




Postgres-XL分布式事务介绍一:Postgres-XL分布式事务实现一
三、Postgres-XL分布式事务处理流程
下面将结合报文,来详细说明下coordinate和datanode在pgxl实现分布式事务处理中所扮演的角色和流程。 为了实现分布式事务,所以有些流程是各datanode同时执行完成且成功后才进行下一步操作,有些是单个datanode执行成功后,才会让其他datanode挨个执行,直到所有datanode都成功后才会进行下一个操作步骤,故需要务必注意。 注:因为pgxl处理分布式事务,需要gtm、gtm_proxy、coordinate、datanode相互配合才能够实现,而其流程也很复杂,故此处先介绍coordinate和datanode在分布式事务中所扮演的角色和流程,后续在介绍四者在分布式事务中所涉及的流程。
3.1 所有参与的datanode都fork出数据协调进程
当在pg1的coordinate节点执行insert操作后,coordinate进程会fork出一个子进程cn1_pgxl,让其处理insert操作,cn1_pgxl会分析insert语句,生成执行计划,然后将计划传递给所有涉及的数据节点实际执行。 前提条件:
insert操作是在pg1的coord1上执行;
insert操作涉及到dn1(在pg1主机上)、dn2(在pg2主机上)、dn3(在pg3主机上),共三个datanode节点;
insert语句为简单插入操作,插入10条数据,不涉及表连接等操作,命令如下:
insert into test_hash select generate_series(1,10),random_string(3);此过程的的具体步骤如下所示,流程见下图所示:
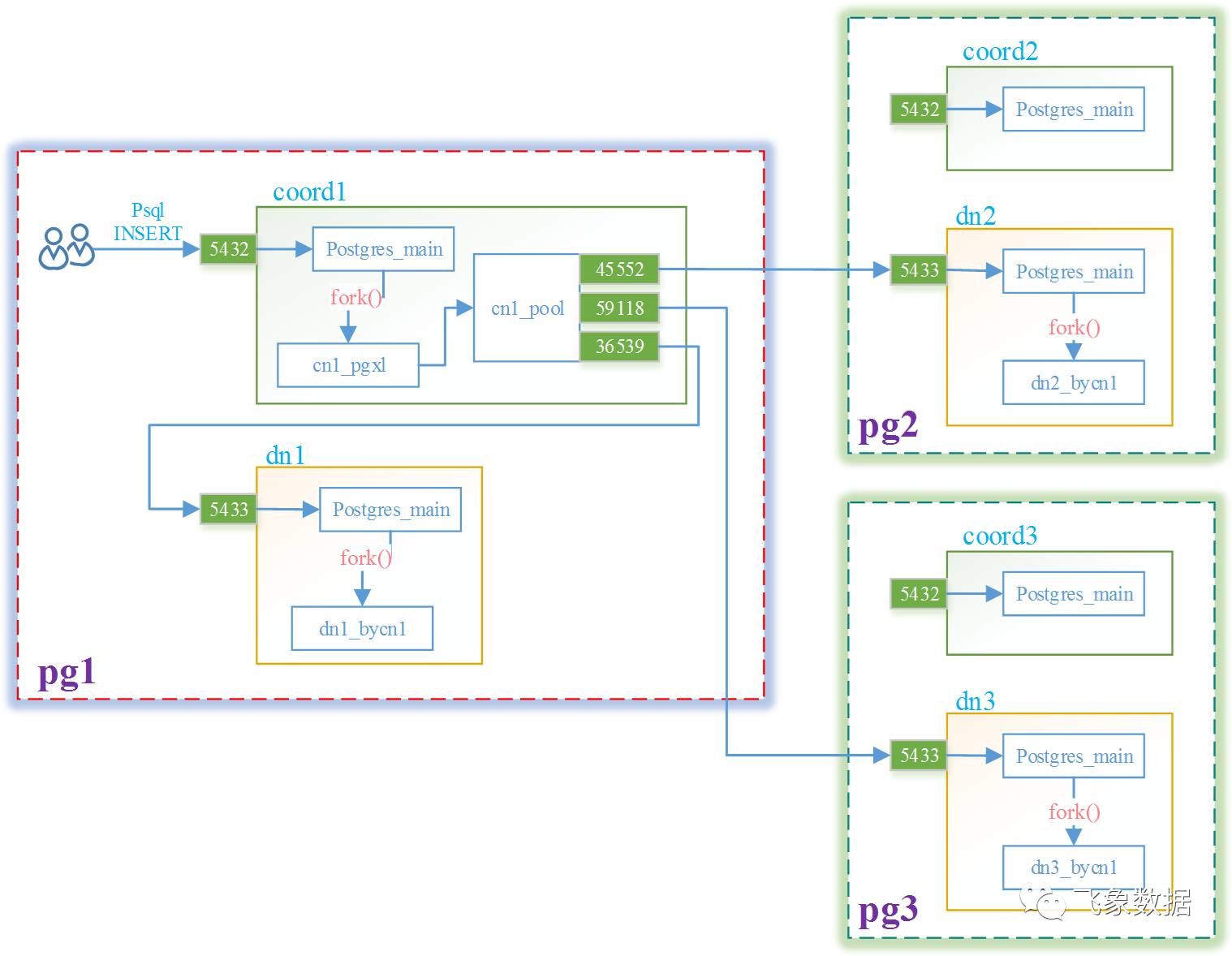
步骤1、在pg1上通过psql连接5432端口,此时coord1因为在监听5432端口,故一收到连接请求响应后,若发现是新的连接请求,则会fork出一个子进程cn1_pgxl,让其处理该连接请求;
步骤2、执行insert命令,cn1_pgxl会分析insert语句,生成执行计划Plan_cn;
步骤3、如果发现该计划需要三个datanode参与,则会向coord1的连接池cn1_pool中选择三个空闲连接(若没有则新建,此处三个连接的监听端口分别为36539、45552和59118),使其分别连接dn1、dn2、dn3的监听端口(此处5433);
步骤4、在dn1、dn2、dn3接到其5433端口上有连接请求时,在校验无误后,都将各自fork出一个子进程用于处
注1:此处dn1_bycn1、dn2_bycn1、dn3_bycn1三个子进程,是为实现分布式事务两阶段提交中最后一步提交操作,同时他们也会在某些特定情况下生成执行计划(后面会叙述)。
3.2 cn1_pgxl向所有参与的数据协调进程发送执行计划
因为 cn1_pgxl和 dn1_bycn1之间的数据交互是pg1内部流程,无法根据报文分析,但是其过程类似于cn1_pgxl 与 dn2_bycn、dn3_bycn1之间的操作,故后续都将用cn1_pgxl 与 dn2_bycn、dn3_bycn1之间的数据交互来说明pgxl的分布式事务过程。
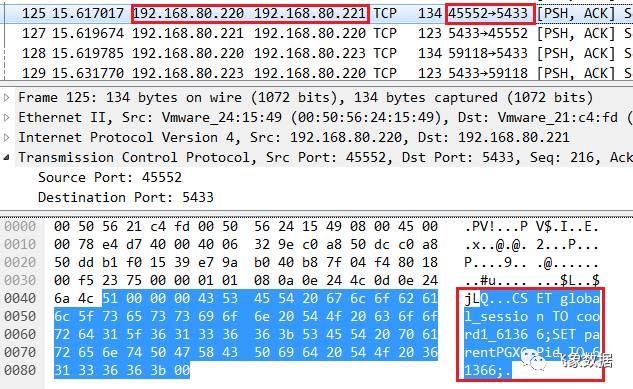
步骤一、pg1的cn1_pgxl进程通过cn1_pool向pg2的dn2_bycn1 发送如下命令,用于设置global_session和parentPGXCPid(即cn1_pgxl的pid):
SET global_session TO coord1_61366; SET parentPGXCPid TO 61366;报文如下:
步骤二、dn2_bycn1设置成功后返回成功标志给cn1_pgxl,cn1_pgxl收到该成功标志后,重复步骤1对pg3的dn3_bycn1进行相同操作。
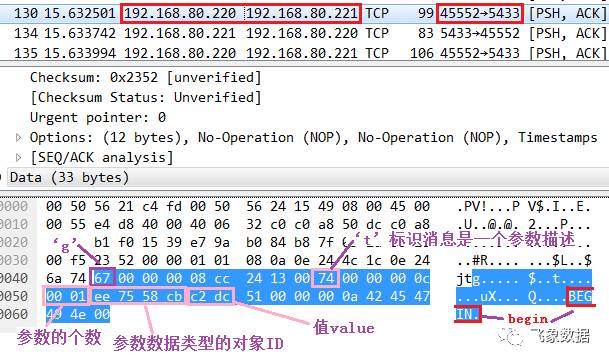
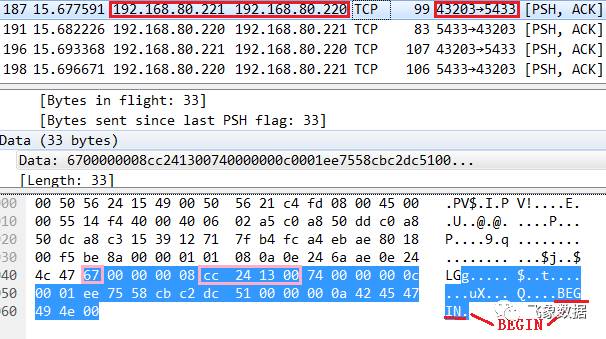
步骤三、pg1的cn1_pgxl向dn2_bycn1发送“BEGIN”,标志开始一个事务(报文如下),若开启事务成功后,dn2_bycn1会通过‘C’ 返回begin命令结束响应,以便进行下一步流程。
步骤四、pg1的cn1_pgxl向dn2_bycn1发送设置局部coordinator_lxid变量的操作,发送命令如下,设置成功后,dn2_bycn1会返回成功响应。
SET LOCAL coordinator_lxid TO "9";
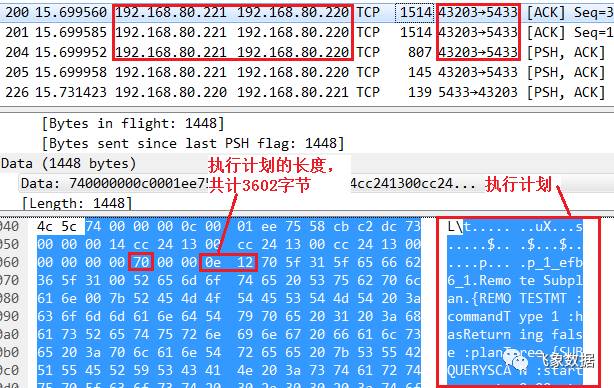
步骤五、pg1的cn1_pgxl向dn2_bycn1发送执行计划Plan_cn,如下图所示,cn1_pgxl发送完执行计划后,并不等待dn2_bycn1的响应数据,而是直接进行后续流程(转为和pg3通信); 注意下图绿色框中的“Ack=503”,在后续dn2_bycn1将insert操作完成后会用该连接将响应数据返回;
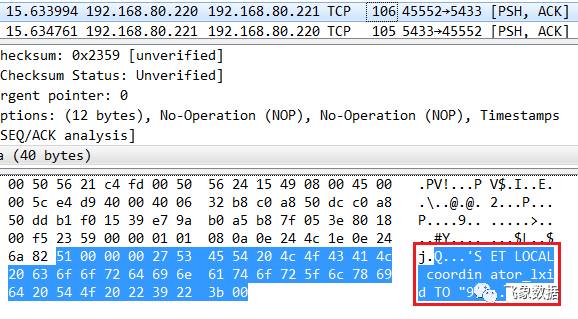
