




计算资源弹性伸缩
Node Group
Node Group在GaussDB 200集群里指DN的集合,是集群中的子集群,从性质上可以分为存储子集群Storage Node Group和计算子集群Computing Node Group,存储节点组用来承载本地表的数据存储,而计算节点组用来承载查询的聚集、关联计算。
Node Group一般由管理员用户通过CREATE NODE GROUP语法进行创建,并通过GRANT语句将Node Group赋予CREATE|COMPUTE的权限把子集群定义为存储、计算子集群。
Node Group创建、维护以及具体使用可参考弹性伸缩管理和CREATE NODE GROUP的相关说明。
在使用CREATE NODE GROUP语句创建节点组时,为充分保证不同Node Group之间作业资源的隔离性,建议用户在DN列表选取时逻辑上以物理节点为单位进行DN组合,并且DN列表需要包含所涉及到的物理节点上的所有DN,如果作为资源隔离的计算组不建议两个Node Group之间有overlap节点,例如有以下4节点集群:
- Node1:{dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008}
- Node2:{dn_6009_6010, dn_6011_6012, dn_6013_6014, dn_6015_6016}
- Node3:{dn_6017_6018, dn_6019_6020, dn_6021_6022, dn_6023_6024}
- Node4:{dn_6025_6026, dn_6027_6028, dn_6029_6030, dn_6031_6032}
建议Node Group的创建为:
- nodegroup1 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6009_6010, dn_6011_6012, dn_6013_6014, dn_6015_6016} ----- 包含node1、node2上的所有DN
- nodegroup2 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6025_6026, dn_6027_6028, dn_6029_6030, dn_6031_6032} ----- 包含node1、node4上的所有DN
不建议Node Group的创建为:
- nodegroup1 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6017_6018, dn_6019_6020} ----- node3上只包含了部分DN
- nodegroup2 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6029_6030, dn_6031_6032} ----- node4上只包含了部分DN
如果考虑Node Group做资源隔离不建议创建为以下形式(node1在两个Node Group中重叠):
- nodegroup1 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6017_6018, dn_6019_6020}
- nodegroup2 {dn_6001_6002, dn_6003_6004, dn_6005_6006, dn_6007_6008, dn_6029_6030, dn_6031_6032}
