




Elasticsearch是一款流行的分布式开源搜索和数据分析引擎,具备高性能、易扩展、容错性强等特点。它强化了Apache Lucene的搜索能力,把掌控海量数据索引和查询的方式提升到一个新的层次。
本文结合开源社区和阿里云平台的实践经验,探讨如何调优Elasticsearch的性能,提高索引和查询吞吐量。
/ 前文回顾
Elasticsearch索引和查询性能调优的21条建议【上】
点击查看大图
查询性能调优建议
01
默认情况下,Elasticsearch的查询会计算返回的每条数据与查询语句的相关度,但对于非全文索引的使用场景,用户并不关心查询结果与查询条件的相关度,只是想精确地查找目标数据。此时,可以通过filter来让Elasticsearch不计算评分,并且尽可能地缓存filter的结果集,供后续包含相同filter的查询使用,提高查询效率。
普通查询
curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d'{"query": {"match": {"user": "kimchy"}}}'
过滤器(filter)查询
curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d'{"query": {"bool": {"filter": {"match": {"user": "kimchy"}}}}}'
分片查询缓存的目的是缓存聚合、提示词结果和命中数(它不会缓存返回的文档,因此,它只在search_type=count时起作用)。
通过下面的参数我们可以设置分片缓存的大小,默认情况下是JVM堆的1%大小,当然我们也可以手动设置在config/elasticsearch.yml文件里:
indices.requests.cache.size: 1%
查看缓存占用内存情况
(name表示节点名, query_cache表示过滤器缓存,request_cache表示分片缓存,fielddata表示字段数据缓存,segments表示索引段)
curl -XGET "http://localhost:9200/_cat/nodes?h=name,query_cache.memory_size,request_cache.memory_size,fielddata.memory_size,segments.memory&v"
02
Elasticsearch写入文档时,文档会通过一个公式路由到一个索引中的一个分片上。默认的公式如下:
shard_num = hash(_routing) % num_primary_shards
_routing字段的取值,默认是_id字段,可以根据业务场景设置经常查询的字段作为路由字段。例如可以考虑将用户id、地区作为路由字段,查询时可以过滤不必要的分片,加快查询速度。
写入时指定路由
curl -XPUT "http://localhost:9200/my_index/my_type/1?routing=user1" -H 'Content-Type: application/json' -d'{"title": "This is a document","author": "user1"}'
查询时不指定路由,需要查询所有分片
curl -XGET "http://localhost:9200/my_index/_search" -H 'Content-Type: application/json' -d'{"query": {"match": {"title": "document"}}}'
返回结果
{"took": 2,"timed_out": false,"_shards": {"total": 5,"successful": 5,"skipped": 0,"failed": 0}......}
查询时指定路由,只需要查询1个分片
curl -XGET "http://localhost:9200/my_index/_search?routing=user1" -H 'Content-Type: application/json' -d'{"query": {"match": {"title": "document"}}}'
返回结果
{"took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0}......}
03
强制合并只读索引
只读索引可以从合并成一个单独的大segment中收益,减少索引碎片,减少JVM堆常驻内存。强制合并索引操作会耗费大量磁盘IO,尽量配置在业务低峰期(例如凌晨)执行。历史数据索引如果业务上不再支持查询请求,可以考虑关闭索引,减少JVM内存占用。
索引forcemerge API
curl -XPOST "http://localhost:9200/abc20180923/_forcemerge?max_num_segments=1"
索引关闭API
curl -XPOST "http://localhost:9200/abc2017*/_close"
04
Elasticsearch内置了很多分词器,包括standard、cjk、nGram等,也可以安装自研/开源分词器。根据业务场景选择合适的分词器,避免全部采用默认standard分词器。
常用分词器:
standard:默认分词,英文按空格切分,中文按照单个汉字切分。
cjk:根据二元索引对中日韩文分词,可以保证查全率。
nGram:可以将英文按照字母切分,结合ES的短语搜索(match_phrase)使用。
IK:比较热门的中文分词,能按照中文语义切分,可以自定义词典。
pinyin:可以让用户输入拼音,就能查找到相关的关键词。
aliws:阿里巴巴自研分词,支持多种模型和分词算法,词库丰富,分词结果准确,适用于电商等对查准要求高的场景。
分词效果测试API
curl -XPOST "http://localhost:9200/_analyze" -H 'Content-Type: application/json' -d'{"analyzer": "ik_max_word","text": "南京市长江大桥"}'
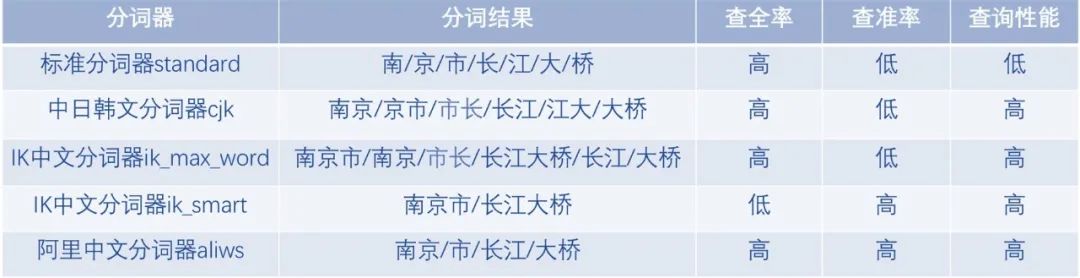
常用中文分词器效果对比
05
查询聚合节点可以发送粒子查询请求到其他节点,收集和合并结果,以及响应发出查询的客户端。通过给查询聚合节点配置更高规格的CPU和内存,可以加快查询运算速度、提升缓存命中率。
