




PostgreSQL扫描方法综述
5墨值下载
PostgreSQL
扫描方法综述
关系型数据库都需要产生一个最佳的执行计划从而在查询时耗费的时间和资源最少。
通常情况下,所有的数据库都会产生一个以树形式的执行计划:计划树的叶子节点被称为
表扫描节点。查询节点对应于从基表获取数据。
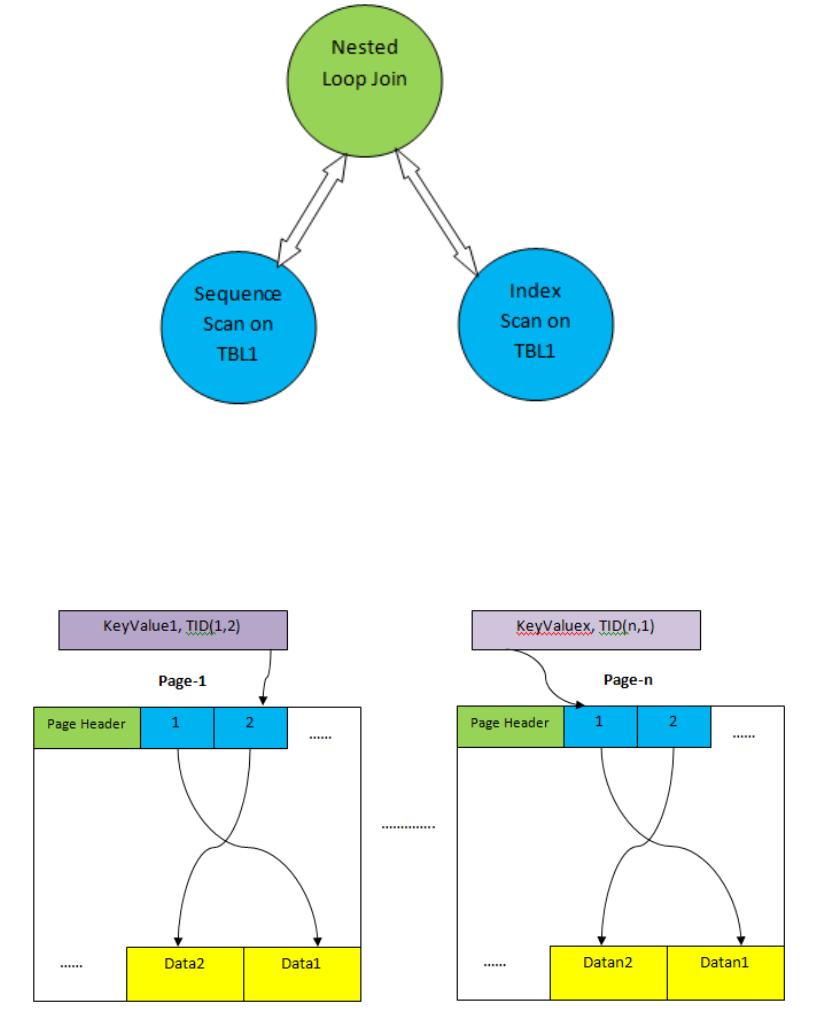
例如,这一个查询:
SELECT *FROM TAB1,TAB2 where TAB2.ID>1000
。假设计划树如下:
上面的计划树:“
TBL1
上的顺序扫描”和“
TBL2
上的索引扫描”分别对应于表
TBL1
和
TBL2
上的表扫描方法。
TBL1
上的顺序扫描:从对应页中顺序获取数据;索引扫描:使用索引扫
描访问表
2
。选择一个正确的扫描方法作为计划的一部分对于查询性能非常重要。
深入理解
PG
的扫描方法之前,先介绍几个重要的概念。
HEAP
:存储表整个行的存储域。如上所示,整个域被分割为多个页,每个页大小默认是
8K
。每个页中,
item
指针(例如上述页中的
1,2
)指向页内的数据。
Index Storage
:只存储
KEY
值,即索引中包含的列值。也是分割成多个页,每个索引页默认
8K
。
Tuple Idener(TID)
:
TID
为
6
个字节,包含两部分。前
4
个字节为页号,后
2
个字节为页
内
tuple
索引。
TID
可以定位到特定记录。
当前版本,
PG
支持以下扫描方法:顺序扫描、索引扫描、索引覆盖扫描、
bitmap
扫描、
TID
扫描。依赖于表基数、选择的表、磁盘
IO
、随机
IO
、顺序
IO
等,每种扫描方法都非常
有用。我们先创建一个表并预制数据,并解释这些扫描方法。
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000,
generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZE
这个例子中,预制
1
亿条记录并执行
analyze
更新统计信息。
顺序扫描
顾名思义,表的顺序扫描就是顺序扫描对应表所有页的
item
指针。如果一个表有
100
页,每页有
1000
条记录,顺序扫描就会获取
100*1000
条记录并检查是否匹配隔离级别以
及
where
条件。因此,即使只有
1
条记录满足条件,他也会扫描
100K
条记录。针对上表的
数据,下面的查询会进行顺序扫描,因为有大部分的数据需要被
selected
。
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)
注意,不计算和比较计划耗费,几乎不可能直到选用哪个扫描方法。但是为了使用顺
序扫描,至少需要满足以下关键点:谓词部分没有可用的索引键;或者
SQL
查询获取的行
记录占表的大部分。如果只有少数行数据被获取,并且谓词在一个或多个列上,那么久会
尝试使用或者不使用索引来评估性能。
索引扫描
和顺序扫描不同,索引扫描不会顺序获取所有表记录。相反,依赖于不同索引类型并
和查询中涉及的索引相对应使用不同的数据结构。然后索引扫描获取的条目直接指向
heap
域中的数据,然后根据隔离级别判断可见性。因此索引扫描分两步:
从索引数据结构中获取数据,返回
heap
中数据对应的
TID
;然后定位到对应的
heap
页
直接访问数据。由于以下原因需要执行额外的步骤:查询可能请求可用索引更多的列;索
引数据中不维护可见信息,为了判断可见性,需要访问
heap
数据。
此时可能会迷惑,索引扫描如此高效,为什么有时不用呢?原因在于
cost
。这里的
cost
涉及
IO
的类型。索引扫描中,为了获取
heap
中的对应数据,涉及随机
IO
;而顺序扫
描涉及顺序
IO
,只有随机
IO
耗时的
1/4
。
因此只有当顺序
IO
的代价大于随机
IO
时,才会选择索引扫描。
针对上表和数据,执行下面查询时会使用索引扫描。随机
IO
代价小,从而查询标记快。
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
of 4
5墨值下载
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文档的来源(墨天轮),文档链接,文档作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
下载排行榜

评论