




全并行的数据查询处理
全并行的分布式查询处理是GaussDB 200中最核心的技术,它可以最大限度的降低查询时节点之间的数据流动,以提升查询效率。
GaussDB 200为达成高性能数据分析目标,实现了一套高性能的分布式执行引擎,执行引擎以SQL引擎生成的执行计划为输入,将元组按执行计划的要求进行加工并将结果返回给客户端。
图1展示了GaussDB 200的全并行分布式查询技术。
图1 分布式查询示意图
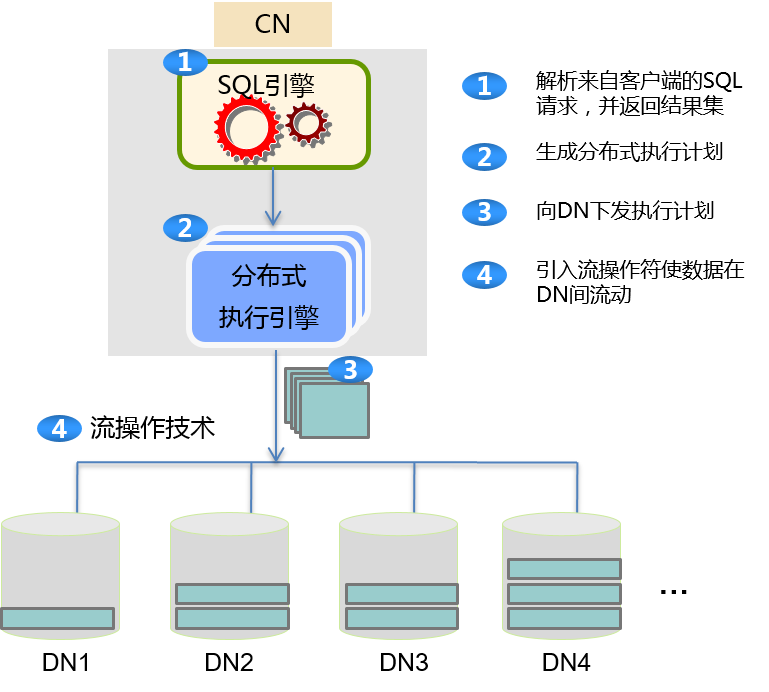
- 运行在CN上的分布式执行引擎实现了分布式执行调度的功能。
- 节点内引入新的执行算子来支撑数据在计算节点之间的流动,这些新的执行算子称其为数据流操作符,根据数据流的输入、输出关系,可以细分为聚合流(Gather)、广播流(Broadcast)和重分布流(Redistribution)。聚合流将数据从多个查询片段聚合到一个。广播流将数据从一个查询片段的数据向多个传输。重分布流则将多个查询片段的数据,按照一定规则重组后向多个传输。
- 跨计算节点的数据传输依赖于查询分析阶段根据数据分布以及代价模型构建的数据流动拓扑结构,并根据此结构来建立节点之间的网络连接,驱动数据流动于此拓扑结构之上。
一个涉及多个执行算子的复杂查询的大概执行过程如下:
- CN接收到查询任务(通常是SQL语句描述)后,对SQL语句进行语法解析并分解出基础的查询和数据处理执行算子,比如DataScan、Sort、Aggregation以及Join。
- 随后CN会生成最优的基础任务执行序列,并将这些基础任务部署到各个节点上去执行。
- 各个DN完成数据处理后,会将结果汇总到CN上并输出到客户端。
查看更多:华为GaussDB 200 企业级增强特性
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
