




ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。
1. 整体架构
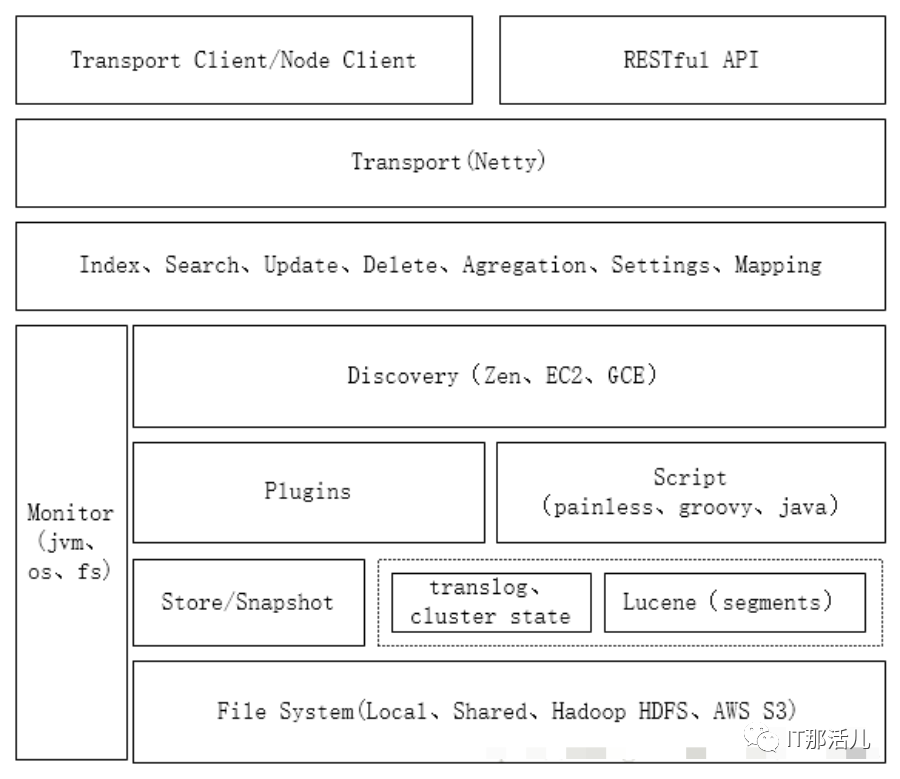 --Transport Client/Node Client/REST API:三种访问es集群的方式;
--Transport Client/Node Client/REST API:三种访问es集群的方式;
--Transport(Netty):通信模块,数据传输,底层采用netty框架;
--Index、Search…:支持搜索,索引等常用操作;
--Discovery:节点发现,集群之间通信的基石;
--Plugins:很多服务以插件形式提供,官方和社区支持的ik、head、river、discovery gce…;
--Script:提供脚本支持,内置painless,groovy等,默认painless性能还可以;
--Store/Snapshot:文件存储与访问,快照创建和恢复;
--translog、cluster state、segments:es主要文件类型,其中translog、cluster state是es添加的数据,多个segments段组成一个完整的lucene索引;
--Monitor:监控模块,监控jvm,文件系统,操作系统等运行情况;
--File System:es支持可以在多种文件系统上运行,本地、共享型、HDFS、亚马逊云平台等。
2. 基本概念
elasticsearch中必须掌握的几个基本概念:
--集群(Cluster)一组拥有共同的 cluster name 的节点。
