁等待现象,线上频繁出现锁告警,出现问题的case可以简化成以下SQL:
# 表结构和表数据CREATE TABLE `tab1` (`id` bigint unsigned NOT NULL AUTO_INCREMENT,`value` int NOT NULL,`status` tinyint unsigned NOT NULL DEFAULT '1',PRIMARY KEY (`id`),KEY `idx_value` (`value`));insert into tab1 (value) values (5);insert into tab1 (value) values (10);#seesion 1:begin;update `tab1` set `status` = 3 where (`value` = 10);#session 2:update `tab1` set `status` = 3 where (`value` >= 4) and (`value` < 6); #阻塞
用户贼郁闷,隔离级别用的是 RC,两个session又都只更新一条数据,并且更新的还是两条不一样的数据,按理来说没有冲突,不应该造成阻塞。
原因分析
原始的场景中,用户的二级索引是建立在datetime类型上的,一开始怀疑是datetime类型在InnoDB层的比较出现了问题。
但是后面在int类型的二级索引上复现了该问题,因此可以排除是datetime类型导致的。
使用select * from performance_schema.data_lock_waits; 查看session 2等待的锁信息:

可以看到,session 2等待的锁是在idx_value这个索引的<10, 2>这条记录上,而这条记录正是被session 1持有的。
根据以上线索,透露出来的信息是,session 2尝试去加了session 1锁住的记录<10, 2>的锁,也就是说(`value` < 6)这个条件并没有在innodb层过滤掉<10, 2>这条记录。
通过分析源码,这个流程可以简化成:
Server层调用read_range_next()会循环调用innodb层的row_search_mvcc函数,在row_search_mvcc函数中执行以下步骤:
1. btr_pcur_open_with_no_init mode = page_cur_ge,如果是第一次调用,找到第一条>= start_range的记录,如果不是第一次调用,找到pcur->next_rec
2. sel_set_rec_lock 对pcur指向的rec记录加锁,如果加锁失败,返回等待。
3. row_search_idx_cond_check 检查rec记录是否满足index condition。
ICP_RESULT row_search_idx_cond_check(byte *mysql_rec, *!< out: recordin MySQL format (invalid unlessprebuilt->idx_cond == true andwe return ICP_MATCH) */row_prebuilt_t *prebuilt, *!< in/out: prebuilt structfor the table handle */const rec_t *rec, *!< in: InnoDB record */const ulint *offsets) *!< in: rec_get_offsets() */{ICP_RESULT result;ulint i;ut_ad(rec_offs_validate(rec, prebuilt->index, offsets));if (!prebuilt->idx_cond) { 如果index condition pushdown了,prebuilt->idx_cond为true,这里end_range并没有下推,所以这里直接返回了return (ICP_MATCH);}MONITOR_INC(MONITOR_ICP_ATTEMPTS);* Convert to