





TX云的ClickHouse开始内测了,名字叫 TDSQL-A for ClickHouse(一切皆TDSQL)。
看了看介绍,据说有针对专用硬件做了优化,并完善了高可用和云上托管能力,最重要的是支持自家的数据传输服务DTS。
产品目前还属于内测阶段,需开通白名单才能使用。
测试版在功能上还是有点限制的:
每个UIN,在每地域,购买的实例不能超过3个。
不支持升降级,包括水平和垂直升降级。
不支持用户账号名、密码、权限的添加、修改和删除。
不支持网络配置修改。
不支持ClickHouse基于xml的设置,包括运行参数。
不支持回收站,删除实例前请多次确认。
以上如需要调整,都需要TX工程师后台处理。
在使用上,也是建议直接写分布式表,不建议写本地表。最低单分片双副本实例,需要使用replicated* 相关表。
本着互联网 开放(不用白不用)的精神,免费的资源闲着不用就是浪费。下面就试试看这个增强版CH的火力猛不猛。
1-资源申请
当前的内测环境的版本只有一个:20.3.10.75
对应社区版是去年5月(当前社区版最新21.6.6.51)
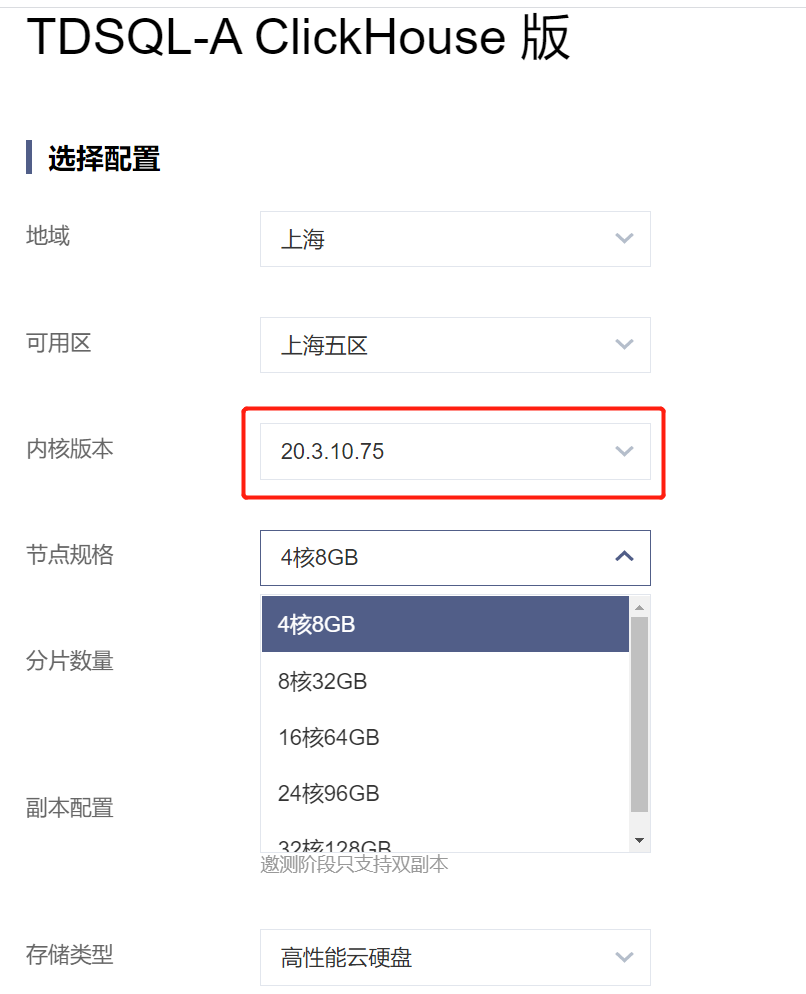
至于配置,毕竟免费的,不超过8C32就好。
为了方便对比,搞了单分片、3分片、15分片共三套做AB。
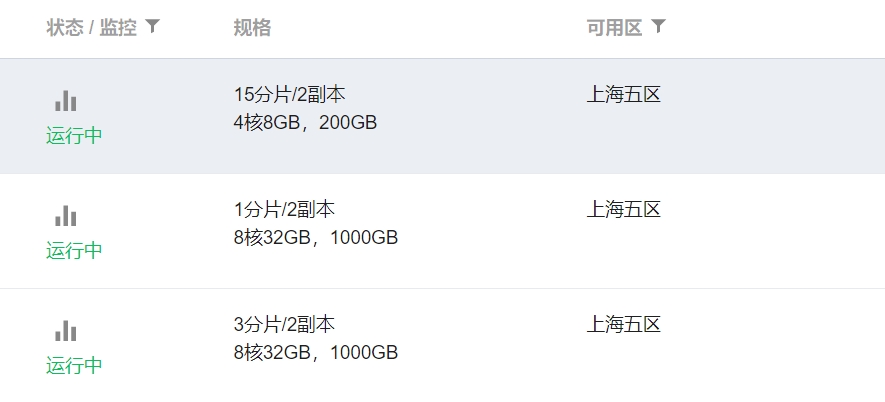
3分片,2副本的经典结构:

15分片就更多了
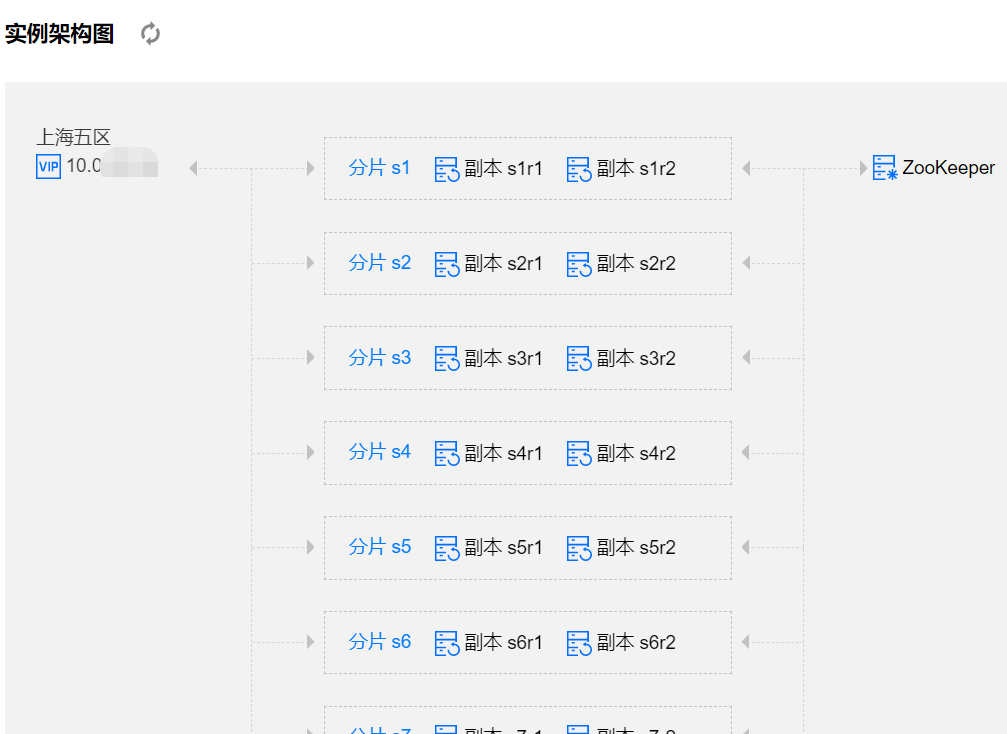
2-控制台功能
控制台四大金刚:

# 账号管理:
目前比较基础,还没有资源控制和熔断阈值之类的东西。不清楚能否通过SQL命令行方式配置,但估计后期肯定会完善。

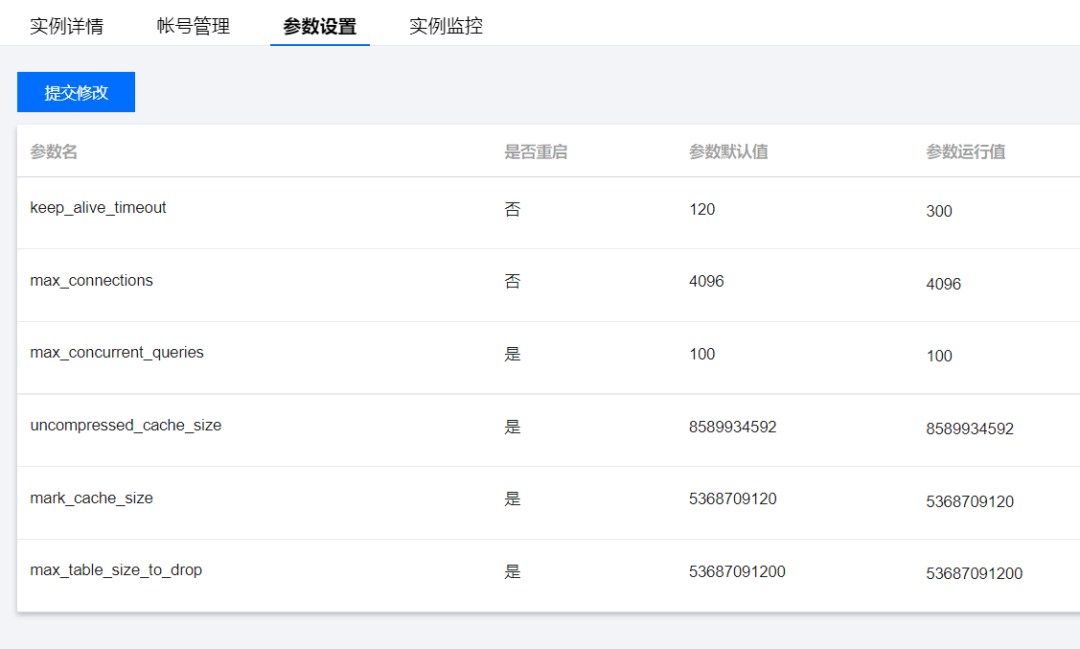
# 参数设置:
可调整的参数--有6个之多,可见测试阶段限制还是比较严格
# 实例监控:
指标比较全面,包括ZK和各个节点的。基本可以覆盖日常管理所需。
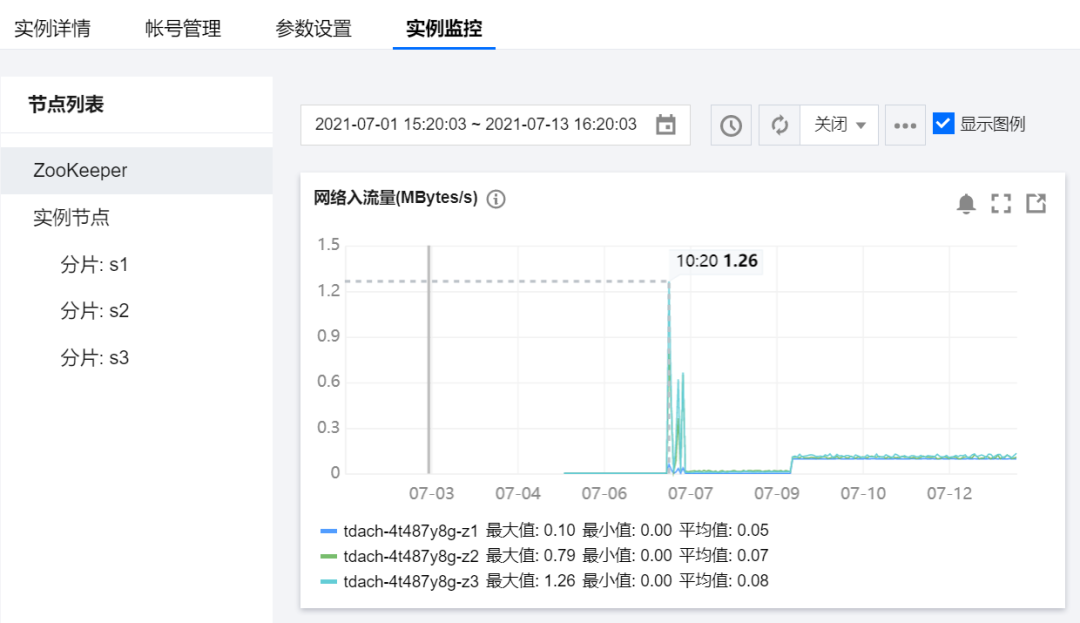
CH专属指标,还是很重要的
3-性能测试
主要还是使用官方的TPC-H测试,按里面的步骤一步一步来就可以了。
https://clickhouse.tech/docs/en/getting-started/example-datasets/star-schema/
这里需要注意,TDSQL-A CH中使用常规SQL建库表,会发生表或是数据丢失!
这是因为TDSQL-A ClickHouse对外连接的地址,是按照负载均衡原则,随机接入集群任意节点的。如果只使用不带副本的本地表,当下一个会话被派发到其他节点时,是无法获取到上一个节点的库表。
TDSQL-A CH 创建库表要遵循以下原则:
必须使用Replicated引擎族,即选择的引擎需支持副本。
必须使用Distributed表做数据操作。
使用ON CLUSTER default_cluster语法。
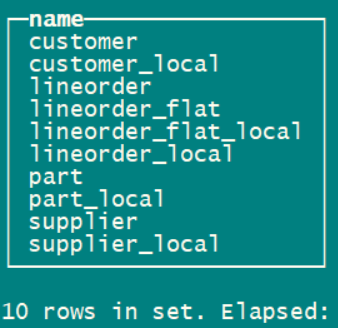
因此测试使用的建表SQL要全部改写成分布表。由于SQL比较多,我放在了最后【建表SQL】里。大家可以直接使用。 最后是5张本地表,5张分布表:
测试环境配置:
1分片/2副本: 8核32GB
3分片/2副本: 8核32GB
15分片/2副本: 4核8GB
数据量: 6亿
TPC-H测试结果对比:(单位-秒)
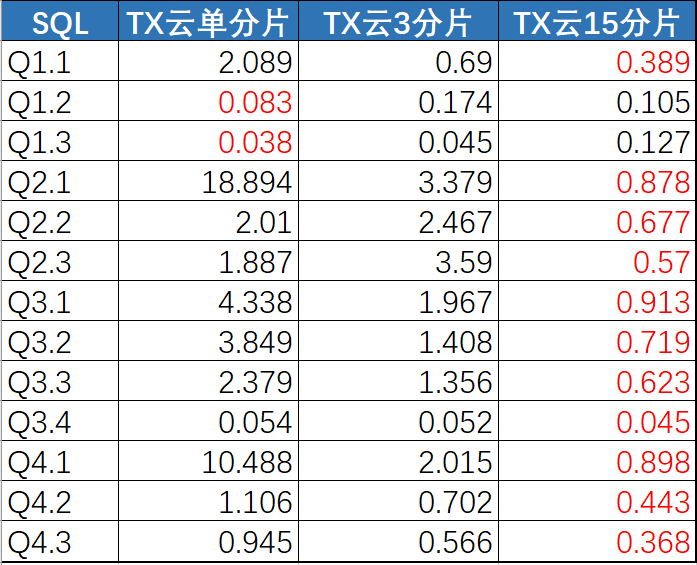
腾讯官方测试结果,还是比较接近:
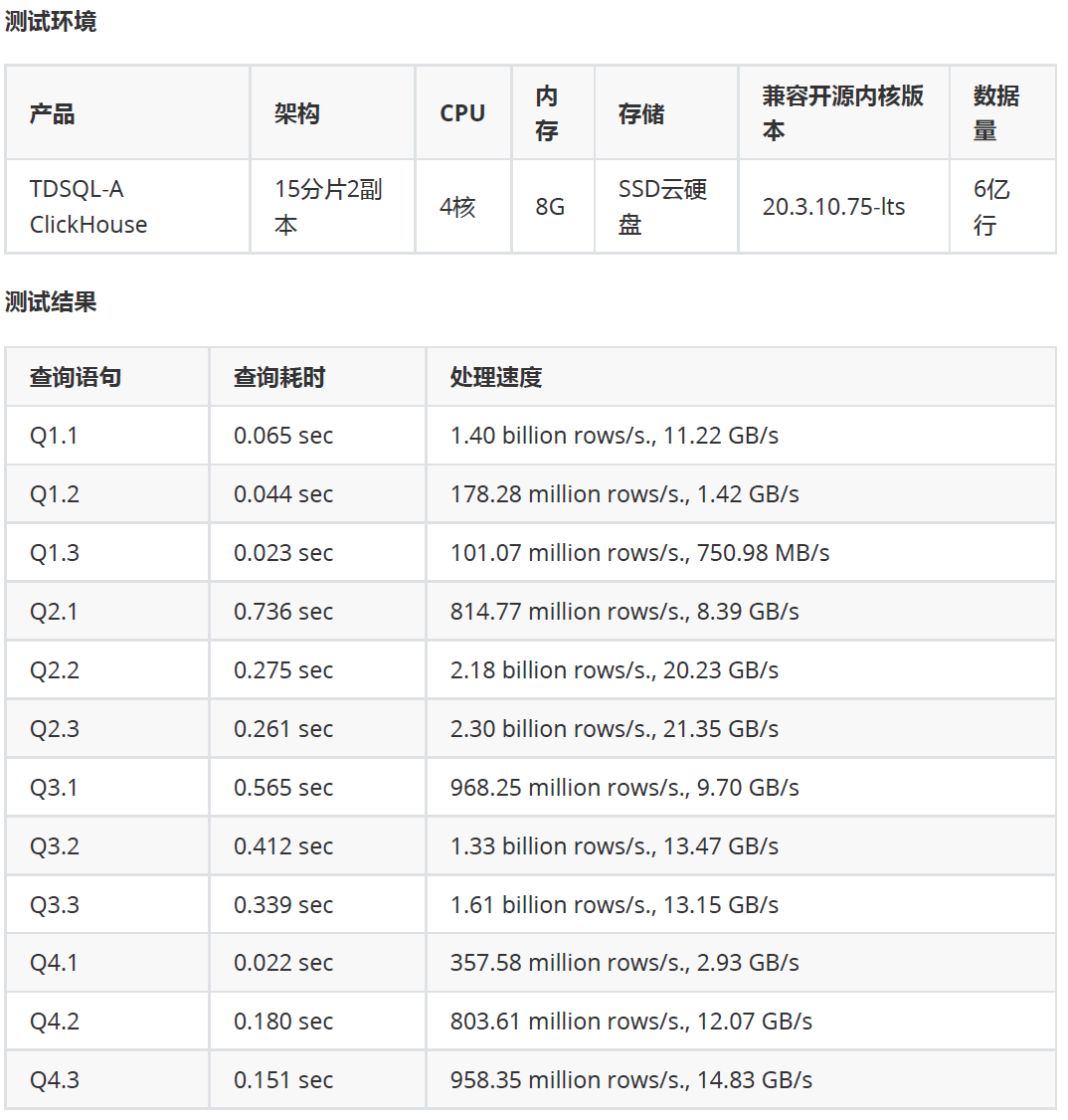
再对比下相同云平台自建库单分片(数据来自叶老师的文章)
https://blog.csdn.net/n88Lpo/article/details/105172774

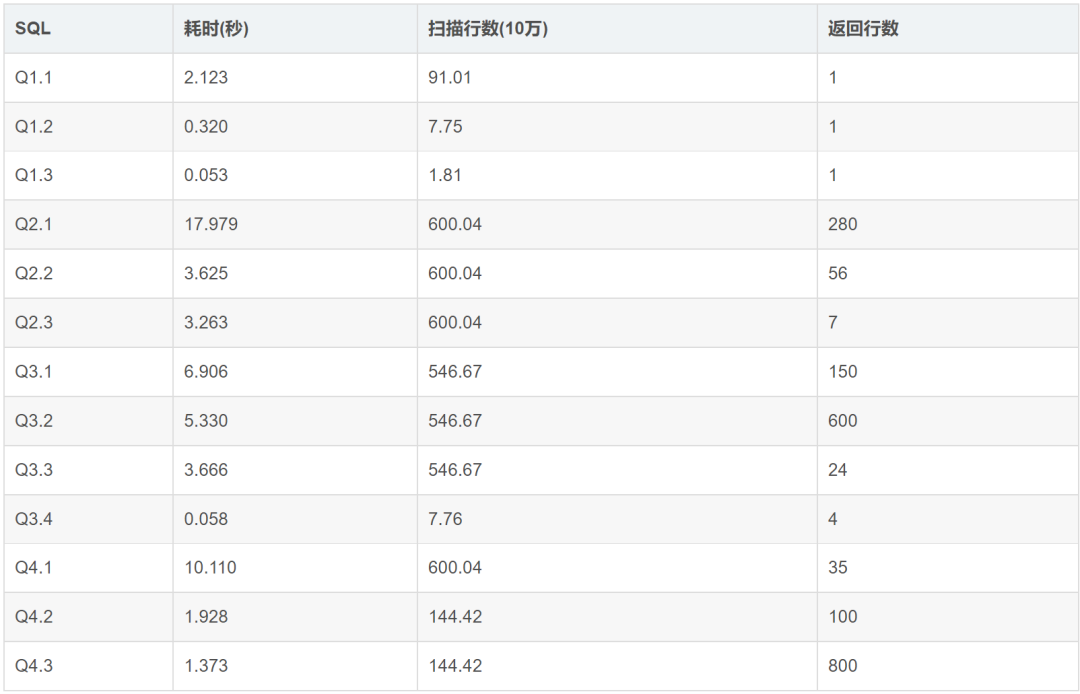
可以看到同样是单分片下,TDSQL-A对比自建还是有一些提升的。
总结
对比自建,TDSQL-A的性能明显更好一些。
