




一、事件的发生与处理经过
晚上22:15 收到数据库日志报警:ORA-1652 短信,把处理过程记录下来供大家参考。
- 查看alert日志如下:

- 查看TEMP使用情况:
SELECT S.sid || ',' || S.serial# sid_serial,
S.username,
T.blocks * TBS.block_size / 1024 / 1024 mb_used,
T.tablespace,
T.sqladdr address,
Q.hash_value,
Q.sql_text
FROM v$sort_usage T, v$session S, v$sqlarea Q, dba_tablespaces TBS
WHERE T.session_addr = S.saddr
AND T.sqladdr = Q.address(+)
AND T.tablespace = TBS.tablespace_name
ORDER BY mb_used desc;

- 查看AWR报告情况

找到了引起的2条性能SQL,考虑到此查询不影响正常交易,且是晚上临时优化可能会优化出其它BUG,因此扩展了30G的临时表空间临时顶一下,等待明天上班后再做优化处理。(期间已经和领导做了汇报,并与开发确认了SQL功能。及时的上报问题是职场必备技能)
- 扩展临时表空间语句:
alter tablespace temp add tempfile '+DATA/RAC/tempfile/temp.02.dbf' size 100m AUTOEXTEND ON NEXT 500M MAXSIZE 30g;
二、问题复现及优化
1、数据准备
- 表及数据、性能SQL已经做脱敏处理。
SQL> select count(*) from t_main_order;
COUNT(*)
----------
20136575
SQL> select count(*) from t_INFO;
COUNT(*)
----------
9365634
SQL> select count(*) from t_bank;
COUNT(*)
----------
12944012
create index IDX_mer_id on t_main_order (mer_id);
create unique index idx_t_order_id on t_main_order (t_order_id);
create index IDX_out_id on t_bank (out_id);
create index ind_REVERSE_bank_no on t_bank (REVERSE(bank_no));
2、性能SQL
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_main_order t
left join t_INFO r
