




Mysql 实时同步 Greenplum 架构采用:Canal + Kafka + ClientAdapter
一、架构图
Canal + Kafka + ClientAdapter 架构图:

Canal是阿里开源的一个的组件。其主要用途是基于MySQL数据库增量日志解析,提供增量数据订阅和消费,工作原理相对比较简单:
- Canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议。
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 Canal )。
- Canal 解析 binary log 对象(原始字节流)。
二、Canal服务器构成模块
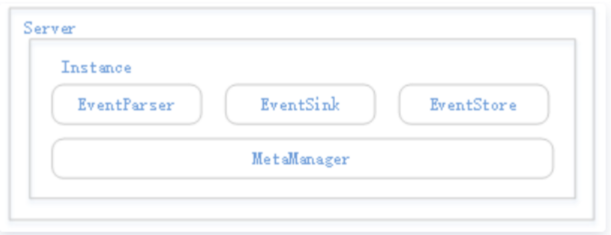
Server代表一个Canal运行实例,对应于一个jvm。Instance对应于一个数据队列,1个Server对应1…n个Instance。Instance模块中,EventParser完成数据源接入,模拟slave与master进行交互并解析协议。EventSink是Parser和Store的连接器,进行数据过滤、加工与分发。EventStore负责存储数据。MetaManager是增量订阅与消费信息管理器。
三、部署
3.1、环境:
- 192.168.5.136 : Mysql 版本: 5.7.26-29 安装忽略
- 192.168.5.74: Greenplum : greenplum-db-6.20.5 安装忽略
- 192.168.5.156 :Canal Server : canal.deployer-1.1.3.tar.gz
- 192.168.5.156 :Canal Adapter :canal.adapter-1.1.3.tar.gz
- 192.168.5.156 :Kafka : kafka_2.13-2.6.0.tgz
- 192.168.5.156 : java -version : “1.8.0_352”
资源下载:
canal.deployer-1.1.3.tar.gz
canal.adapter-1.1.3.tar.gz
kafka_2.13-2.6.0.tgz
3.2、数据源Mysql与目标库Greenplum配置
数据源也必须开启了binlog并设置为主库才行。
3.2.1、mysql binlog参数配置应该如下:
vim /etc/my.cnf
# 加入下面三行
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1
-- 验证
mysql> select @@server_id;
+-------------+
| @@server_id |
+-------------+
| 1 |
+-------------+
1 row in set (0.00 sec)
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set (0.01 sec)
mysql> show variables like 'binlog_format';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
3.2.2 创建用户:
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
3.2.3. 创建数据库pydb,测试表:T1
CREATE DATABASE pydb;
use pydb;
create table t1(id int, name varchar(10));
3.2.3 目标端:Greenplum 配置用户
CREATE database two_dw;
CREATE USER two WITH PASSWORD 'two';
GRANT create,update,delete ON two TO two_dw;
ALTER USER two SET search_path to two_dw;
3.2.4 目标表:
CREATE TABLE t1 (
id numeric,
name varchar
)with (appendonly = true, compresstype = zlib, compresslevel = 5,orientation=column)
Distributed by (id)
3.3 Kafka 安装配置
3.3.1 解压
tar -zxvf kafka_2.13-2.6.0.tgz -C /usr/local/
3.3.2. zookeeper配置与启动
kafka启动需要zookeeper,无需额外下载,下载包自带有
[root@CanalKafka156 kafka_2.13-2.6.0]# mkdir zookeeper_data
[root@CanalKafka156 kafka_2.13-2.6.0]# mkdir zookeeper_logs
[root@CanalKafka156 config]# pwd
/usr/local/kafka_2.13-2.6.0/config
[root@CanalKafka156 config]# vim zookeeper.properties
#指定数据目录
dataDir=/usr/local/kafka_2.13-2.6.0/zookeeper_data
#指定日志目录
dataLogDir=/usr/local/kafka_2.13-2.6.0/zookeeper_logs
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
#session的会话时间 以ms为单位
tickTime=2000
#服务器启动以后,master和slave通讯的时间
#initLimit=10
#master和slave之间的心跳检测时间,检测slave是否存活
#syncLimit=5
3.3.3.启动命令:
[root@CanalKafka156 bin]# sh zookeeper-server-start.sh -daemon ../config/zookeeper.properties
-daemon 后台运行
-- 查看端口:2181
[root@CanalKafka156 zookeeper_data]# netstat -napl | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 1108/java
[root@CanalKafka156 kafka_2.13-2.6.0]# mkdir kafka-logs
[root@CanalKafka156 config]# pwd
/usr/local/kafka_2.13-2.6.0/config