限制只能采用分布表,分片数量对性能提升明显,类似多节点并行计算。注意分区键、排序字段和分片设计很重要。当然也要注意用户资源配额和各种阈值限制,避免资源争用。
需注意分布表的通病,比如in字句的查询放大问题、zk性能瓶颈等。
作为一款封装的企业级产品,目前测试版开放给用户的可调整资源不是很多。
阅读到此的你辛苦了

附:建表SQL
# 1 建本地表:
clickhouse-2.khaos.tdach-4t487y8g.svc.cluster.local :) select cluster,host_name,port,user,shard_num,replica_num,is_local from system.clusters where cluster='default_cluster';
SELECT
cluster,
host_name,
port,
user,
shard_num,
replica_num,
is_local
FROM system.clusters
WHERE cluster = 'default_cluster'
┌─cluster─────────┬─host_name───────────────────────────────────────────┬─port─┬─user──────────────┬─shard_num─┬─replica_num─┬─is_local─┐
│ default_cluster │ clickhouse-0.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 1 │ 1 │ 0 │
│ default_cluster │ clickhouse-1.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 1 │ 2 │ 0 │
│ default_cluster │ clickhouse-2.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 2 │ 1 │ 1 │
│ default_cluster │ clickhouse-3.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 2 │ 2 │ 0 │
│ default_cluster │ clickhouse-4.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 3 │ 1 │ 0 │
│ default_cluster │ clickhouse-5.khaos.tdach-4t487y8g.svc.cluster.local │ 9000 │ tencentroot_inner │ 3 │ 2 │ 0 │
└─────────────────┴─────────────────────────────────────────────────────┴──────┴───────────────────┴───────────┴─────────────┴──────────┘
6 rows in set. Elapsed: 0.006 sec.