步骤六、pg1的cn1_pgxl转为向pg3的dn3_bycn1通信,重复执行前面的步骤三、步骤四和步骤五;
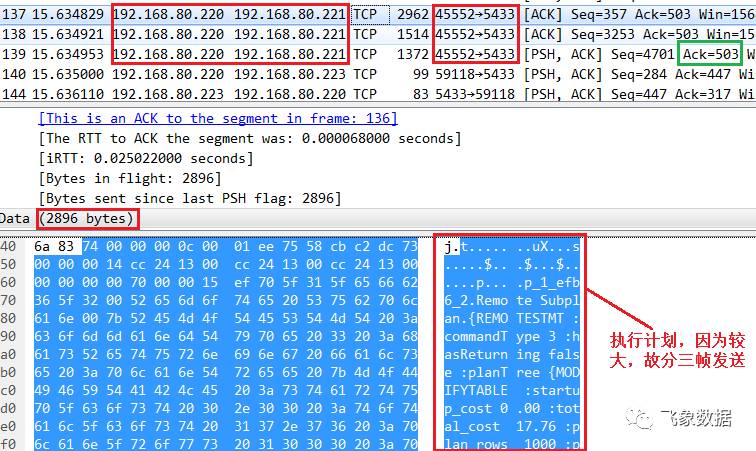
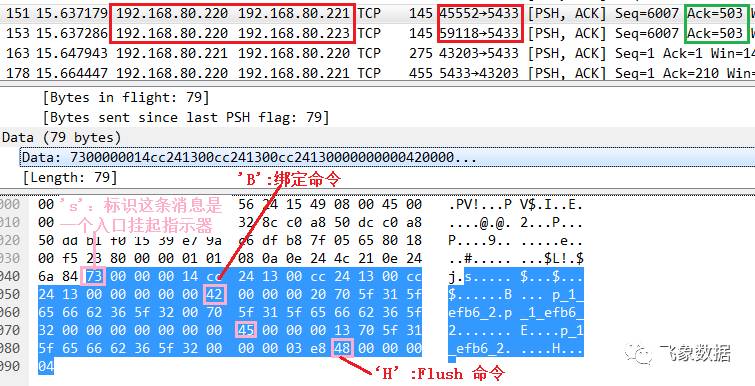
步骤七、pg1的cn1_pgxl同时向pg2的dn2_bycn1和pg3的dn3_bycn1方式入口挂起、bind操作和flush命令,此时pg2和pg3并不会立即返回响应,报文如下; 注意下图绿色框中的“Ack=503”,在后续dn2_bycn1和dn3_bycn1将insert操作完成后会用该连接将响应数据返回;
3.3 所有参与的数据协调进程和主datanode连接
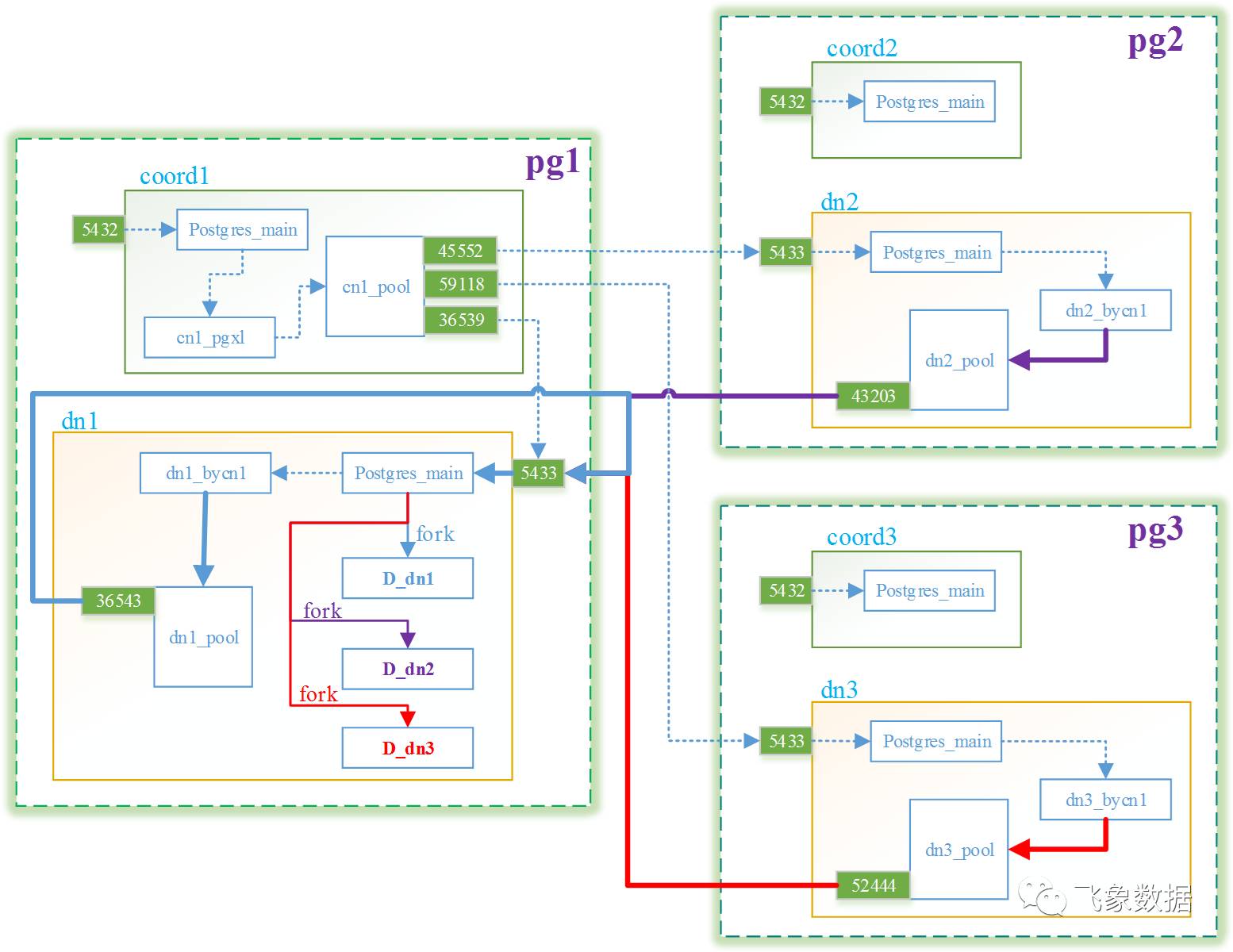
在所有参与的数据协调进程dn_bycn都接收到cn1_pgxl的执行计划Plan_cn后,他们会依据执行计划,结合本节点数据分布,重新生成一个执行计划Plan_dn,并且为了保证事务的一致性,故他们会共同选举产生一个主datanode,然后分别和主datanode进行连接,以便主datanode会分别fork出一个子进程D_dn(本文称之为数据处理进程)。 接着每个dn_bycn都分别将执行计划Plan_dn发给对应的D_dn进程,每个D_dn进程相互配合,共同完成insert数据处理操作,并且将最终每个节点需要插入的数据返回给对应的dn_bycn,以便完成分布式两阶段提交中的前期准备过程。 如下图所示,虚线数据流向为3.1节的,蓝、紫、红三条粗实线即为本节所示的数据流向,可以看出,此时主datanode为dn1,它fork出的三个数据处理进程分别为D_dn1、D_dn2和D_dn3。 注:下图中端口号36543、43203、52444分别为dn1_pool、dn2_pool、dn3_pool三个连接池的监听端口号。
步骤一、pg2的数据协调进程dn2_bycn1,在dn2_pool上获取一个空闲连接(没有就新创建,此处端口号为:43203),然后用该连接连接pg1的5433端口。
步骤二、此时coord1因为在监听5433端口,故一收到连接请求响应后,若发现是新的连接请求,则会fork出一个子进程D_dn2,让其处理该连接请求(见图十二所示紫色实线);
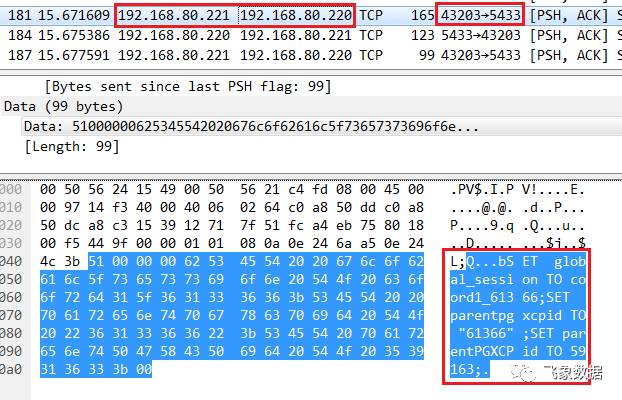
步骤三、dn2_bycn1会向D_dn2发送“SET”命令,用于设置global_session、parentpgxcpid和parentPGXCPid;如下所示,D_dn2设置成功后返回响应:
SET global_session TO coord1_61366; SET parentpgxcpid TO "61366";SET parentPGXCPid TO 59163;
步骤四、dn2_bycn1向g1的D_dn2发送“BEGIN”,标志开始一个事务(报文如下),若开启事务成功后,D_dn2会通过‘C’ 消息返回begin命令结束响应,以便进行下一步流程。
步骤五、pg2的 dn2_bycn1向pg1的D_dn2发送设置局部coordinator_lxid变量的操作,发送命令如下,设置成功后,D_dn2会返回成功响应。
SET LOCAL coordinator_lxid TO "14";
步骤六、pg2的 dn2_bycn1向pg1的D_dn2发送执行计划Plan_dn,如下图所示,因为报文太大,故分为三帧发送:
步骤七、pg2的 dn2_bycn1向pg1的D_dn2发送入口挂起、bind操作和flush命令,如下图所示,图中各字段含义参见上面的图十一,但有点不同的时,此处dn2_bycn1会等待D_dn2处理完执行计划Plan_dn,:
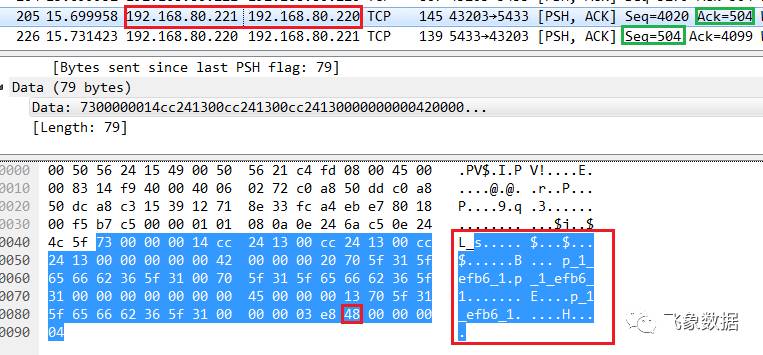
步骤八、D_dn2处理完执行计划Plan_dn后,会将需要插入到dn2上的数据发送给pg2的 dn2_bycn1,此处dn2的表test_hash中会插入三行数据:
步骤九、pg2的 dn2_bycn1向pg1的D_dn2发送关闭预备语句和入口命令(在步骤七中创建的),如下所示,D_dn2关闭成功后返回响应:
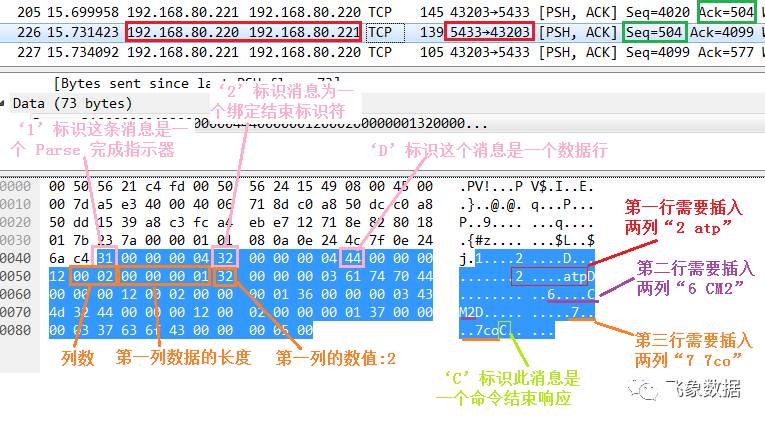
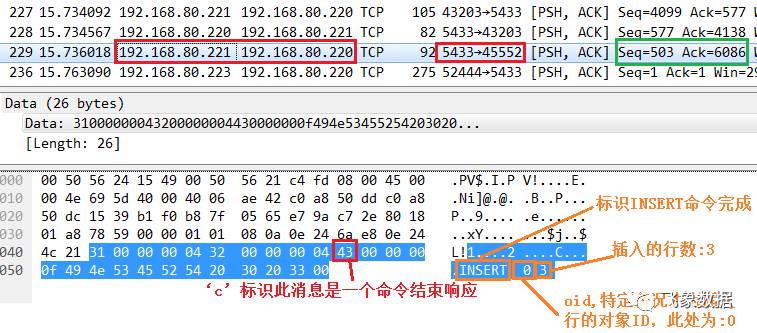
步骤十、pg2的dn2_bycn1发送给pg1的cn1_pgxl进程INSERT命令完成消息,并告知插入的行数为“3”,如下图所示: 注意:下图绿色框中的“Seq=503”,以及此处的端口号“pg2:5433 -> pg1:45552”,该报文为3.2节步骤五的响应,即执行计划Plan_cn的处理结果。 这样实际上也表明对于dn2而言,其所负责的分布式事务二阶段提交过程中,其前期prepare处理阶段已经基本完成,因为实际需要下表的数据都已经获得,只差commit。
步骤十一、对于pg3和pg1的数据协调进程dn2_bycn1、dn1_bycn1,也同样按照步骤一到步骤十的流程,最终每个dn上都获取了需要插入的数据,至此,分布式事务二阶段提交的前期准备操作完成


扫码关注了解更多

