原文链接:
https://www.bmc.com/blogs/elasticsearch-machine-learning/
翻译:年少有为
这里我们讨论弹性搜索机器学习。ML是ElasticSearch的一个附加组件,可以通过独立安装购买,也可以作为每月Elastic Cloud订阅的一部分付费。
ElasticSearch机器学习
机器学习这个术语有一个广泛的定义。这是一个交给门外汉的通用术语,用来避免讨论各种模型的细节。 具体来说,ElasticSearch ML做的是无监督学习时间序列分析。这意味着它从一组数据中得出结论,而不是使用训练模型(即就像你使用不同的技术进行回归分析,包括神经网络,最小二乘,或支持向量机。
在这里,我们讨论ElasticSearch机器学习。ML是ElasticSearch的附加组件,您可以通过独立安装进行购买,也可以作为每月Elastic Cloud订阅的一部分进行支付。
这有什么用呢
要了解无监督学习时间序列分析的价值,请考虑网络安全或应用程序性能监控的典型方法。也就是说,假设数据服从正态(高斯)分布,然后选择一个在标记离群值时认为重要的阈值。
这是我们熟悉的钟形曲线方法。即使一个人不这样想,那也是他们所做的。这条曲线是用高中数学学生应该知道的术语来描述的:均值、方差和标准差。但这不是机器学习。
不比猜测更好
通常情况下,当一个事件位于曲线的两端(发生这种事件的概率较低)时,从事应用程序监控或网络安全工作的人员会对其进行标记。通常称为σ的倍数(σ),σ是标准差的倍数,躺在那里一个事件的概率很低。
您也可以嘲笑地称这种方法为猜测。
阈值方法是有缺陷的,因为它会导致误报。这导致分析师花时间追踪那些在统计上并不真正重要的事件。
例如,在网络安全方面,仅仅因为某人现在比以前更多地将数据发送到特定的IP地址并不意味着该事件是不受限制的。他们需要考虑事件的周期性本质,并根据已经发生的事情来看待当前的事件。每个月都可能发生这种情况,这很正常。一个聪明的算法可以做到这一点,例如,应用最小二乘法,并寻求最小化的误差(即。,即观察到的数据与预期数据之间的差异)。这就是ElasticSearch的工作方式。他们运用了几种算法,不仅仅是最小二乘法。
如何使用ElasticSearch进行机器学习
这里我们展示如何使用这个工具。在另一篇博文中,我们将解释它背后的一些逻辑和算法。但是这个工具应该使我们不必理解所有这些。尽管如此,你还是应该相信它告诉你的东西。
我们将通过ElasticSearch从这个视频中提取并将其放慢到单个步骤以使其更易于理解。
对于数据,我们将使用纽约市出租车数据集,您可以从Kaggle下载这里的数据。这些数据为我们提供了几年内纽约出租车的接送时间和地点。我们想要看到交通何时以一种异常的方式减少或增加,比如出租车罢工或暴风雪。
在Kibana ML屏幕中加载这些数据有一些限制,这是ES ML的一个特性,一次只能加载100 MB的数据。出租车的数据远不止这些。它包括一个测试和训练数据集。因为我们不是在训练一个无监督学习的模型,所以我们只选择其中的一个。因为我们需要将它限制在100 mb,所以我们将像这样分割200 mb的数据文件,然后选择一个90MB的数据集。