on r.t_order_id = t.t_order_id
left join t_bank o
on r.th_id = o.out_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
看到此SQL第一反应是 like 条件没走索引导致的性能问题
3、执行计划
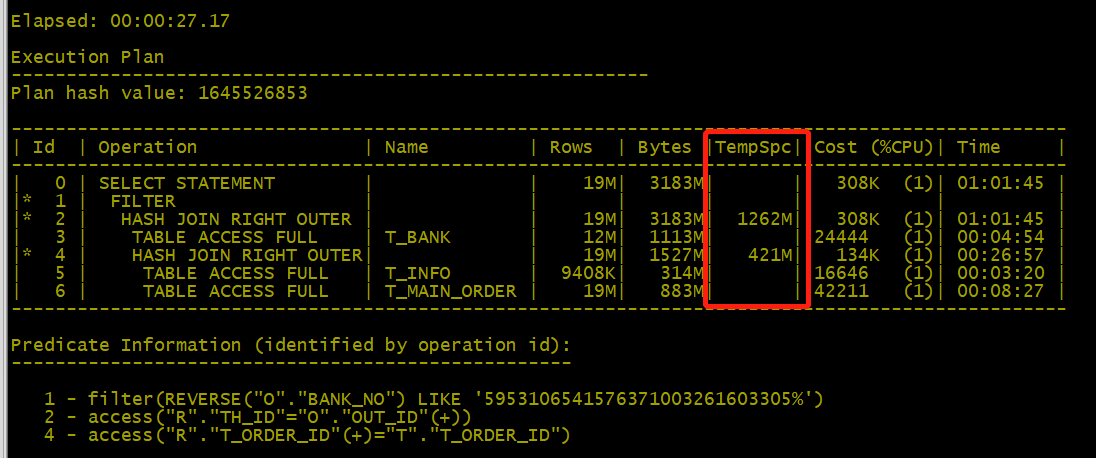
- 发现的问题:
1、执行耗时:27s
2、临时表空间使用:1262M+421M=1683M - 问题分析
从执行计划可以看出TEMP表空间消耗在HASH JOIN(TempSpc),简述一下HASH JOIN原理:借助HASH算法将2张表做关联(关联仅一次),此操作在PGA空间完成,当PGA空间放不下时,会占用临时表空间(TEMP),因此HASH JOIN适用于小表之间的关联。
这条SQL涉及到的表的数据量达到了千万量级的大表,且where 条件筛选的是辅表(t_bank)reverse(o.bank_no) 字段,从执行计划的执行顺序可以发现SQL执行是先做的表关联再做的条件筛选。
因此第一反应的"LIKE"并不是此SQL的性能问题。
4、优化一:把t_bank做主表,同样可以满足业务需求
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_bank o
left join t_INFO r
on r.th_id = o.out_id
left join t_main_order t
on r.t_order_id = t.t_order_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
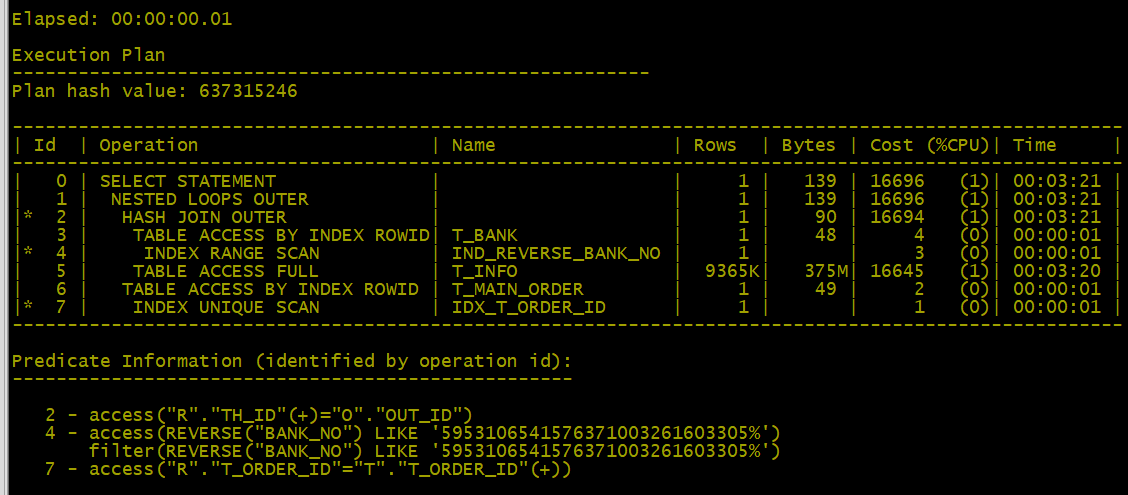
- 优化后的执行计划分析:
1、SQL执行顺序先做了条件筛选(*4|INDEX RANGE SCAN|IND_REVERSE_BANK_NO)并使用了索引,减少了表(t_bank )与(t_INFO )关联的记录,同样也使用到了hash join但此操作未使用TEMP。
2、执行时间消耗:00:00:00.01与00:00:27.17是质的提升。
5、优化二:把left join 改为 inner join
select t.mer_id,
t.t_order_id,
o.amt,
t.create_date,
case when o.source is null then '10000' else o.source end source
from t_main_order t
inner join t_INFO r
on r.t_order_id = t.t_order_id
inner join t_bank o
on r.th_id = o.out_id