什么是计算资源弹性伸缩
传统的关系型数据库虽然在数据存储方面占据着不可动摇的地位,但由于其天生的限制(计算和存储强耦合),越来越不能满足云计算下的数据扩展、读写速度、支撑容量以及建设和运营成本的要求,在性能和成本的双重压力之下,数据库在当今云化的大趋势下需要寻找突破之路。鉴于此,当今全球顶级科技互联网企业Google、Facebook、Twitter等纷纷展开探索,当前主流云化分析性数据库主要方案均以“预先分配实例”的本地存储方案为主预先为用户提供存储、计算资源,对于资源按需申请、按需释放的能力存在先天的不足,而计算资源弹性伸缩从MPPDB架构的执行层面提供了一种“运行时变更计算资源的能力”,从根本上解决了MPPDB中计算和存储耦合的局限性,能够将查询的执行运行到指定的Node Group,从而达到计算能力随业务需要动态伸缩。
计算资源弹性伸缩是指能够将用户的查询执行DN数在运行过程中进行变更,即允许用户将查询语句转移到其他业务负载较轻的DN,或者具备更强计算能力的DN执行,从而达到动态变更集群计算的能力。
计算资源弹性伸缩能够解决的问题
计算资源弹性伸缩主要能够为用户解决计算资源隔离、计算资源弹性两个方面的能力,用户通过CREATE NODE GROUP语法创建子集群,对原有物理集群从逻辑切分为不同子业务系统,从而达到物理上隔离为不同业务系统的目的,同时可以将查询的执行动态指定到某一空闲或具备更强处理能力(更多DN或者具备更强CPU、内存的DN)的Node Group子集群上。具体设计思想主要包含下述两方面:
- 提供以子集群为粒度的资源隔离能力:允许表的存储限定在一个特定的子集群内,从物理层面上切分、隔离不同的业务子系统在不同的子集群内,同时对不同的子集群进行权限控制管理,允许查询的执行过程指定到某一个特定的Node Group子集群内。
- 提供系统查询的弹性伸缩能力:允许支持跨Node Group节点组不上抽CN的查询能力,达到集群不扩容瞬间改变集群计算能力,同时也帮助在线扩容过程中对于已完成扩容、未完成扩容的表之间关联查询下推DN执行,提升扩容过程中间状态的查询性能。
如何进行计算资源隔离
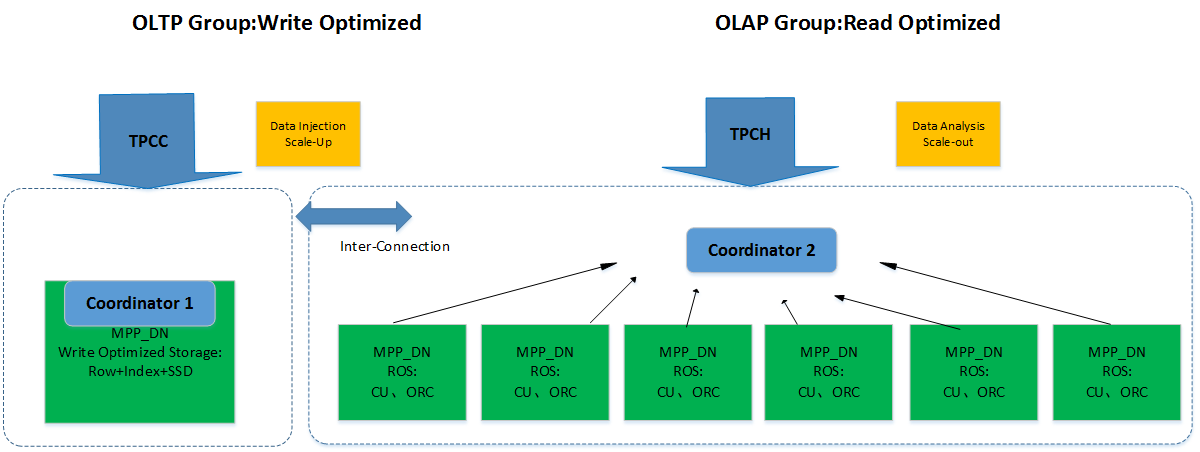
在原有GaussDB 200集群基础上,根据不同的业务负载更进一步切分成子集群Node Group,以作为独立的业务负载服务子系统,用户逻辑层面子系统owner用户能够独立管理该业务系统内部的数据和表对象,数据存储方面能够从物理存储上做到业务系统之间的数据隔离,同时能够独立集群内的用户、对象权限管理,达到跨子集群对象访问控制,如果Node Group的创建考虑到DN和物理节点的对应,Node Group从逻辑上等同于一个小规模的集群,最终达到用户、数据、资源的物理隔离。
例如,在同一套集群负载OLAP、OLTP的子集群环境下,对OLAP和OLTP子集群资源进行隔离,同时根据需要设置跨OLTP、OLAP子集群的访问控制权限,当OLTP或OLAP其中一方业务负荷过重时,可以按照设置的权限调用另一方的资源执行SQL语句。
模式 |
运行结果 |
运行参数 |
|---|---|---|
|
OLAP、OLTP混合模式Without Isolation |
|
TPC-C: 338 TpmC TPC-H: 3603s Cluster unstable during test |
OLAP、OLTP隔离模式With Isolation |
|