clickhouse-2.khaos.tdach-4t487y8g.svc.cluster.local :)
# 建立分片库 Database
CREATE DATABASE txtest ON CLUSTER default_cluster;
use txtest;
# 创建ReplicatedMergeTree本地表
CREATE TABLE txtest.customer_local on cluster default_cluster
(
C_CUSTKEY UInt32,
C_NAME String,
C_ADDRESS String,
C_CITY LowCardinality(String),
C_NATION LowCardinality(String),
C_REGION LowCardinality(String),
C_PHONE String,
C_MKTSEGMENT LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/txtest/tables/customer_local/{shard}','{replica}') order by (C_CUSTKEY);
CREATE TABLE txtest.lineorder_local on cluster default_cluster
(
LO_ORDERKEY UInt32,
LO_LINENUMBER UInt8,
LO_CUSTKEY UInt32,
LO_PARTKEY UInt32,
LO_SUPPKEY UInt32,
LO_ORDERDATE Date,
LO_ORDERPRIORITY LowCardinality(String),
LO_SHIPPRIORITY UInt8,
LO_QUANTITY UInt8,
LO_EXTENDEDPRICE UInt32,
LO_ORDTOTALPRICE UInt32,
LO_DISCOUNT UInt8,
LO_REVENUE UInt32,
LO_SUPPLYCOST UInt32,
LO_TAX UInt8,
LO_COMMITDATE Date,
LO_SHIPMODE LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/txtest/tables/lineorder_local/{shard}','{replica}') PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY);
CREATE TABLE txtest.part_local on cluster default_cluster
(
P_PARTKEY UInt32,
P_NAME String,
P_MFGR LowCardinality(String),
P_CATEGORY LowCardinality(String),
P_BRAND LowCardinality(String),
P_COLOR LowCardinality(String),
P_TYPE LowCardinality(String),
P_SIZE UInt8,
P_CONTAINER LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/txtest/tables/part_local/{shard}','{replica}') ORDER BY P_PARTKEY;
CREATE TABLE txtest.supplier_local on cluster default_cluster
(
S_SUPPKEY UInt32,
S_NAME String,
S_ADDRESS String,
S_CITY LowCardinality(String),
S_NATION LowCardinality(String),
S_REGION LowCardinality(String),
S_PHONE String
)
ENGINE = ReplicatedMergeTree('/clickhouse/txtest/tables/supplier_local/{shard}','{replica}') ORDER BY S_SUPPKEY;
# 2 创建本地表的Distributed表
CREATE TABLE txtest.customer on cluster default_cluster
as txtest.customer_local ENGINE = Distributed(default_cluster, txtest, customer_local, C_CUSTKEY);
CREATE TABLE txtest.lineorder on cluster default_cluster
as txtest.lineorder_local ENGINE = Distributed(default_cluster, txtest, lineorder_local, rand());
CREATE TABLE txtest.part on cluster default_cluster
as txtest.part_local ENGINE = Distributed(default_cluster, txtest, part_local, P_PARTKEY);
CREATE TABLE txtest.supplier on cluster default_cluster
as txtest.supplier_local ENGINE = Distributed(default_cluster, txtest, supplier_local, S_SUPPKEY);
# 3 数据导入:(最后一个大概要22m)
clickhouse-client -h 10.*.*.* -u axtest --password *** -d txtest --query "INSERT INTO customer FORMAT CSV" < customer.tbl
clickhouse-client -h 10.*.*.* -u axtest --password *** -d txtest --query "INSERT INTO part FORMAT CSV" < part.tbl
clickhouse-client -h 10.*.*.* -u axtest --password *** -d txtest --query "INSERT INTO supplier FORMAT CSV" < supplier.tbl
clickhouse-client -h 10.*.*.* -u axtest --password *** -d txtest --query "INSERT INTO lineorder FORMAT CSV" < lineorder.tbl
# 宽表数据处理:
# 建立空的本地宽表
SET max_memory_usage = 20000000000;
CREATE TABLE txtest.lineorder_flat_local on cluster default_cluster
ENGINE = ReplicatedMergeTree('/clickhouse/txtest/tables/lineorder_flat_local/{shard}','{replica}')
PARTITION BY toYear(LO_ORDERDATE)