MySQL format those fields that are needed forevaluating the index condition. */if (prebuilt->blob_heap != nullptr) {mem_heap_empty(prebuilt->blob_heap);}for (i = 0; i < prebuilt->idx_cond_n_cols; i++) {const mysql_row_templ_t *templ = &prebuilt->mysql_template[i];* Skip virtual columns */if (templ->is_virtual) {continue;}if (!row_sel_store_mysql_field(mysql_rec, prebuilt, rec, prebuilt->index, prebuilt->index, offsets,templ->icp_rec_field_no, templ, ULINT_UNDEFINED, nullptr,prebuilt->blob_heap)) {return (ICP_NO_MATCH);}}* We assume that the index conditions oncase-insensitive columns are case-insensitive. Thecase of such columns may be wrong in a secondaryindex, if the case of the column has been updated inthe past, or a record has been deleted and a recordinserted in a different case. */result = innobase_index_cond(prebuilt->m_mysql_handler); 通过该函数去判断记录是否满足下推条件switch (result) {case ICP_MATCH:* Convert the remaining fields to MySQL format.If this is a secondary index record, we must deferthis until we have fetched the clustered index record. */if (!prebuilt->need_to_access_clustered ||prebuilt->index->is_clustered()) {if (!row_sel_store_mysql_rec(mysql_rec, prebuilt, rec, nullptr, FALSE,prebuilt->index, prebuilt->index, offsets,false, nullptr, prebuilt->blob_heap)) {ut_ad(prebuilt->index->is_clustered());return (ICP_NO_MATCH);}}MONITOR_INC(MONITOR_ICP_MATCH);return (result);case ICP_NO_MATCH:MONITOR_INC(MONITOR_ICP_NO_MATCH);return (result);case ICP_OUT_OF_RANGE:MONITOR_INC(MONITOR_ICP_OUT_OF_RANGE);const auto record_buffer = row_sel_get_record_buffer(prebuilt);if (record_buffer) {record_buffer->set_out_of_range(true);}return (result);}ut_error;return (result);}
4. 返回server层该条记录
在server层read_range_next函数中,如果判断刚刚从innodb读上来的记录不在end_range之内,会调用unlock_row()接口放掉刚刚在innodb层加上的锁。
if (compare_key(end_range) > 0) {/*The last read row does not fall in the range. So requeststorage engine to release row lock if possible.*/unlock_row(); // 这里最终会调用row_unlock_for_mysql函数放掉刚刚在 sel_set_rec_lock 加上的锁。result = HA_ERR_END_OF_FILE;}
因此,session 2需要从innodb层读取两条记录去server层做判断--5和10。10恰巧又被session 1锁住,因此在innodb层读取记录的时候就判断需要锁等待,此时还没有返回到server层做end_range的范围过滤。
如果5和10之间有一条其他的记录,session 2不会被session 1持有的10上面的锁阻塞住。
总结
这个问题的本质原因,是end_range条件没有push down,如果end_range 下推到innodb层,会在row_search_mvcc函数中sel_set_rec_lock之后通过row_search_idx_cond_check函数检查是否满足end_range,这样就不会多加锁了。
追问:如果是主键索引,会是同样的表现吗?
先说结论,这里分两种情况:
如果是select for update主键索引,表现与二级索引一致,session 2是会发生阻塞的。
如果是update主键索引,session2 不会发生阻塞。
以下是对应的case:
select for update
# 表结构和表数据CREATE TABLE `tab1` (`id` bigint unsigned NOT NULL,`value` int NOT NULL DEFAULT 0,`status` tinyint unsigned NOT NULL DEFAULT '1',PRIMARY KEY (`id`));insert into tab1 (id) values (5);insert into tab1 (id) values (10);#seesion 1:begin;select * from `tab1` where (`id` = 10) for update;#session 2:select * from `tab1` where (`id` >= 4) and (`id` < 6) for update; #阻塞
update
# 表结构和表数据CREATE TABLE `tab1` (`id` bigint unsigned NOT NULL,`value` int NOT NULL DEFAULT 0,`status` tinyint unsigned NOT NULL DEFAULT '1',PRIMARY KEY (`id`));insert into tab1 (id) values (5);insert into tab1 (id) values (10);#seesion 1:begin;update `tab1` set `status` = 3 where (`id` = 10);#session 2:update `tab1` set `status` = 3 where (`id` >= 4) and (`id` < 6); #不会阻塞
代码分析
如果是select for update主键索引, prebuilt->row_read_type=ROW_READ_WITH_LOCKS,在innodb层的row_search_mvcc函数中,发生锁等待的时候,由于prebuilt→row_read_type != ROW_READ_TRY_SEMI_CONSISTENT,会和secondary index一样走lock_wait_or_error进行等待(下图第一个红框内的代码)。