where reverse(o.bank_no) like reverse('5033061623001736751456013595') || '%';
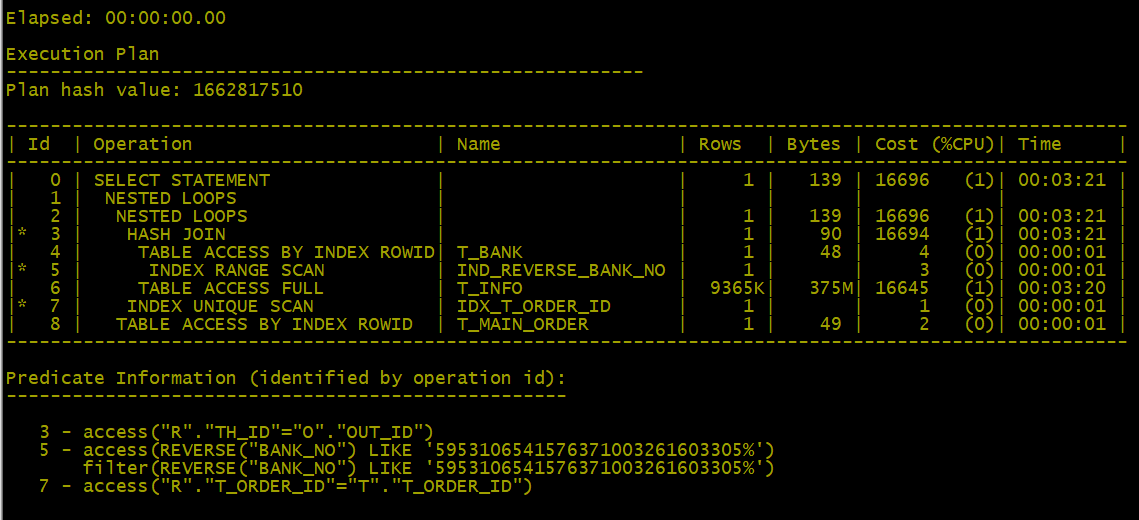
6、进一步优化t_INFO表增加索引
create index IDX_INFO_order_id on t_INFO (t_order_id );
create index IDX_INFO_th_id on t_INFO (th_id );
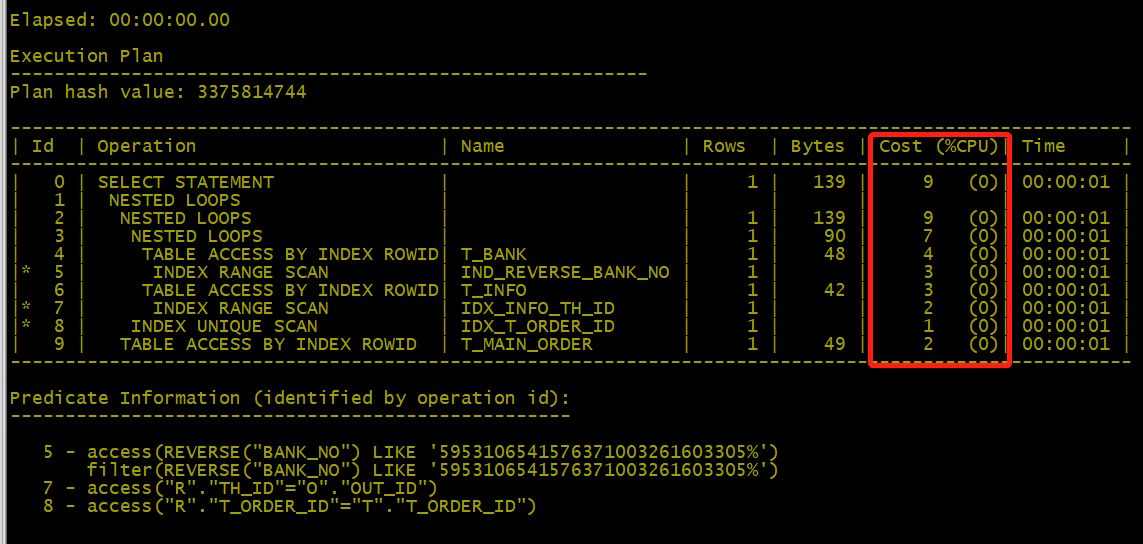
- 消耗(Cost (%CPU))从16696直接降到了9.
- 注:个人觉得这一步优化非必要,通过上次的2个优化方案执行时间已经降至:00:00:00.01。
增加索引代表着空间使用率增加。一切的优化没必要做到极致,极致是有代价的。
三、总结:
分析到最后发现这条性能SQL的根本问题:主表辅表开发人员没整清楚(:!)
文章推荐
– 故障
《Oracle_索引重建—优化索引碎片》
《Oracle 自动收集统计信息机制》
《DBA_TAB_MODIFICATIONS表的刷新策略测试》
《FY_Recover_Data.dbf》
《Oracle RAC 集群迁移文件操作.pdf》
《Oracle Date 字段索引使用测试.dbf》
《Oracle 诊断案例 :因应用死循环导致的CPU过高》
《记录一起索引rebuild与收集统计信息的事故》
《RAC DG删除备库redo时报ORA-01623》
《问答榜上引发的Oracle并行的探究(一)》
《问答榜上引发的Oracle并行的探究(二)》
《DG 同步延迟之奇怪的经典报错:ORA-16191》
– 等待事件
《log file sync》 等待事件问题分析汇总
《ASH报告发现:os thread startup 等待事件分析》
– 监控&脚本
《DG standby time 监控脚本部署》
《Oracle 慢SQL监控脚本》
《Oracle 慢SQL监控测试及监控脚本.pdf》
《oracle 监控表空间脚本 每月10号0点至06点不报警》
《Oracle 脚本实现简单的审计功能》
– 安装系列
《ORACLE_19C_linux安装.pdf》
《Oracle 19c-手工建库.pdf》
《19c单库升级19.11补丁.pdf》
《19c_rac补丁《19.11-p32841500》.pdf 》
《oracle_图形-单实例11.2.0.4升级19.3.pdf》
《oracle_11.2.0.3升级11.2.0.4–单实例升级.pdf》
《oracle_静默-单实例 11.2.0.4升级19.3.pdf》
《CentOS_6.7系统一步一步 RAC 11.2.0.4升级19.3.pdf》
《整理后_RAC_11.2.0.4升级19c.pdf》
欢迎赞赏支持或留言指正
