




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
工作中经常用到 Elasticsearch,结合 kibana 便可以方便进行数据查询以及聚合分析进行可视化操作等,下面是我在工作遇到的一次经验分析,先来谈谈事情的开始吧!
由于工作需要短时间内对四五百万条不同的数据存入数据 ES,对kibana 来说是可以存入少量数据并且非常方便,但是数据量稍微大一些的时候,就需要进行分批次存入,操作的过程越多,出错的可能越大,那你可能会问为什么不直接操作 ES 了,数据库在内网中,一般情况是不能直接操作并且在服务器上非常不方便,于是利用自己的环境进行调试如下,最后实践生产。
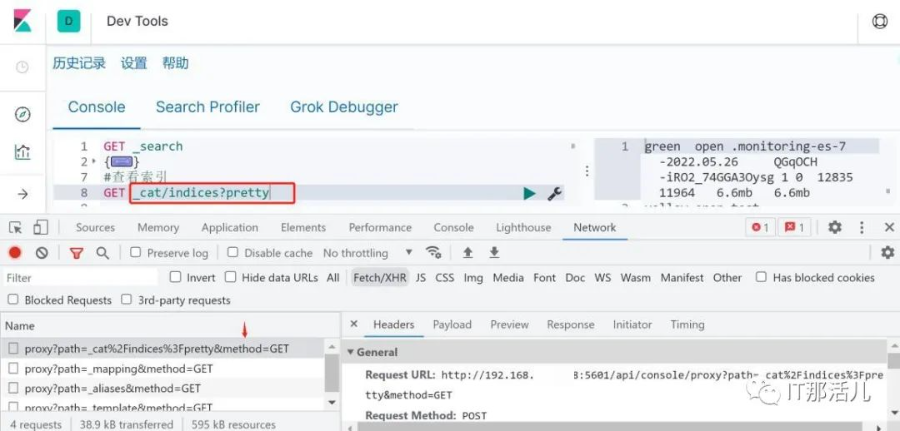
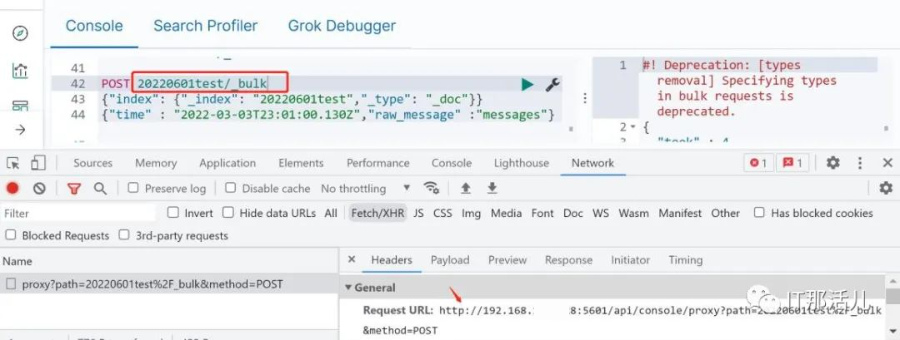
通过上述分析后,基本原理已经搞清楚了。


上述构造请求成功后,可以根据需要生成相应与语言的 API.
import requests
url= "192.168.XXX.128:5601/api/console/proxy?path=<path>&method=<method>" payload = "<body data here>" #需要以\n 换行的形式才可以,并且对内容大小有限制
headers = {
'kbn-version': '<kbn-version>',#kbn 版本号
'User-Agent': 'apifox/1.0.0 (https://www.apifox.cn)',#一般使用浏览器请求头即可
'Content-Type': '<Content-Type>'} # 一般使用这个即可 application/json response = requests.request("POST", url, headers=headers, data=payload) print(response.text)
实例测试如下代码:
import requests,json,time #pip install requests
def es_function(url,body):
headers = {"Content-Type": 'application/json',
'kbn-version': '7.0.0',
# 'kbn-version':'6.7.0',#'Authorization':'Basic
YWRtaW46c2hzbmMyMDE5Zmxpbms=',
}
session = requests.session()
result = session.post(url,data=body, headers=headers)
return result
url="http://192.168.XXX.128:5601/api/console/proxy?path=20220601test%2
F_bulk&method=POST"
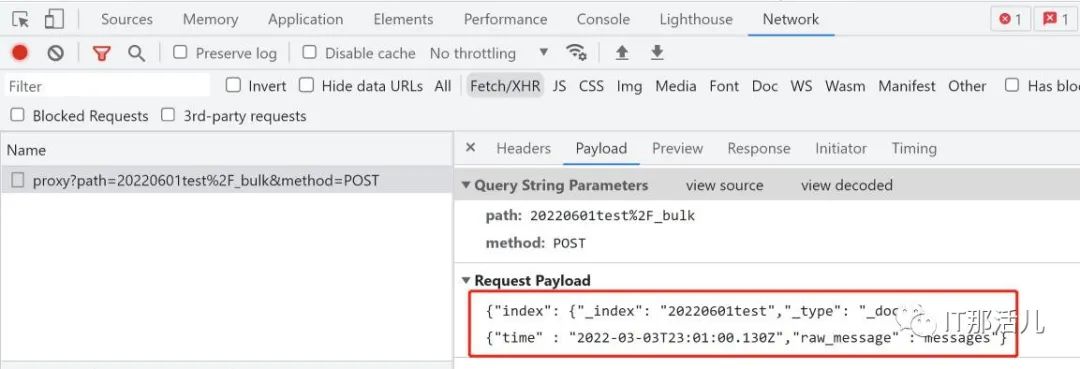
body='{"index": {"_index": "20220601test","_type": "_doc"}}' \
'\n{"op_time": "2022-05-03T23:01:00.130Z","raw_message": "message1"}' \
'\n{"index": {"_index": "20220601test","_type": "_doc"}}' \
\n{"op_time": "2022-06-03T23:01:00.130Z","raw_message": "message2"}\n'
bulk =es_function(url=url, body=body)
print('是否存入成功',bulk.status_code)
进行查询:
query={"query":{'match_all':{},}}
url_query="http://192.168.XXX.128:5601/api/console/proxy?path=20220601
test/_search&method=POST"
response =es_function(url=url_query, body=json.dumps(query))
print("请求状态:",response)
items = response.json()
print(items)
利用循环构造数据量的方式,经单机测试的情况下,批量存入一百万数据所需要花费的时间在 90 秒左右。
由于工作需求存入大批量数据到 ES,条件限制不能直接连接,利用现有的kibana 接口进行多次请求分析 url 构造及参数传递方式,然后利用 Apifox 模拟请求便可生成相应语言的接口,选择熟悉的编程语言对千万级别数据进行分批自动存入,减少操作次数以及提高准确率和工作效率。
本文作者:IT那活儿(上海新炬中北团队)
本文来源:“IT那活儿”公众号