如果是update主键索引,prebuilt→row_read_type=ROW_READ_TRY_SEMI_CONSISTENT,如果在innodb层发生锁等待,会先放掉锁(下图第二个红框),并将prebuilt->row_read_type设置为ROW_READ_DID_SEMI_CONSISTENT。后续在server层判断不满足end_range直接结束,但是如果后续在server层判断满足end_range,则会重新发起一次读操作,此时会读取行的最新版本,再次走到下图的代码时会走lock_wait_or_error进行锁等待(下图第一个红框)。
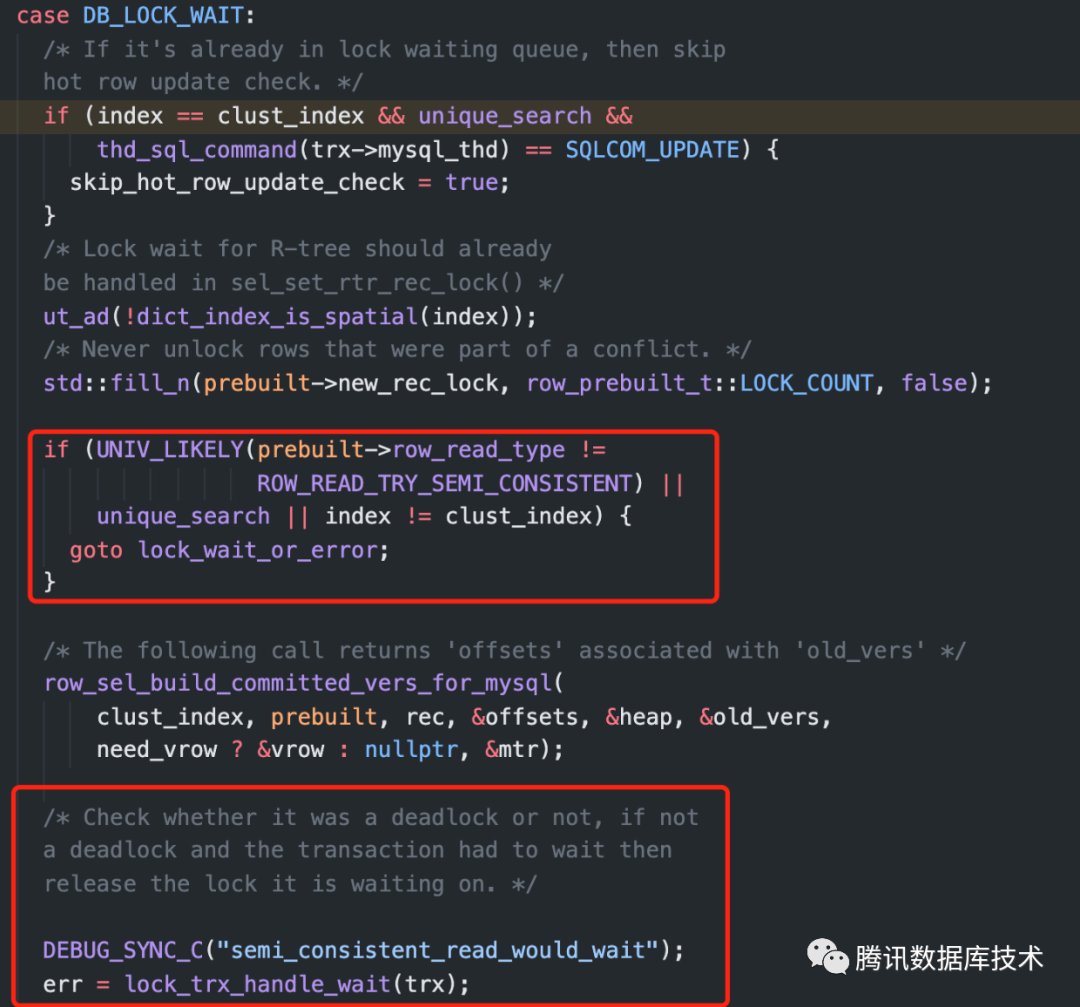
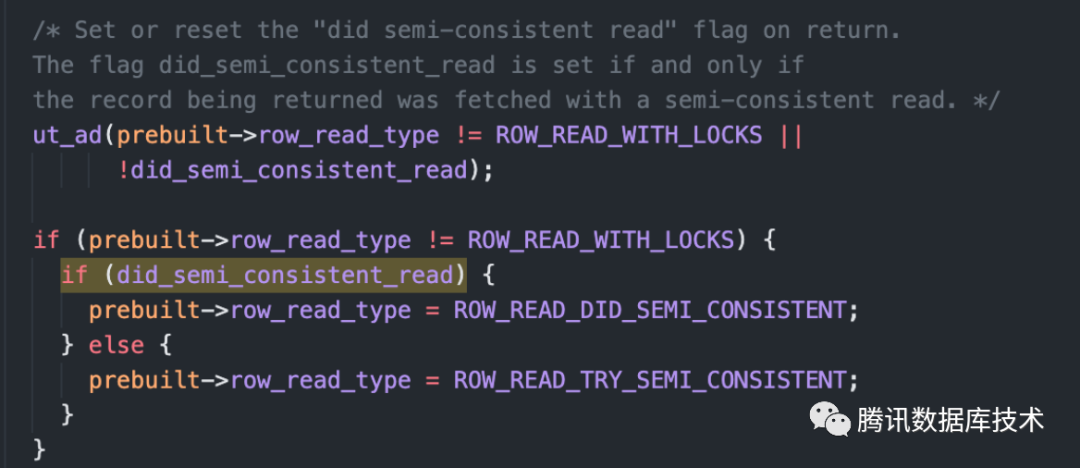
因此,如果是主键索引,select for update还是会多锁记录,但是update语句不会,这是因为它们的row_read_type不同导致的差异。
这个设计就是我们经常听说的MySQL的semi-consistent特性,这个特性的作用是:减少更新同一行记录时的锁冲突,减少锁等待。
具体流程如下,如果一条记录在InnoDB层加锁需要等待,则判断是否可以进行semi-consistent read
判断条件为:
1. prebuilt->row_read_type必须设置为ROW_READ_TRY_SEMI_CONSISTENT
2. 当前scan必须是range scan或者是全表扫描,而非unique scan
3. 当前索引必须是聚簇索引
4. 不满足以上三个条件,就不能进行semi-consistent read,进行加锁等待
如果满足上述条件,根据记录的当前版本,构造最新的commit版本,并且在InnoDB层提前释放锁。
注意:若不需要加锁等待,那么也不需要进行semi-consistent read,直接读取记录的最新版本即可,没有加锁等待的开销。
semi-consistent总结
无并发冲突,读取最新版本的数据并加锁;
有并发冲突,读取最新的commit版本,去MySQL server层判断是否满足更新条件;
如果满足条件,读取最新版本并加锁等待。
对于不满足更新条件的记录,可以提前放锁,减少并发冲突的概率。
思考:semi-consistent为什么不对二级索引做相同的优化呢?
从上述的流程可以得知,对于主键索引,如果需要加锁等待,会根据当前记录构建该记录最新的commit版本(row_sel_build_committed_vers_for_mysql)。
这主要是根据主键索引记录上隐藏存储的DB_TRX_ID和DB_ROLL_PTR列实现的。主键索引在page上原地更新数据,并构建undo log存储数据的旧版本,然后将undo log的指针存储在主键索引的DB_ROLL_PTR中。
因此,通过当前记录很容易就能找到其最新的commit版本。
然而,InnoDB MVCC对二级索引的存储跟主键索引是不同的,一个二级索引列被更新的时候,旧的二级索引记录被标记为删除,同时插入一个新的二级索引记录。也就是说,二级索引记录中不会额外存储DB_TRX_ID和DB_ROLL_PTR列。
如果我们想构造二级索引的一个可见版本,只能通过一行一行扫描二级索引记录,然后回表去判断这条二级索引是否可见,而无法直接根据当前的二级索引记录去构造其可见的commit版本。
而扫描和回表的代价是比较高的,相比于semi-consistent带来的优化可能得不偿失,因此这里对二级索引不做semi-consistent优化。
总结
该问题不能算是MySQL的bug,算是MySQL的feature,由于index condition没有下推,并且semi_consistent的特性综合导致的现象。结果来看,也并不会导致数据错误,只是”尝试“多锁了一些记录,本着宁可错锁,不能漏锁的原则,这样的feature可以接受。

腾讯数据库研发部数据库技术团队对内支持微信支付、微信红包、腾讯广告、腾讯音乐等公司自研业务,对外在腾讯云上支持 TencentDB 相关产品,如 CynosDB、CDB、TDSQL等。本公众号旨在推广和分享数据库领域专业知识,与广大数据库技术爱好者共同成长。