[root@CanalKafka156 config]# vim server.properties
#将Broker的Listener信息发布到Zookeeper中
#一定是主机名,小写,
#否则报:Error while fetching metadata with correlation id : {LEADER_NOT_AVAILABLE}
listeners=PLAINTEXT://canalkafka156:9092
advertised.listeners=PLAINTEXT://canalkafka156:9092
log.dirs=/usr/local/kafka_2.13-2.6.0/kafka-logs
zookeeper.connect=canalkafka156:2181
3.3.5 kafka服务启动
[root@CanalKafka156 bin]# sh kafka-server-start.sh -daemon ../config/server.properties
[root@CanalKafka156 bin]# netstat -napl | grep 9092
tcp6 0 0 192.168.5.156:9092 :::* LISTEN 1951/java
tcp6 0 0 192.168.5.156:40742 192.168.5.156:9092 ESTABLISHED 1951/java
tcp6 0 0 192.168.5.156:9092 192.168.5.156:40742 ESTABLISHED 1951/java
3.3.6 kafka服务验证
-- 创建topics:test
[root@CanalKafka156 bin]# sh kafka-topics.sh --create --zookeeper CanalKafka156:2181 --replication-factor 1 --partitions 1 --topic test
Created topic test.
-- 查看
[root@CanalKafka156 bin]# sh kafka-topics.sh --list --zookeeper CanalKafka156:2181
test
-- 发送消息:test 12345
[root@CanalKafka156 bin]# sh kafka-console-producer.sh --broker-list CanalKafka156:9092 --topic test
>test 12345
-- 接收消息:
[root@CanalKafka156 bin]# sh kafka-console-consumer.sh --bootstrap-server CanalKafka156:9092 --topic test --from-beginning
test 12345
-- 删除topics:test
[root@CanalKafka156 bin]# sh kafka-topics.sh --delete --zookeeper CanalKafka156:2181 --topic test
Topic test is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
-- 查看
[root@CanalKafka156 bin]# sh kafka-topics.sh --list --zookeeper CanalKafka156:2181
__consumer_offsets
3.4 Canal Server安装配置
3.4.1 解压
su - root
--创建目录:
mkdir -p /usr/local/canal-1.1.3/deployer
tar -zxvf canal.deployer-1.1.3.tar.gz -C /usr/local/canal-1.1.3/deployer
3.4.2 修改配置文件
- (1)编辑Canal配置文件修改以下配置项。
[root@CanalKafka156 conf]# pwd
/usr/local/canal-1.1.3/deployer/conf
[root@CanalKafka156 conf]# vim canal.properties
#每个canal server实例的唯一标识
canal.id = 0
# Canal服务器模式
canal.serverMode = kafka
canal.instance.filter.druid.ddl = true
canal.instance.filter.query.dcl = true
canal.instance.filter.query.dml = true
canal.instance.filter.query.ddl = true
# Kafka服务器地址
canal.mq.servers = 192.168.5.156:9092
#数据传输:json格式
canal.mq.flatMessage = true
(2)编辑instance配置文件
vim /usr/local/canal-1.1.3/deployer/conf/example/instance.properties
# Canal实例对应的MySQL master
canal.instance.master.address=192.168.5.136:3306
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
-- 同步:pydb.t1
canal.instance.filter.regex=pydb\\.t1
# 注释canal.mq.partition配置项
# canal.mq.partition=0
# Kafka topic分区数
canal.mq.partitionsNum=3
# 哈希分区规则,指定所有正则匹配的表对应的哈希字段为表主键
#canal.mq.partitionHash=
3.4.3 启动Canal Server
执行下面的命令启动Canal Server:
[root@CanalKafka156 bin]# pwd
/usr/local/canal-1.1.3/deployer/bin
[root@CanalKafka156 bin]# sh startup.sh
Canal Server成功启动后,将在日志文件中看到类似下面的信息:
tail -f /usr/local/canal-1.1.3/deployer/logs/canal/canal.log
2022-10-28 17:19:21.866 [main] INFO com.alibaba.otter.canal.deployer.CanalStater - ## start the canal server.