unzip train.zipsplit -b 90000000 train.csv
还请注意,除非您有一个大型集群,否则ElasticSearch在加载这样的数据时往往会冻结。但它仍然会加载数据。因此,一旦它看起来已经完成加载,意味着屏幕不再更新,只要点击它,并去索引管理,看看有多少记录在新的索引。对于每个90MB的数据应该是100,000。
将数据上传到机器学习屏幕
打开Kibana,点击机器学习图标。即使你没有试用或付费许可,你也会有那个图标。但是,将缺少异常检测、就业创造和其他屏幕。ElasticSearch将指导您注册试用版。
从Data Visualizer中选择导入一个文件,并导入从train.csv中分离出来的一个文件。或者,如果您以不同的方式加载数据,您可以使用Select an Index Pattern选项。
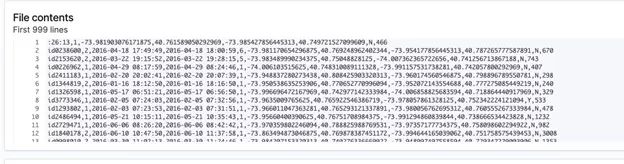
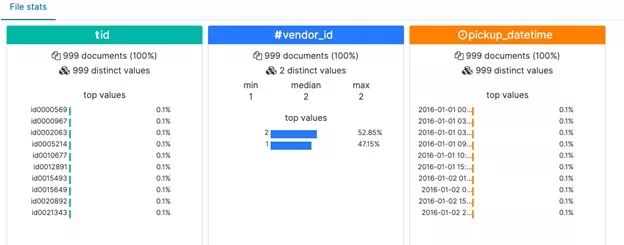
ElasticSearch将显示前1000行,然后进行一些快速记录计数。

然后单击屏幕底部的Import。为索引模式命名,比如ny*。
异常检测
现在我们进入有趣的部分。我们想让ElasticSearch查看这个时间序列数据。选择单一度量选项。
然后我们必须创造一个就业机会。ElasticSearch将在后台运行聚合查询。我们告诉它对每段时间的乘客总数求和。(如果下拉框不工作,只需复制和粘贴字段名。)
我们使用这个集合来观察在正常范围之外的乘客数量的下降或上升,并考虑到乘客数量随时间的正常上升和下降。
单击按钮使用全范围的数据,这样它将挑选所有可用的数据,而不是您手动放置的日期间隔。您可以将bucket选项更改为10m。
然后屏幕将填写如下:
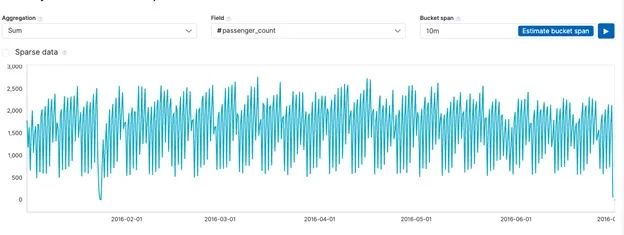
然后单击Create Job。它开始运行自己的算法,并在完成逻辑后用垂直的彩色线条更新显示。
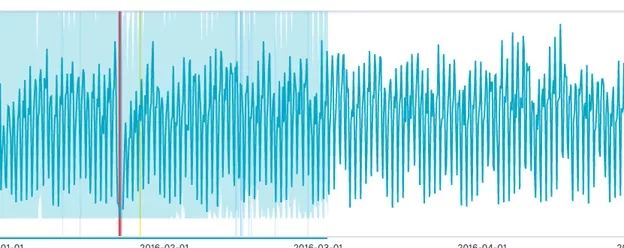
查看异常检测结果
完成后单击“查看结果”。
我们将在另一篇文章中详细解释它所做的计算,毕竟,如果您不了解它是如何得出结论的,就不应该信任ML模型。
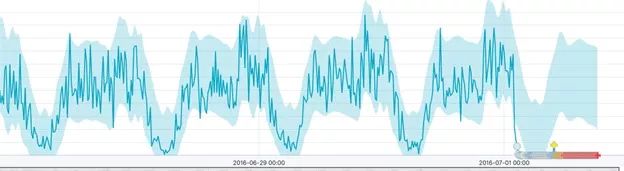
但你可以这样想。出租车在工作日和周末之间起起伏伏,高峰时间和非高峰时间也不一样。如果你研究的是销售数据,你可以称之为趋势或季节性。所以如果你用高斯(正态)分布来衡量,那就错了,因为均值和方差会超过整个集合,包括高点和低点。因此,改进的算法可以根据数据子集生成多个正态曲线(和其他频率分布),从而消除这种向上和向下的模式。
这将产生以下结果。浅蓝色区域为移动概率分布函数。红色区域是你能看到的异常点,也就是曲线外的点。这也是我们耗尽数据的时候。它通过计算一个异常分数来标记一个异常值,这一点我们将在下一篇文章中讨论。