




当消费者从电子商务网站目录中搜索产品信息时,面临着产品信息检索时间长,响应慢等问题,这会导致糟糕的用户体验,进而错过潜在客户;针对传统企业,如电信、银行或社保,也面临公众查询流水明细或历史数据时,生产系统不堪重负,导致系统无法响应甚至宕机,造成不好的社会影响。
如今,越来越多的企业采用开源的分布式平台作为存储查询平台,Elasticsearch就是其中之一。Elasticsearch是一个高度可扩展的开源全文搜索和分析引擎,当前最新版本为8.2。它允许您快速、近乎实时地存储、搜索和分析大量数据。它通常用作支持具有复杂搜索功能和要求的应用程序的底层引擎/技术。
通过将关系型数据库的数据加载到Elasticsearch,并将大部分只读业务迁移到Elasticsearch,从而在一定程度上缓解生产库的IO压力;另外,把只读应用部署到Elasticsearch之后,即使查询用户增长迅速,也可以通过灵活的弹性扩展来应对高峰时的压力。
将生产库的数据加载到Elasticsearch,有多种方法,包括按天批量更新或脚本定时加载。如果是OLTP应用,最佳的实践是在生产系统有数据变化之后,在ElasticSearch中即可搜索查看,以实现读写分离的业务价值。采用数据同步软件Oracle GoldenGate,可把生产数据秒级同步到Elasticsearch,实现真正的读写分离。
本文就如何配置GoldenGate,实现Oracle数据库到Elasticsearch的实时同步,做一简单说明,并就同步过程中的一些问题如DDL变更,提供相应补充说明。
GoldenGate的基本原理,以及针对Oracle数据库的抽取和传输配置不在本文赘述,如有需要,可通过网络搜索或查询Oracle官方文档获取相应信息。
本文以Elasticsearch 7.13为目标平台,需要事先准备Elasticsearch的环境,如有必要,也可以准备一个Oracle源端数据库。
从Oracle官网下载GoldenGate for Big Data软件(当前版本为GoldenGate 21.3),解压之后可看到有一个AdapterExamples目录,此目录下包含当前GoldenGate支持的所有大数据平台和相关示例参数文件,如Hbase, Kafka, Mongodb, Cassandra, Elasticsearch, Hive等。
进入AdapterExamples\big-data\elasticsearch目录,我们可以看到有如下文件:
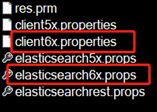
其中res.prm是replicat进程的参数文件,拷贝上述*6x*属性文件和res.prm到GoldenGate安装目录的dirprm目录下,GoldenGate的安装即算完成。
res进程,默认使用GoldenGate自带的示例数据AdapterExamples/trail/tr。
直接添加res 进程到GoldenGate。
GGSCI>add replicat res, exttrail AdapterExamples/trail/tr
GGSCI>view param res
REPLICAT res
-- Command to add REPLICAT
-- add replicat res, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/elasticsearch6x.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 1000
MAP QASOURCE.*, TARGET QASOURCE.*;
其中:
$ cat client6x.properties
cluster.name=estest # 集群名,如果有使用ES集群
xpack.security.user=elastic:changeme # 用户和密码,如果需要登录才能访问
$ cat elasticsearch6x.props
gg.handlerlist=elasticsearch
gg.handler.elasticsearch.type=elasticsearch
## Handler properties for Elasticsearch 6.x and 7.0.0
gg.handler.elasticsearch.ServerAddressList=10.10.30.10:9300 # 注意此处是9300端口
gg.handler.elasticsearch.clientSettingsFile=client6x.properties
gg.handler.elasticsearch.version=7.x # 此处使用Elasticsearch 7.x
#gg.handler.elasticsearch.bulkWrite=true
# For ES 6.x and 7.0.0 connectivity # 下面需要根据ES安装路径配置
gg.classpath=dirprm/*:/home/es/elasticsearch/lib/*:/home/es/elasticsearch/modules/transport-netty4/*:/home/es/elasticsearch/modules/re
index/*:/home/es/elasticsearch/modules/x-pack-core/*:/home/es/elasticsearch/modules/percolator/*:/home/es/elasticsearch/modules/lang-m
ustache/*:/home/es/elasticsearch/modules/parent-join/*:
确认ES节点正常运行,然后启动res进程
GGSCI>start res
查看示例数据写入情况
GGSCI (es1) 8> stats res, total
Sending STATS request to Replicat group RES ...
Start of statistics at 2022-05-18 10:56:23.
Replicating from QASOURCE.TCUSTMER to QASOURCE.TCUSTMER:
*** Total statistics since 2022-05-17 11:17:32 ***
Total inserts 5.00
Total updates 1.00
Total deletes 0.00
Total upserts 0.00
Total discards 0.00
Total operations 6.00
Replicating from QASOURCE.TCUSTORD to QASOURCE.TCUSTORD:
*** Total statistics since 2022-05-17 11:17:32 ***
Total inserts 5.00
Total updates 3.00
Total deletes 2.00
Total upserts 0.00
Total discards 0.00
Total operations 10.00
End of statistics.
可以看到GoldenGate有写入两张表的数据到Elasticsearch中,包括源表的增、删、改操作都有写入到Elasticsearch。
在Elasticsearch中查看写入的索引列表:

查看具体某个索引的情况
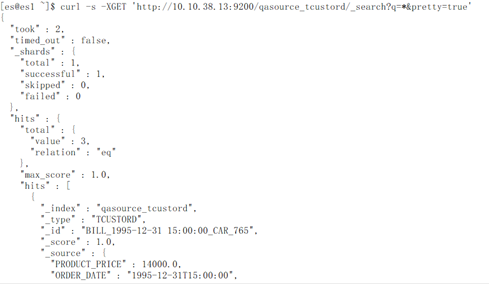
至此,使用GoldenGate同步数据到Elasticsearch即配置完成。
如果有Oracle或其它数据库,也可以配置这些数据库为源。需要配置GoldenGate的抽取和传输进程,然后创建另一个replicat进程读取创建的队列文件,即可实现数据库的数据实时同步到Elasticsearch中。
由此可见,从数据库实时抽取数据到Elasticsearch,配置GoldenGate的过程简单快捷,使用安装软件中自带的示例简单修改之后即可实现从生产到Elasticsearch的实时复制。如果对GoldenGate有一定了解和实践经验,那么从数据库到Elasticsearch的同步配置只需要1-2小时。
针对GoldenGate同步到Elasticsearch,主要支持如下DML操作:
Insert/Update/Delete,每张表在同步到Elasticsearch时,都会建立相应的Index,如果目标端没有对应的Index,GoldenGate会自动建立。
GoldenGate不支持源端truncate操作,如有需要,只能手工在Elasticsearch上delete index。
其它支持说明可参考GoldenGate for big data documents中Elasticsearch一节。
理论上源库DDL变化,GoldenGate不会同步。但针对以下情况,GoldenGate可以满足:如果源端新增表,且GoldenGate按schema.*配置的抽取和投递参数,则新增表的数据也可以同步到Elasticsearch上,且GoldenGate会自动为该表创建一个与表名相同的Index;
如果源表新增字段,GoldenGate从这个点开始,后续变化的数据在Elasticsearch上会有新字段的值,但历史数据将不会有新的字段;如果需要,可在源表上进行一次全表update操作,此时GoldenGate会将全表数据重新初始化一次到Elasticsearch,如此所有记录都会有新的字段;
如果源表字段增加长度,GoldenGate可正常同步,因为目标端上是Json文本格式,除非超过Elasticsearch中最大长度限制;
源端删除字段(一般在生产环境中不会有这种操作):源库删除字段之后,Elasticsearch上不会有变化,原有数据不受影响,除非删除index之后重新初始化;源库update旧记录不会影响Elasticsearch上被删除的字段;如果源库新增记录,则Elasticsearch上的新记录将不包含被删除字段。
GoldenGate源端支持多种数据平台(Oracle, SQLServer, MySQL, DB2, Sybase, Apache Cassandra, Kafka等),向企业提供实时采集生产数据的能力,并屏蔽不同数据平台之间的复杂性。如果企业当前正在建设大数据平台或大数据湖,或对数据采集的实时性要求很高,那么GoldenGate将会是一个不错的选择。
针对大数据平台,GoldenGate具备开箱即用的功能。一些常用的大数据平台,如Hbase, Hive, hdfs, Mongodb, Kafka, Bigquery, Snowflake, Redshift, Elasticsearch等,通过修改GoldenGate自带的示例参数文件,即可开始数据的实时复制和集中,极大的提升企业在数据处理方面的效率和竞争力。

作者简介
蔡东林,甲骨文云平台数据集成资深咨询顾问,专注于甲骨文数据集成相关产品及解决方案。具有15+年的数据仓库、数据处理经验,熟悉甲骨文相关集成产品,方案和项目实施经验。熟悉电信,银行行业。您可以通过donglin.cai@oracle.com与他联系。
