

2



Postgresql统计信息
5墨值下载

PostgreSQL统计信息
1.数据库统计信息概览
2.pg_stat_database关键指标
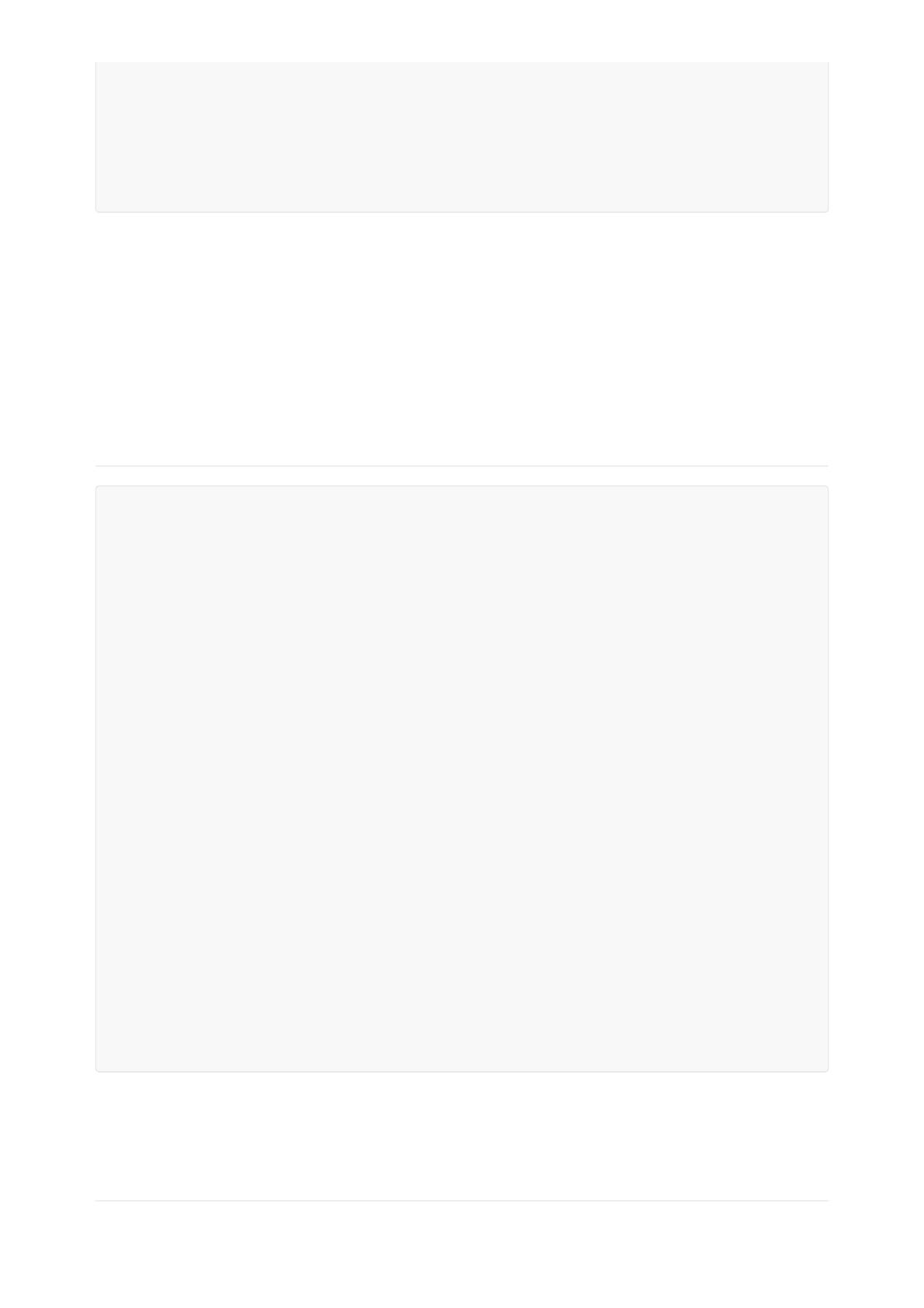
postgres=# select * from pg_stat_database where datname='postgres';
-[ RECORD 1 ]-----+------------------------------
datid | 13510 #数据库oid
datname | postgres #数据库名
numbackends | 98 #访问当前数据库连接数
xact_commit | 14291309 #该数据库事务提交总
xact_rollback | 0 #该数据库事务回滚总
blks_read | 536888 #总磁盘物读的块数,这read也可能是从
page cache读取,如果这很需要结合blk_read_time看是否真的存在很多实际从磁盘读取的情况。
blks_hit | 261717850 #在shared_buffer命中的块数
tup_returned | 58521416 #对于表来说是全表扫描的数,对于索引是通过
索引法返回的索引数,如果这个值数明显于tup_fetched,说明当前数据库存在全表扫描的
情况。
tup_fetched | 57193639 #指通过索引返回的数
tup_inserted | 14293061 #插的数
tup_updated | 42868451 #新的数
tup_deleted | 98 #删除的数
conflicts | 0 #与恢复冲突取消的查询次数(只会在备库上发)
temp_files | 0 #产临时件的数,如果这个值很说明
work_mem需要调
temp_bytes | 0 #临时件的
deadlocks | 0 #死锁的数,如果这个值很说明业务逻辑有问
题
通过pg_stat_database我们就可以概解数据库的历史情况,如看到tup_returned值远于
tup_fetched,说明数据库历史执的sql很多都是全表扫描,说明存在很多没有索引的sql,这时候可
以结合pg_stat_statments来查找慢sql,也可以通过pg_stat_user_tables找到全表扫描次数和数最多
的表。通过看到tup_updated很说明数据库有很频繁的新,这个时候就需要关注下vacuum相关
的指标和事务,如果没有及时进垃圾回收会造成数据膨胀的较厉害。如果temp_files较的话说
明存在很多的排序,hash,或者聚合这种操作,可以通过增work_mem减少临时件的产,并且