ORDER BY (LO_ORDERDATE, LO_ORDERKEY)
AS
SELECT
l.LO_ORDERKEY AS LO_ORDERKEY,
l.LO_LINENUMBER AS LO_LINENUMBER,
l.LO_CUSTKEY AS LO_CUSTKEY,
l.LO_PARTKEY AS LO_PARTKEY,
l.LO_SUPPKEY AS LO_SUPPKEY,
l.LO_ORDERDATE AS LO_ORDERDATE,
l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,
l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,
l.LO_QUANTITY AS LO_QUANTITY,
l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,
l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,
l.LO_DISCOUNT AS LO_DISCOUNT,
l.LO_REVENUE AS LO_REVENUE,
l.LO_SUPPLYCOST AS LO_SUPPLYCOST,
l.LO_TAX AS LO_TAX,
l.LO_COMMITDATE AS LO_COMMITDATE,
l.LO_SHIPMODE AS LO_SHIPMODE,
c.C_NAME AS C_NAME,
c.C_ADDRESS AS C_ADDRESS,
c.C_CITY AS C_CITY,
c.C_NATION AS C_NATION,
c.C_REGION AS C_REGION,
c.C_PHONE AS C_PHONE,
c.C_MKTSEGMENT AS C_MKTSEGMENT,
s.S_NAME AS S_NAME,
s.S_ADDRESS AS S_ADDRESS,
s.S_CITY AS S_CITY,
s.S_NATION AS S_NATION,
s.S_REGION AS S_REGION,
s.S_PHONE AS S_PHONE,
p.P_NAME AS P_NAME,
p.P_MFGR AS P_MFGR,
p.P_CATEGORY AS P_CATEGORY,
p.P_BRAND AS P_BRAND,
p.P_COLOR AS P_COLOR,
p.P_TYPE AS P_TYPE,
p.P_SIZE AS P_SIZE,
p.P_CONTAINER AS P_CONTAINER
FROM txtest.lineorder AS l
INNER JOIN txtest.customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN txtest.supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN txtest.part AS p ON p.P_PARTKEY = l.LO_PARTKEY where 1=2;
# 建立分布宽表
CREATE TABLE txtest.lineorder_flat on cluster default_cluster
as txtest.lineorder_flat_local ENGINE = Distributed(default_cluster, txtest, lineorder_flat_local, rand());
# 向分布宽表中插入数据
insert into txtest.lineorder_flat
SELECT
l.LO_ORDERKEY AS LO_ORDERKEY,
l.LO_LINENUMBER AS LO_LINENUMBER,
l.LO_CUSTKEY AS LO_CUSTKEY,
l.LO_PARTKEY AS LO_PARTKEY,
l.LO_SUPPKEY AS LO_SUPPKEY,
l.LO_ORDERDATE AS LO_ORDERDATE,
l.LO_ORDERPRIORITY AS LO_ORDERPRIORITY,
l.LO_SHIPPRIORITY AS LO_SHIPPRIORITY,
l.LO_QUANTITY AS LO_QUANTITY,
l.LO_EXTENDEDPRICE AS LO_EXTENDEDPRICE,
l.LO_ORDTOTALPRICE AS LO_ORDTOTALPRICE,
l.LO_DISCOUNT AS LO_DISCOUNT,
l.LO_REVENUE AS LO_REVENUE,
l.LO_SUPPLYCOST AS LO_SUPPLYCOST,
l.LO_TAX AS LO_TAX,
l.LO_COMMITDATE AS LO_COMMITDATE,
l.LO_SHIPMODE AS LO_SHIPMODE,
c.C_NAME AS C_NAME,
c.C_ADDRESS AS C_ADDRESS,
c.C_CITY AS C_CITY,
c.C_NATION AS C_NATION,
c.C_REGION AS C_REGION,
c.C_PHONE AS C_PHONE,
c.C_MKTSEGMENT AS C_MKTSEGMENT,
s.S_NAME AS S_NAME,
s.S_ADDRESS AS S_ADDRESS,
s.S_CITY AS S_CITY,
s.S_NATION AS S_NATION,
s.S_REGION AS S_REGION,
s.S_PHONE AS S_PHONE,
p.P_NAME AS P_NAME,
p.P_MFGR AS P_MFGR,
p.P_CATEGORY AS P_CATEGORY,
p.P_BRAND AS P_BRAND,
p.P_COLOR AS P_COLOR,
p.P_TYPE AS P_TYPE,
p.P_SIZE AS P_SIZE,
p.P_CONTAINER AS P_CONTAINER
FROM txtest.lineorder AS l
INNER JOIN txtest.customer AS c ON c.C_CUSTKEY = l.LO_CUSTKEY
INNER JOIN txtest.supplier AS s ON s.S_SUPPKEY = l.LO_SUPPKEY
INNER JOIN txtest.part AS p ON p.P_PARTKEY = l.LO_PARTKEY;
Insert遇到的超时问题:
# 超时问题
Timeout exceeded while receiving data from server. Waited for 18446744073 seconds, timeout is 300 seconds.
Cancelling query.
Ok.
Query was cancelled.
默认超时300秒
select name,value,changed from system.settings where name like '%_timeout';
│ receive_timeout │ 300 │ 0 │
│ send_timeout │ 300 │ 0 │
# 解决方法:修改超时参数(记得执行完改回默认值300)
set receive_timeout=0;
set send_timeout=0;