TPC-C: 968 TpmC TPC-H: 3625s Cluster running stable |
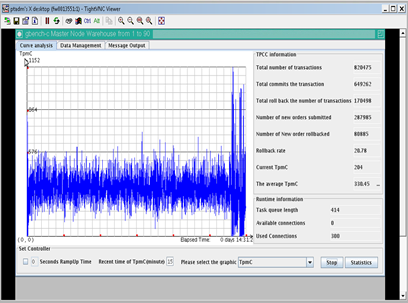
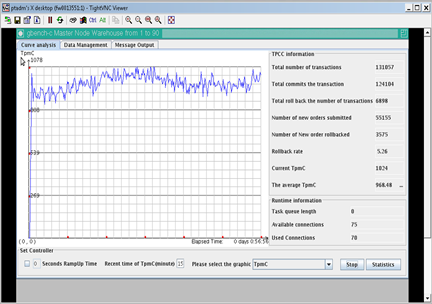
由表1可以看到,分离OLTP、OLAP负载以后OLTP业务的能够获得更高的TPMC,同时也相比混载场景更加稳定。
如何进行计算资源的弹性伸缩
用户需要拥有一个Computing Node Group,通过GUC控制参数expected_computing_nodegroup设置成弹性模式query|optimal,并对该计算子集群限定SQL执行范围,即将SQL的执行指定到某一Node Group,这样能够在不做系统扩容的前提下瞬间达到“扩展计算容量”,达到计算资源弹性伸缩能力。映射到云化场景的DN计算资源节点组或者物理集群场景中,计算资源弹性伸缩能够实现某一子业务系统利用其他较空闲业务子系统的DN计算资源,达到计算资源的合理利用。
弹性计算的模式由GUC参数expected_computing_nodegroup控制,详细介绍请参考expected_computing_nodegroup章节内容。
基于Stream本地表的计算资源弹性场景:在SQL执行过程中通过Stream节点对计算节点组进行扩展获取更高的并行度,从而达到更强的性能。
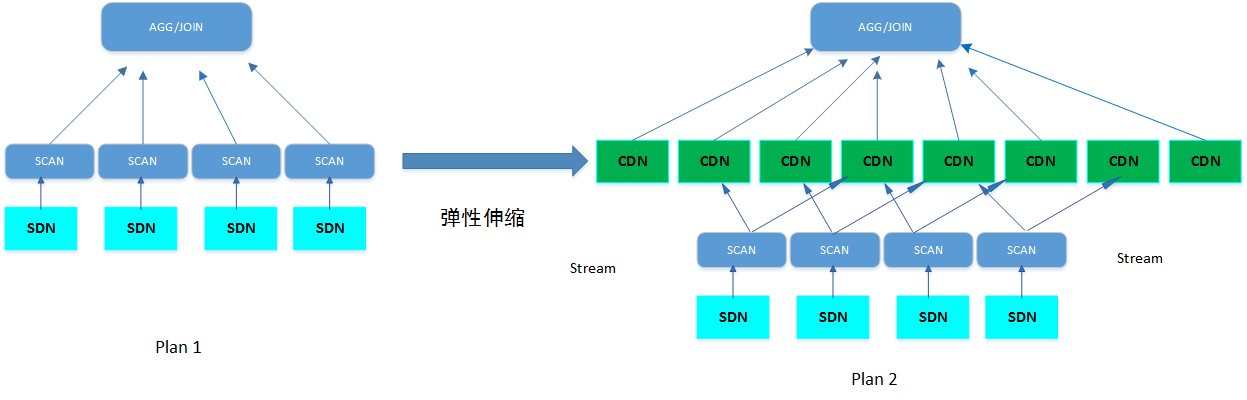
Plan1 |
explain select avg(c3), c1 from t1ng1234 group by c1; QUERY PLAN ---------------------------------------------------------------------- Streaming (type: GATHER) (cost=45.15..10.90 rows=10 width=8) Node/s: datanode1, datanode2 -> HashAggregate (cost=10.15..10.28 rows=10 width=8) Group By Key: c1 -> Seq Scan on t1ng1234 (cost=0.00..10.10 rows=10 width=8) (5 rows) |
Plan2 |
explain select avg(c3), c1 from t1ng1234 group by 2; QUERY PLAN ------------------------------------------------------------------------ Streaming (type: GATHER) (cost=50.69..54.68 rows=120 width=8) Node/s: datanode1, datanode2, datanode3, datanode4, … ,datanode12 -> HashAggregate (cost=46.69..47.18 rows=120 width=8) Group By Key: c1 -> Streaming(type: REDISTRIBUTE) (ngroup12 -> group1) Spawn on: datanode1, datanode2 -> Seq Scan on t1ng1234 (cost=0.00..23.23 rows=10 width=8) |
查看更多:华为GaussDB 200 企业级增强特性