--节点(Node) 集群中的一个 Elasticearch 实例。
--索引(Index) 相当于关系数据库中的database概念,一个集群中可以包含多个索引。这个是个逻辑概念。
--主分片(Primary shard) 索引的子集,索引可以切分成多个分片,分布到不同的集群节点上。分片对应的是 Lucene 中的索引。
--副本分片(Replica shard)每个主分片可以有一个或者多个副本。
--类型(Type)相当于数据库中的table概念,mapping是针对 Type 的。同一个索引里可以包含多个 Type。
--Mapping 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建。
--文档(Document) 相当于数据库中的row。
--字段(Field)相当于数据库中的column。
--分配(Allocation) 将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。
3. 详细过程
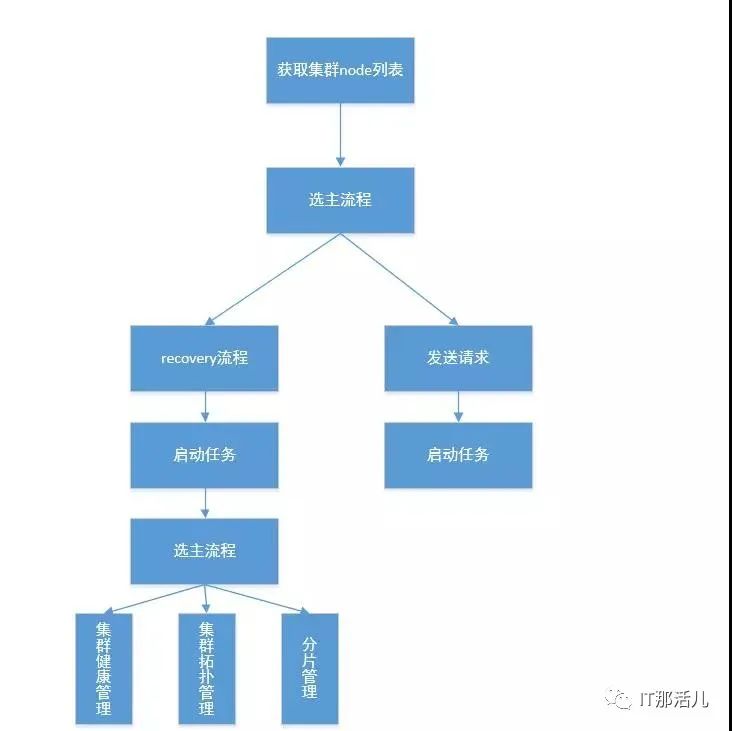
3.1 启动过程
3.2 ElasticSearch读写原理
写操作原理:
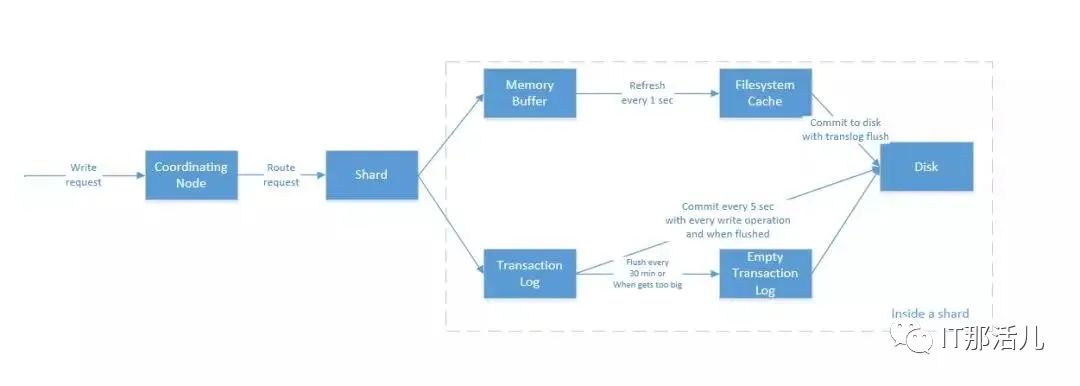
1)Coordinating Node
shard = hash(document_id) % (num_of_primary_shards)
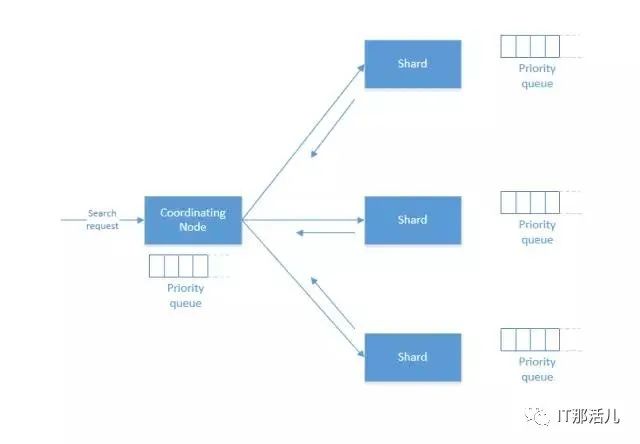
读操作原理:

本文作者:潘宗昊(上海新炬中北团队)
本文来源:“IT那活儿”公众号

