




在 Elasticsearch(简称 ES,下同) 中,文档(Document)是数据的最小单位,文档被序列化成 JSON 存储在 ES 中。每个文档都会有一个唯一 ID,这个唯一 ID 我们可以自己指定,也可以交给 ES 自动生成。我们指定创建文档 ID 时,需要考虑 ID 的均衡性,避免产生分配不均衡和文档 ID 重复的问题,所以一般情况下交给 ES 自动生成文档 ID 即可。
1. 元数据
在学习文档的操作(CRUD)之前,我们先来熟悉下文档的元数据(用于标注文档的相关信息,以下划线(_)开头)。下面是一条文档的数据基本结构示例:
{"_index": "my_index","_type": "_doc","_id": "cWN_xnkBb3ZCZfkK69VK","_version": 1,"_score": null,"_source": {"date": "2021-06-01"},"fields": {"date": ["2021-06-01T00:00:00.000Z"],"@timestamp": ["2021-06-01T07:35:42.634Z"]},"sort": [1622532942634]}
下面我们来认识一下:
_index:文档所属的索引名
_type:文档所属的 type,从 ES 7.0 开始约定都用 _doc
_id:文档的唯一 ID
有了上面三个字段,我们就可以确定唯一的文档了,下面是剩下的其他元数据:
_version:文档的版本信息,可用于并发控制避免冲突
_score:文档相关性打分
_source:文档的原始 JSON 数据
2. 文档的 CRUD
文档的 CRUD 指的是文档的:创建(Create、Index),读取/查询(Read),更新(Update),删除(Delete),如下表所示:
| 操作 | 示例 |
| Index | PUT my_index/_doc/1 {"user":"Harper","comment":"Happy wife,happy life"} |
| Create | PUT my_index/_create/1 {"user":"Harper","comment":"Happy wife,happy life"} POST my_index/_create/_doc (不指定 ID,自动生成) {"user":"Harper","comment":"Happy wife,happy life"} |
| Read | GET my_index/_doc/1 |
| Update | POST my_index/_update/1 {"doc":{"user":"Harper","comment":"Happy wife,happy life.This is why we life."}} |
| Delete | DELETE my_index/_doc/1 |
2.1 Index
Index 操作表示:如果文档的 ID 不存在,则创建新的文档,若文档的 ID 存在,则先删除现有文档,然后再创建新的文档,同时文档版本 +1。
语法:PUT <index>/<_type>/<_id>
<index>:文档所属的索引名
<_type>:文档所属的 type,固定为 _doc
<_id>:文档的唯一 ID
实例:
执行语句:

第 1 次执行结果:
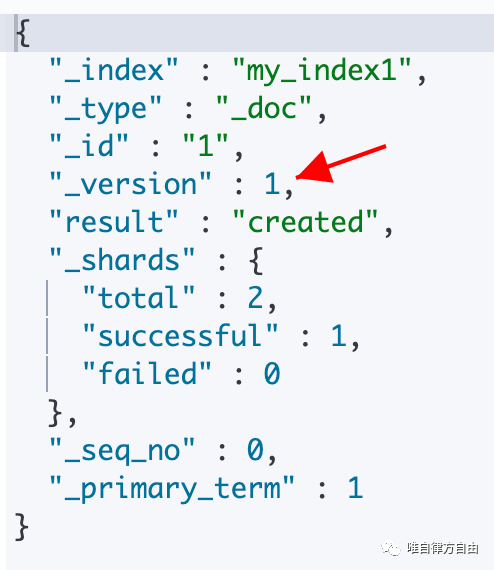
第 2 次执行结果:
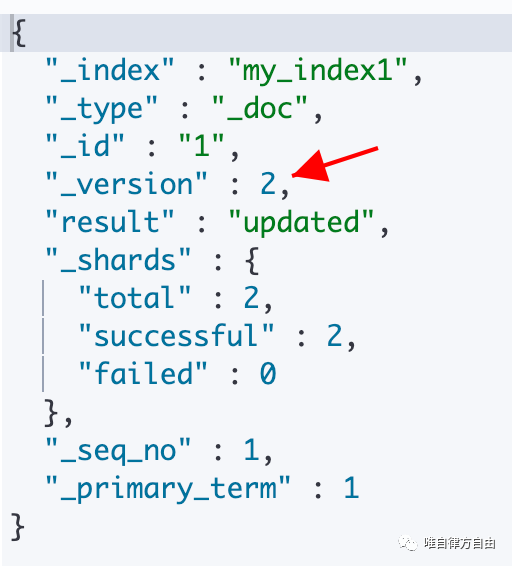
2.2 Create
Create 操作表示:创建新的文档,但如果文档 ID 已经存在,则创建失败。该操作支持两种方式:
POST自动生成文档唯一 ID
PUT 指定文档唯一 ID
语法:
指定文档 ID 来创建文档
PUT <_index>/_create/<_id>
PUT <_index>/_doc/<_id>?op_type=create
自动生成文档 ID 来创建文档
POST <_index>/_doc
实例:
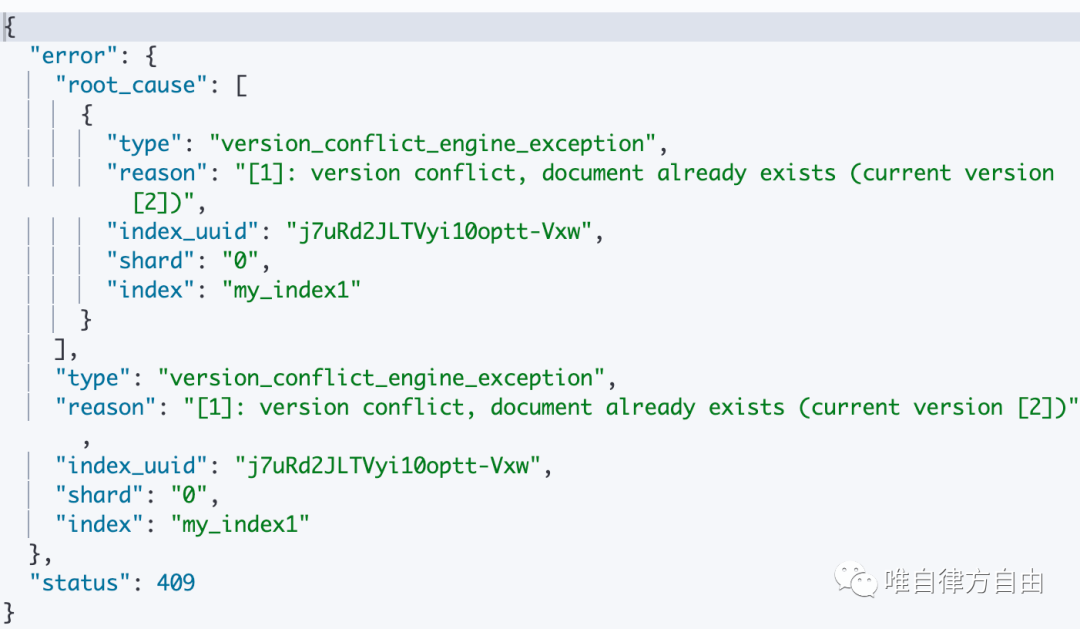
文档 ID 已存在时
执行语句:

执行结果:
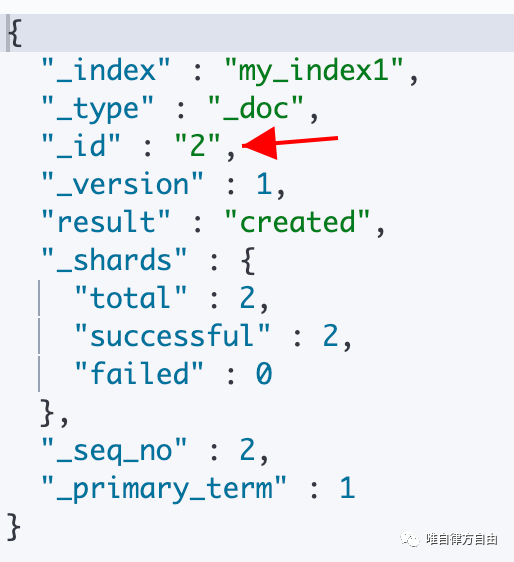
文档 ID 不存在时
执行语句:

执行结果:
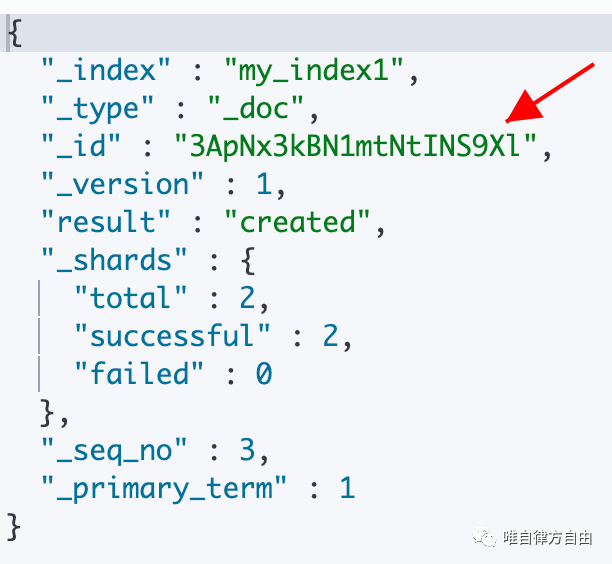
自动生成文档 ID
执行语句:
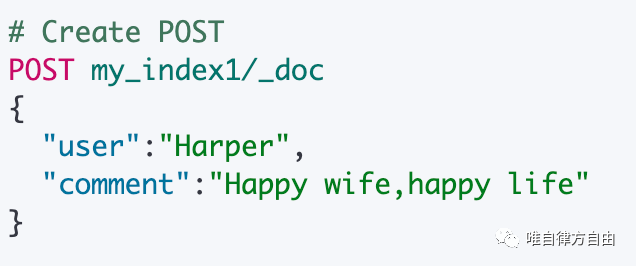
执行结果:
2.3 Read
Read 操作表示:根据文档 ID 获取相应的文档信息。
语法:GET <_index>/_doc/<_id>
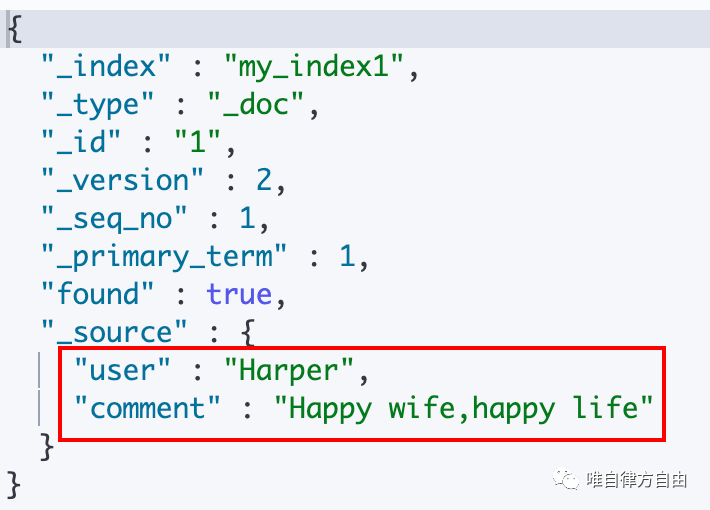
实例:
执行语句:

执行结果:
2.4 Update
Update 操作表示:更新的文档必须存在,更新时只会对相应字段做增量修改,实现真正数据更新。
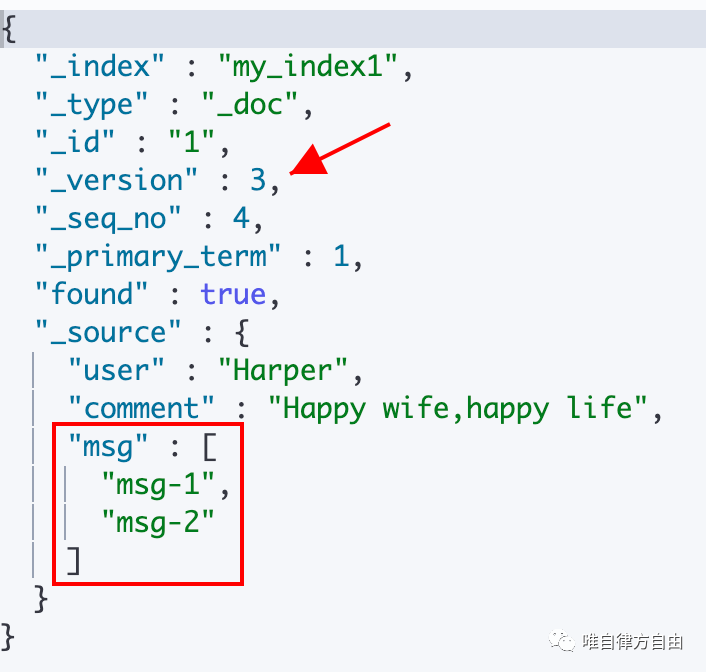
语法:(Payload 需要包含在“doc”中)
POST <_index>/_update/<_id>{"doc":{"msg":["msg-1","msg-2"]}}
实例:
执行语句:

执行结果:(版本 +1)

2.5 Delete
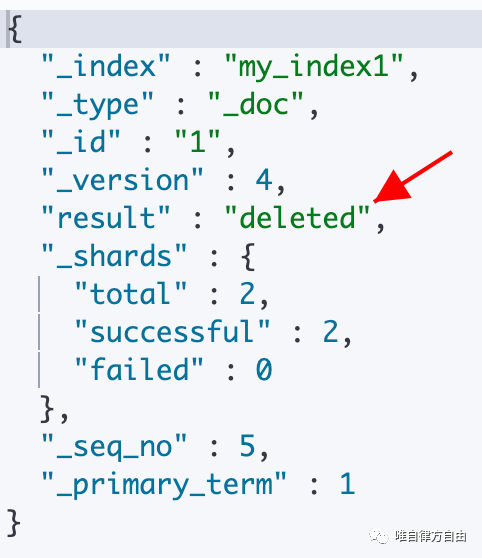
Delete 操作表示:根据文档 ID,删除相应文档。(若文档 ID 不存在,不报错)
语法:DELETE <_index>/_doc/<_id>
实例:
执行语句:

执行结果:(版本 +1)
2.6 小结
Index 操作相对于 Create、Update 操作的不同之处在于:如果文档不存在,Index 就会创建新的文档。如果文档存在,现有文档会被删除,新的文档会被创建,版本信息也会加 1。
而对于 Create 操作,如果有相同的文档 ID,则不能创建新的文档,会报错。
Update 操作,如果发现有相同文档 ID,不会删除原来的文档,而是实现真正的数据更新,若没有需要操作的文档 ID,则会报错。
总之:
Index = 删除再创建
Create = 创建新文档,如果已经存在,会报错
Update = 会对文档做增量的更新
3. 文档的批量操作
3.1 Bulk API
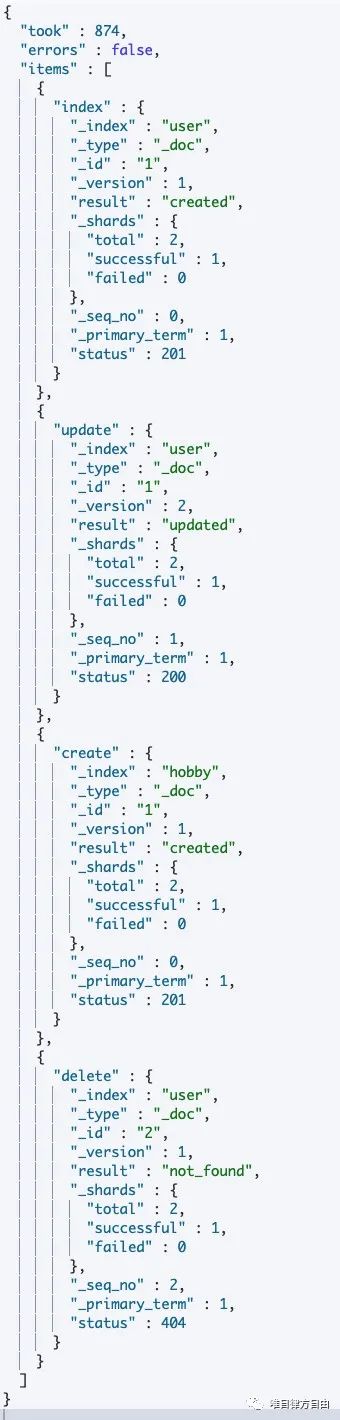
Bulk API(批量操作)的作用:在访问网络 Rest API 时,每一次的访问都需要重新建立网络开销,因此是非常消耗资源性能的。而 Bulk API 的核心思想就是在一次 Rest 请求中,对不同索引执行多次操作,减少不必要的建立网络的开销,Bulk API 支持四种操作类型:Index、Create、Update、Delete(注意没有 Read 操作)。
在 Bulk API 操作过程中,如果有单条操作失败,并不会影响其他操作,同时,返回结果包含了每一条操作的执行结果。
实例:
执行语句:

执行结果:
3.2 mget
mget 和 Bulk API 的思路是一样的,都是为了减少网络连接所产生的开销,以提高性能。通过提供一些列的文档 ID,在一次 API 请求中,就可以将所有的文档信息返回。
实例:
执行语句:
一次读取不同 index 时:

读取相同 index 时:

执行结果:
一次读取不同 index 时:

读取相同 index 时:

3.3 msearch
msearch(批量查询)通过一次 Rest 访问,对不同索引进行不同查询。
实例:
执行语句:

执行结果:

3.4 小结
对于Bulk API、mget、msearch 等批量操作的 API,通过调用它们可以很好的提高性能,但是在调用时也不要过多的发送数据,否则也会容易导致 ES 集群过大的压力,造成性能的下降。那么过多的数据一般控制在多少为好呢?一般建议是 1000-5000 个文档,如果文档很大,可以适当减少队列,大小建议是 5-15M,默认不能超过 100M,否则会报错。
虽然我们在执行 CU 操作,或者批量执行 CU 操作时,动态的向索引更新或者创建字段。此时并没有对索引预先做 mapping 定义,但 ES 会根据文档类型进行类型推断,将新增的字段定义在 mapping 中。在生产环境中,建议先做 mapping 设定后再写入数据。
mget 与 msearch 的区别:mget 是通过文档 ID 列表得到文档信息,msearch 是根据查询条件,搜索到相关文档。
批量操作(_bulk,_mget,_msearch),如果将索引(index)写在 URL 中,那么 body 中如果没有指明 index 的话,默认就是 URL 中的 index,反之 body 中指明的 index 是什么,后面的操作就是基于这个 index 的,如下:

也就是说,批量操作命令的基本语法是:
headerbodyheaderbod
4. 常见错误返回
问题 | 原因 |
无法连接 | 网络故障或 ES 集群挂了 |
连接无法关闭 | 网络故障或节点出错 |
429 | 集群过于繁忙 |
4xx | 请求体格式有错 |
500 | 集群内部错误 |