2022-10-28 17:19:21.891 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[192.168.5.156:11111]
2022-10-28 17:19:22.435 [main] WARN o.s.beans.GenericTypeAwarePropertyDescriptor - Invalid JavaBean property 'connectionCharset' being accessed! Ambiguous write methods found next to actually used [public void com.alibaba.otter.canal.parse.inbound.mysql.AbstractMysqlEventParser.setConnectionCharset(java.nio.charset.Charset)]: [public void com.alibaba.otter.canal.parse.inbound.mysql.AbstractMysqlEventParser.setConnectionCharset(java.lang.String)]
2022-10-28 17:19:22.626 [main] ERROR com.alibaba.druid.pool.DruidDataSource - testWhileIdle is true, validationQuery not set
2022-10-28 17:19:22.875 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^pydb\.t1$
2022-10-28 17:19:22.875 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter :
2022-10-28 17:19:23.014 [destination = example , address = /192.168.5.136:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2022-10-28 17:19:23.217 [main] ERROR com.alibaba.druid.pool.DruidDataSource - testWhileIdle is true, validationQuery not set
2022-10-28 17:19:23.235 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2022-10-28 17:19:23.235 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter :
2022-10-28 17:19:23.238 [main] INFO com.alibaba.otter.canal.deployer.CanalStater - ## the canal server is running now ......
2022-10-28 17:19:23.240 [destination = metrics , address = null , EventParser] ERROR c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - parse events has an error
com.alibaba.otter.canal.parse.exception.CanalParseException: illegal connection is null
2022-10-28 17:19:23.251 [canal-instance-scan-0] INFO c.a.o.canal.deployer.monitor.SpringInstanceConfigMonitor - auto notify stop metrics successful.
2022-10-28 17:19:28.107 [destination = example , address = /192.168.5.136:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position just last position
{"identity":{"slaveId":-1,"sourceAddress":{"address":"192.168.5.136","port":3306}},"postion":{"gtid":"","included":false,"journalName":"mysql-bin.000003","position":8964,"serverId":1,"timestamp":1666873342000}}
2022-10-28 17:19:28.579 [destination = example , address = /192.168.5.136:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000003,position=8964,serverId=1,gtid=,timestamp=1666873342000] cost : 5555ms , the next step is binlog dump
从MySQL可以看到canal用户创建的dump线程:
mysql> show processlist;
+-----+-------+-------------------+------+-------------+------+---------------------------------------------------------------+------------------+-----------+---------------+
| Id | User | Host | db | Command | Time | State | Info | Rows_sent | Rows_examined |
+-----+-------+-------------------+------+-------------+------+---------------------------------------------------------------+------------------+-----------+---------------+
| 346 | canal | 192.168.5.156:39666 | NULL | Sleep | 282 | | NULL | 0 | 1134 |
| 348 | canal | 192.168.5.156:39670 | NULL | Binlog Dump | 276 | Master has sent all binlog to slave; waiting for more updates | NULL | 0 | 0 |
| 349 | root | localhost | NULL | Query | 0 | starting | show processlist | 0 | 0 |
+-----+-------+-------------------+------+-------------+------+---------------------------------------------------------------+------------------+-----------+---------------+
3 rows in set (0.00 sec)
验证kafka 消息:
[root@CanalKafka156 bin]# sh kafka-console-consumer.sh --bootstrap-server CanalKafka156:9092 --topic example --from-beginning
{"data":[{"id":"2","name":"aaa"}],"database":"pydb","es":1666873342000,"id":1,"isDdl":false,"mysqlType":{"id":"int(11)","name":"varchar(100)"},"old":null,"pkNames":["id"],"sql":"","sqlType":{"id":4,"name":12},"table":"t1","ts":1666948066300,"type":"INSERT"}
3.5 Canal Adapter安装配置
3.5.1 解压
mkdir -p /usr/local/canal-1.1.3/adapter
tar -zxvf canal.adapter-1.1.3.tar.gz -C /usr/local/canal-1.1.3/adapter
3.5.2 修改配置文件
- (1)编辑启动器配置文件
[root@CanalKafka156 conf]# pwd
/usr/local/canal-1.1.3/adapter/conf
[root@CanalKafka156 conf]# vim application.yml
server:
port: 8081 # REST 端口号
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: kafka # canal client的模式: tcp kafka rocketMQ
canalServerHost: 192.168.5.156:11111 # 对应单机模式下的canal server的ip:port
mqServers: 192.168.5.156:9092 # kafka或rocketMQ地址
batchSize: 5000 # 每次获取数据的批大小, 单位为K
syncBatchSize: 10000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
accessKey:
secretKey:
canalAdapters: # 适配器列表
- instance: example # canal 实例名或者 MQ topic 名
groups: # 消费分组列表
- groupId: g1 # 分组id,如果是MQ模式将用到该值
outerAdapters: # 分组内适配器列表
- name: logger # 日志适配器
- name: rdb # 指定为rdb类型同步
key: Greenplum # 适配器唯一标识,与表映射配置中outerAdapterKey对应
properties: # 目标库jdbc相关参数
jdbc.driverClassName: org.postgresql.Driver # jdbc驱动名,部分jdbc的jar包需要自行放致lib目录下
jdbc.url: jdbc:postgresql://192.168.5.74:5432/two_dw # jdbc url
jdbc.username: two # jdbc username
jdbc.password: two # jdbc password
threads: 10 # 并行执行的线程数, 默认为1
commitSize: 30000 # 批次提交的最大行数
- (2)编辑RDB表映射文件,内容如下。
vim /usr/local/canal-1.1.3/adapter/conf/rdb/t1.yml
dataSourceKey: defaultDS # 源数据源的key
destination: example # cannal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId,只会同步对应groupId的数据
outerAdapterKey: Greenplum # adapter key, 对应上面配置outAdapters中的key
concurrent: true # 是否按主键hash并行同步,并行同步的表必须保证主键不会更改,及不存在依赖该主键的其他同步表上的外键约束。
dbMapping:
database: pydb # 源数据源的database/shcema
table: t1 # 源数据源表名
targetTable: public.t1 # 目标数据源的模式名.表名
targetPk: # 主键映射
id: id # 如果是复合主键可以换行映射多个
# mapAll: true # 是否整表映射,要求源表和目标表字段名一模一样。如果targetColumns也配置了映射,则以targetColumns配置为准。
targetColumns: # 字段映射,格式: 目标表字段: 源表字段,如果字段名一样源表字段名可不填。
id: id
name:name
commitBatch: 30000 # 批量提交的大小
RDB adapter 用于适配MySQL到关系型数据库(需支持jdbc)的数据同步及导入。
3.启动Canal Adapter
执行下面的命令启动Canal Adapter:
[root@CanalKafka156 bin]# pwd
/usr/local/canal-1.1.3/adapter/bin
[root@CanalKafka156 bin]# sh startup.sh
- Canal Adapter成功启动后,将在日志文件中看到类似下面的信息:
[root@CanalKafka156 adapter]# pwd
/usr/local/canal-1.1.3/adapter/logs/adapter
[root@CanalKafka156 adapter]# tail -f adapter.log
2022-10-28 17:48:52.422 [Thread-3] INFO org.apache.kafka.common.utils.AppInfoParser - Kafka commitId : 98b6346a977495f6
2022-10-28 17:48:52.423 [Thread-3] INFO c.a.o.c.adapter.launcher.loader.CanalAdapterKafkaWorker - =============> Start to subscribe topic: example <=============
2022-10-28 17:48:52.424 [Thread-3] INFO c.a.o.c.adapter.launcher.loader.CanalAdapterKafkaWorker - =============> Subscribe topic: example succeed <=============
2022-10-28 17:48:52.548 [Thread-3] INFO org.apache.kafka.clients.Metadata - Cluster ID: KmwXcYzQQv2NhExMFTvmPg
2022-10-28 17:48:52.549 [Thread-3] INFO o.a.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=g1] Discovered group coordinator canalkafka156:9092 (id: 2147483647 rack: null)
2022-10-28 17:48:52.551 [Thread-3] INFO o.a.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-1, groupId=g1] Revoking previously assigned partitions []
2022-10-28 17:48:52.551 [Thread-3] INFO o.a.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=g1] (Re-)joining group
2022-10-28 17:48:52.570 [Thread-3] INFO o.a.kafka.clients.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=g1] Successfully joined group with generation 1
2022-10-28 17:48:52.571 [Thread-3] INFO o.a.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-1, groupId=g1] Setting newly assigned partitions [example-0]
2022-10-28 17:48:52.615 [Thread-3] INFO org.apache.kafka.clients.consumer.internals.Fetcher - [Consumer clientId=consumer-1, groupId=g1] Resetting offset for partition example-0 to offset 1.
现在所有服务都已正常,可以进行一些简单的测试:
- 在MySQL主库执行一些数据修改
mysql> use pydb
mysql> insert into t1 values(3,'ee');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t1 values(1,'ee');
Query OK, 1 row affected (0.00 sec)
- 日志输出
[root@CanalKafka156 adapter]# pwd
/usr/local/canal-1.1.3/adapter/logs/adapter
[root@CanalKafka156 adapter]# tail -f adapter.log
2022-10-28 17:56:51.805 [Thread-3] INFO o.a.kafka.clients.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-1, groupId=g1] Setting newly assigned partitions [example-0]
2022-10-28 17:57:11.727 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"name":"ee","id":1}],"database":"pydb","destination":"example","es":1666951046000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"t1","ts":1666951031398,"type":"INSERT"}
- 查询Greenplum
two_dw=> select * from t1;
id | name
----+------
3 | ee
1 | ee
(2 rows)
至此: MySQL中的数据变化被实时同步到Greenplum中。
遇到的报错汇总:
1、kafka 与 zookeeper 启动 cluster.id引起的报错
2、报错:Outer adapter sync failed! Error sync but ACK!
3、mysql+canal+kafka 接收消息乱码问题
文章PDF下载
Canal + Kafka + ClientAdapter.PDF
获奖文章推荐
《Oracle_索引重建—优化索引碎片》
《Oracle 自动收集统计信息机制》
《Oracle 脚本实现简单的审计功能》
《oracle 监控表空间脚本 每月10号0点至06点不报警》
《DBA_TAB_MODIFICATIONS表的刷新策略测试》
《FY_Recover_Data.dbf》
《Oracle RAC 集群迁移文件操作.pdf》
《Oracle Date 字段索引使用测试.dbf》
《Oracle 诊断案例 :因应用死循环导致的CPU过高》
《Oracle 慢SQL监控脚本》
《Oracle 慢SQL监控测试及监控脚本.pdf》
《记录一起索引rebuild与收集统计信息的事故》
《RAC DG删除备库redo时报ORA-01623》
《ASH报告发现:os thread startup 等待事件分析》
《问答榜上引发的Oracle并行的探究(一)》
《问答榜上引发的Oracle并行的探究(二)》
欢迎赞赏支持或留言指正