同时这些操作的性能也会有较的提升。
3.pg_stat_user_tables关键指标
通过查询pg_stat_user_tables,可以基本清楚哪些表的全表扫描的次数较多,表中是插还是新,删
除较多。也可以解当前表中垃圾数据的数。
4.pg_stat_user_indexes关键指标
blk_read_time | 0 #数据库中花费在读取件的时间,这个值较说
明内存较,需要频繁的从磁盘中读数据件
blk_write_time | 0 #数据库中花费在写数据件的时间,pg中脏
般都写page cache,如果这个值较,说明page cache较,操作系统的page cache需要积极的
写。
stats_reset | 2019-04-09 14:06:53.416473+08 #统计信息重置的时间
relid | 16390 #表的oid
schemaname | public #模式名称
relname | pgbench_accounts #表名
seq_scan | 0 #这个表进全表扫描的次数
seq_tup_read | 0 #全表扫描的数据数,如果这个值很说明
对这个表进sql很有可能都是全表扫描,需要结合具体的执计划来看
idx_scan | 29606482 #索引扫描的次数
idx_tup_fetch | 29606482 #通过索引扫描返回的数
n_tup_ins | 0 #插的数据数
n_tup_upd | 14803241 #新的数据数
n_tup_del | 0 #删除的数据数
n_tup_hot_upd | 14638544 #hot update的数据数,这个值与
n_tup_upd越接近说明update的性能较好,新数据时会新索引。
n_live_tup | 100012319 #活着的数
n_dead_tup | 2403437 #死亡的数
n_mod_since_analyze | 0 #上次analyze的时间
last_vacuum | #上次动vacuum的时间
last_autovacuum | #上次autovacuum的时间
last_analyze | #上次analyze的时间
last_autoanalyze | 2019-04-09 14:12:30.402387+08 #上次动analyze的时间
vacuum_count | 0 #vacuum的次数
autovacuum_count | 0 #autovacuum的次数
analyze_count | 0 #analyze的次数
autoanalyze_count | 1 #动analyze的次数
of 5
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论