某客户使用25台8核CPU32G内存节点Elasticsearch集群,查询QPS在4000左右。增加6台16核CPU32G内存节点作为查询聚合节点,观察服务器CPU、JVM堆内存使用情况,并调整缓存、分片、副本参数,查询QPS达到12000。
# 查询聚合节点配置(conf/elasticsearch.yml):
node.master:false
node.data:false
node.ingest:false
06
默认的查询请求通常返回排序后的前10条记录,最多一次读取10000条记录,通过from和size参数控制读取记录范围,避免一次读取过多的记录。通过_source参数可以控制返回字段信息,尽量避免读取大字段。
查询请求示例
curl -XGET http://localhost:9200/fulltext001/_search?pretty -H 'Content-Type: application/json' -d '{"from": 0,"size": 10,"_source": "id","query": {"bool": {"must": [{"match": {"content":"虎嗅"}}]}},"sort": [{"id": {"order": "asc"}}]}'
07
如果不需要精确统计查询命中记录条数,可以配teminate_after指定每个shard最多匹配N条记录后返回,设置查询超时时间timeout。在查询结果中可以通过“terminated_early”字段标识是否提前结束查询请求。
teminate_after查询语法示例
curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d'{"from": 0,"size": 10,"timeout": "10s","terminate_after": 1000,"query": {"bool": {"filter": {"term": {"user": "elastic"}}}}}'
08
Elasticsearch默认只允许查看排序前10000条的结果,当翻页查看排序靠后的记录时,响应耗时一般较长。使用search_after方式查询会更轻量级,如果每次只需要返回10条结果,则每个shard只需要返回search_after之后的10个结果即可,返回的总数据量只是和shard个数以及本次需要的个数有关,和历史已读取的个数无关。
search_after查询语法示例
curl -XGET "http://localhost:9200/twitter/_search" -H 'Content-Type: application/json' -d'{"size": 10,"query": {"match": {"message": "Elasticsearch"}},"sort": [{"_score": {"order": "desc"}},{"_id": {"order":"asc"}}],"search_after": [0.84290016, //上一次response中某个doc的score"1024" //上一次response中某个doc的id]}'
09
Elasticsearch默认支持通过*?正则表达式来做模糊匹配,如果在一个数据量较大规模的索引上执行模糊匹配,尤其是前缀模糊匹配,通常耗时会比较长,甚至可能导致内存溢出。尽量避免在高并发查询请求的生产环境执行这类操作。
某客户需要对车牌号进行模糊查询,通过查询请求"车牌号:*A8848*"查询时,往往导致整个集群负载较高。通过对数据预处理,增加冗余字段"车牌号.keyword",并事先将所有车牌号按照1元、2元、3元...7元分词后存储至该字段,字段存储内容示例:沪,A,8,4,沪A,A8,88,84,48,沪A8...沪A88488。通过查询"车牌号.keyword:A8848"即可解决原来的性能问题。
10
Elasticsearch6.X之前的版本默认允许在一个index下面创建多个type,Elasticsearch6.X版本只允许创建一个type,Elasticsearch7.X版本只允许type值为“_doc”。在一个索引下面创建多个字段不一样的type,或者将几百个字段不一样的索引合并到一个索引中,会导致索引稀疏问题。
建议每个索引下只创建一个type,字段不一样的数据分别独立创建index,不要合并成一个大索引。每个查询请求根据需要去读取相应的索引,避免查询大索引扫描全部记录,加快查询速度。
11
扩容集群节点个数
通常服务器节点数越多,服务器硬件配置规格越高,Elasticsearch集群的处理能力越强。
在不同节点规模下的查询性能测试
(测试环境:Elasticsearch5.5.3集群,单节点16核CPU、64G内存、2T SSD盘,10亿条人口户籍登记信息,数据大小1TB, 20索引分片)
| 集群节点数 | 副本数 | 10并发检索平均响应时间 | 50并发检索平均响应时间 | 100并发检索平均响应时间 | 200并发检索平均响应时间 | 200并发QPS | 200并发CPU使用率 | 200并发CPUIO等待 |
| 1 | 0 | 77ms | 459ms | 438ms | 1001ms | 200 | 16% | 52% |
| 3 | 0 | 38ms | 103ms | 162ms | 298ms | 669 | 45% | 34% |
| 3 | 2 | 271ms | 356ms | 577ms | 818ms | 244 | 19% | 54% |
| 10 | 0 | 21ms | 36ms | 48ms | 81ms | 2467 | 40% | 10% |
不同集群节点规模写入性能测试
(测试环境:Elasticsearch6.3.2集群,单节点16核CPU、64G内存、2T SSD盘,10亿条人口户籍登记信息,单条记录1KB,数据集大小1TB,20个并发写入线程)
| 集群节点数 | 副本数 | 写入TPS | 耗时 | 集群CPU使用率 |
| 10 | 0 | 88945 | 11242s | 50% |
| 50 | 0 | 180638 | 5535s | 20% |
在条件允许的情况下,建议可以通过实际的数据和使用场景测试出适合自己的最佳实践。得益于阿里云Elasticsearch提供的弹性扩容功能,阿里云Elasticsearch用户可以在实际使用时根据情况随时增加磁盘大小、扩容节点个数、升级节点规格。
< END >
喜欢就点个在看 or 转发个朋友圈呗

衣舞晨风
推荐阅读:
