




背景
- 前言
引用上次的测试:Oracle ORA-03113 引发的DBLINK隐患,上次测试到网络异常(客户端断网)后,数据库的连接Session存活了2个小时才被检查到timed out ,被释放连接。 - Oracle alert 日志
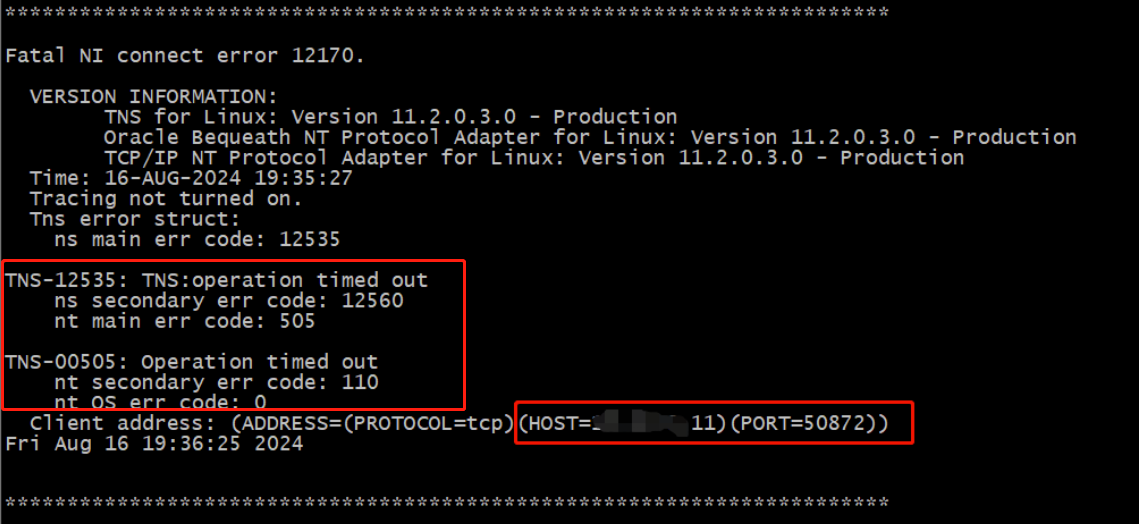
分析汇总
通过最近查阅的资料会话检测涉及以下2个方面:
- 死联接检测:$ORACLE_HOME/network/admin/sqlnet.ora配置文件里的expire_time参数 :
(12c开始则利用操作系统keepalive参数进行检测)
#sqlnet.expire_time = 10
########################
#
#Possible values: 0-any valid positive integer! (in minutes)
#Default: 0 minutes
#Recommended value: 10 minutes
#
#Purpose: Indicates the time interval to send a probe to verify the
# client session is alive (this is used to reclaim watseful
# resources on a dead client)
#
#Supported since: v2.1
- 系统参数:
[root@db ~]# sysctl -a|grep keep
net.ipv4.tcp_keepalive_time - 表示TCP连接闲置多长时间后开始发送探测报文。(单位:秒)
net.ipv4.tcp_keepalive_probes - 表示一次探测过程中最多可以重发探测报文的次数。(没有收到确认时重发次数)
net.ipv4.tcp_keepalive_intvl - 表示前一个探测报文和后一个探测报文之间的时间间隔。(即超时重传的时间间隔)(单位:秒)
测试环境准备及命令说明
- 使用ss或者netstat命令查看客户端会话信息,可以明显看到keppalive的计时,如下:
[root@db1 ~]# ss -o state established ' dst 10.10.5.64 ' | grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 0 10.10.5.58:ncube-lm 10.10.5.64:54021 timer:(keepalive,54min,0)
[root@db1 ~]# netstat -anptwo | grep 10.10.5.64 | grep -v ssh
tcp 0 0 10.10.5.58:1521 10.10.5.64:54021 ESTABLISHED 21432/oracleprttest keepalive (3241.09/0/0)
- 使用虚拟网卡测试
-- 启虚拟网卡
ifconfig eth0:0 10.10.5.156 up
-- 关闭虚拟网卡
ifconfig eth0:0 10.10.5.156 down
- tns配置:使用虚拟网卡IP
db1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.5.156)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = db1)
)
)
模拟一:系统keepalive测试
将值调小,方便观察测试
[root@db ~]# sysctl -a|grep keep
net.ipv4.tcp_keepalive_time = 60
net.ipv4.tcp_keepalive_probes = 1
net.ipv4.tcp_keepalive_intvl = 1
DB1启动虚拟网卡:
[root@db1 ~]# ifconfig eth0:0 10.10.5.156 up
[root@db1 ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:50:56:9B:02:34
inet addr:10.10.5.58 Bcast:10.10.5.255 Mask:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:43863217 errors:0 dropped:0 overruns:0 frame:0
TX packets:978056 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2823035489 (2.6 GiB) TX bytes:71698966 (68.3 MiB)
eth0:0 Link encap:Ethernet HWaddr 00:50:56:9B:02:34
inet addr:10.10.5.156 Bcast:10.255.255.255 Mask:255.0.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:1073572 errors:0 dropped:0 overruns:0 frame:0
TX packets:1073572 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:90582001 (86.3 MiB) TX bytes:90582001 (86.3 MiB)
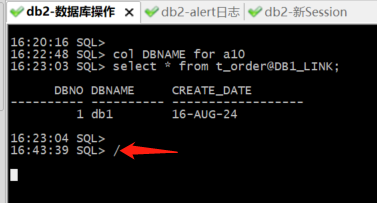
DB2 时间【16:23:03】通过DB1_LINK 查询T_ORDER表
16:22:48 SQL> col DBNAME for a10
16:23:03 SQL> select * from t_order@DB1_LINK;
DBNO DBNAME CREATE_DATE
---------- ---------- ------------------
1 db1 16-AUG-24
DB1 时间【16:23:04】发现连接
16:24:53 SQL> col pid for 9999
16:24:54 SQL> col SID for 9999
16:24:54 SQL> col spid for a10
16:24:54 SQL> col USERNAME for a10
16:24:54 SQL> SELECT
16:24:54 2 s.username,
16:24:54 3 s.sid,
16:24:54 4 s.serial#,
16:24:54 5 p.pid,
16:24:54 6 p.spid,
16:24:54 7 s.status,
16:24:54 8 s.port,
16:24:54 9 to_char(s.logon_time,'yyyymmdd hh24:mi:ss') logon_time
16:24:54 10 FROM v$session s ,v$process p
16:24:54 11 WHERE TYPE!='BACKGROUND'
16:24:54 12 and s.username ='TWO'
16:24:54 13 and s.PADDR=p.addr
16:24:54 14 order by to_char(s.logon_time,'yyyymmdd hh24:mi:ss') ;
USERNAME SID SERIAL# PID SPID STATUS PORT LOGON_TIME
---------- ----- ---------- ----- ---------- -------- ---------- -----------------
TWO 68 3915 30 12379 INACTIVE 34558 20240821 16:23:04
DB1-down掉虚拟网卡,keepalive 会话保持:持续递减,不会重新从60s计时,为0时断开连接
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 0 10.10.5.156:ncube-lm 10.10.5.64:34558 timer:(keepalive,25sec,0)
[root@db1 ~]# ifconfig eth0:0 10.10.5.156 down
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 0 10.10.5.156:ncube-lm 10.10.5.64:34558 timer:(keepalive,14sec<-递减,0)
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 0 10.10.5.156:ncube-lm 10.10.5.64:34558 timer:(keepalive,12sec<-递减,0)
[root@db1 ~]# date
2024年 08月 21日 星期三 16:28:00 CST
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 0 10.10.5.156:ncube-lm 10.10.5.64:34558 timer:(keepalive,2.067ms<-递减,0)
[16:28:05]发现连接断开
[root@db1 ~]# date
2024年 08月 21日 星期三 16:28:05 CST
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
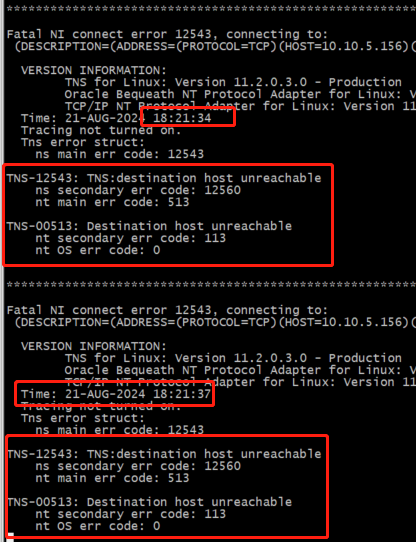
DB1 alert 于[16:28:05]日志输出 TNS-12535、TNS-00505
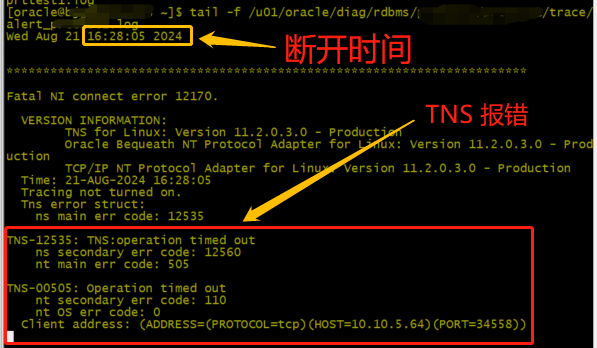
DB2 旧连接再次执行hang住
DB2 查看连接信息:keepalive探测连接频率 12s/147
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:34558 10.10.5.156:ncube-lm timer:(on,1.470ms,24 <-递增)
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:34558 10.10.5.156:ncube-lm timer:(on,12sec,145<-递增)
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:34558 10.10.5.156:ncube-lm timer:(on,12sec,147<-递增)
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port <-已无连接
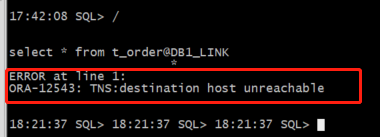
DB2 旧连接报错:ORA-12543
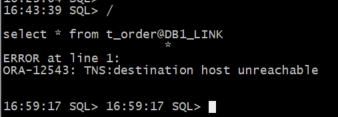
DB2 alert 日志报错:TNS-12543、TNS-00513
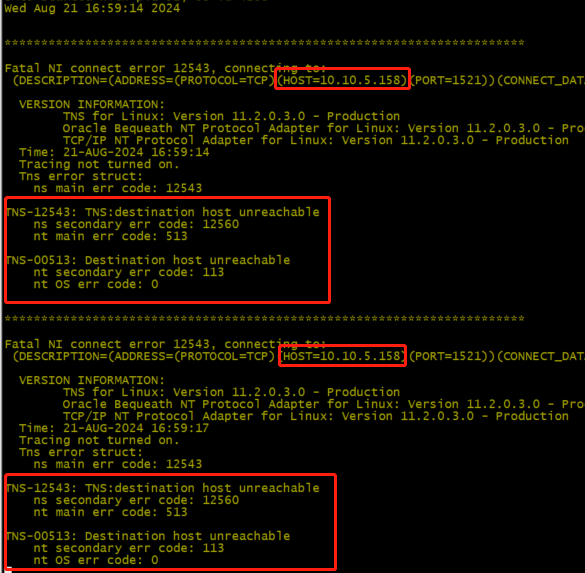
DB2 TNS:修改为物理IP
db1 =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = 10.10.5.58)(PORT = 1521))
(CONNECT_DATA =
(SERVER = DEDICATED)
(SERVICE_NAME = prttest1)
)
)
DB2 新Session 可连接DB1访问
16:42:33 SQL> col DBNAME for a10
16:42:39 SQL> select * from t_order@DB1_LINK;
DBNO DBNAME CREATE_DATE
---------- ---------- ------------------
1 db1 16-AUG-24
DB2 旧Session 连接156的连接断开后,会重新发启连10.10.5.58的连接,从而实现再次访问
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:34558 10.10.5.156:ncube-lm timer:(on,1.280ms,147 <-递增)
[root@db2 ~]# ss -o state established 'dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port <-已无连接
DB2 旧Session再次获得连接
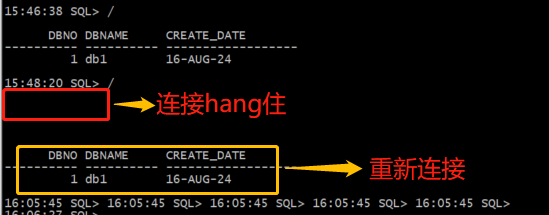
模拟一:小结:
- 当连接异常后,系统会按:keepalive的参数保持60s后目标端直接断开连接释放资源,数据库报错:TNS-12535、TNS-00505;
- 然后目标端会按频率12s/147后进行断开连接,数据库报错:TNS-12543、TNS-00513、ORA-12543;
- 修改DB1 物理IP:10.10.5.58,新Sesssion 可直接访问,旧Session在keepalive探测12s/147后重新解析tns获取连接访问;
- 所以Oracle ORA-03113 引发的DBLINK隐患 测试的2个小时连接释放是因为tcp_keepalive_time 参数默认为:7200;
- keepalive探测12s/147 设置参数后续再进行调研;
模拟二:死联接检测DCD(Dead Connection Detection)
恢复keepalive参数
[root@db1 ~]# sysctl -a|grep keep
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
sqlnet.ora :expire_time=1
[oracle@db1 admin]$ cat sqlnet.ora | grep expire_time
sqlnet.expire_time = 1
启用虚拟网卡
[root@db1 ~]# ifconfig eth0:0 10.10.5.156 up
DB2 通过dblink 连接到 DB1:

【17:43:52】 down 掉虚拟网卡
[root@db1 ~]# date
2024年 08月 21日 星期三 17:43:52 CST
[root@db1 ~]# ifconfig eth0:0 10.10.5.156 down
DB1:keepalive连接信息,每次1min59sec,模糊:16次<-没抓到
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 40 10.10.5.156:ncube-lm 10.10.5.64:36470 timer:(persist,1min59sec,10)
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 60 10.10.5.156:ncube-lm 10.10.5.64:36470 timer:(persist,1min59sec,11)
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 160 10.10.5.156:ncube-lm 10.10.5.64:36470 timer:(persist,1min31sec,16)
[root@db1 ~]# ss -o state established ' dst 10.10.5.64'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
DB1 alert 报错:TNS-12535、TNS-00505
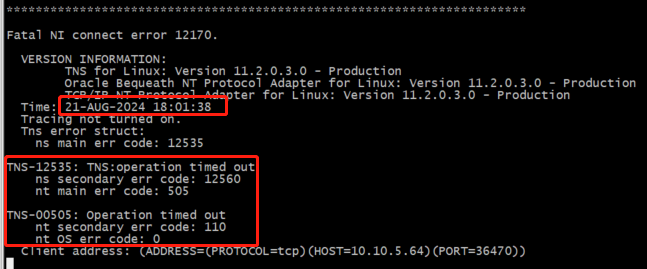
DB1 连接信息已被释放
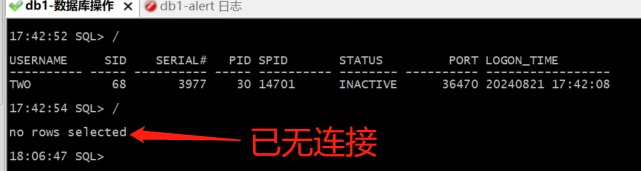
DB2 keepalive连接信息,每次12s一共146次
[root@db2 ~]# ss -o state established ' dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:36470 10.10.5.156:ncube-lm timer:(on,12sec,31)
[root@db2 ~]# ss -o state established ' dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
0 321 10.10.5.64:36470 10.10.5.156:ncube-lm timer:(on,502ms,146)
[root@db2 ~]# ss -o state established ' dst 10.10.5.156'| grep -v ssh
Recv-Q Send-Q Local Address:Port Peer Address:Port
DB2 alert 报错:TNS-12535、TNS-00505
模拟二小结:
- DCD:死联接检测功能目标端设置sqlnet.expire_time = 1,会话保持:2min,探测大约16次;
- DCD:死联接检测功能源端同样设置sqlnet.expire_time = 1,会话保持:12s,探测146次;
- 数据库及alert日志报警与模拟一 测试结果一致;
总结
- 通过模拟一、二测试,DCD与keepalive参数实现的效果一样;
- 修改TNS仅会影响新Session,旧Session还会沿用之前的信息,除非不可用,会重新解释新的tns重新连接;
- TNS-12535、TNS-00505、TNS-12543、TNS-00513、ORA-12543触发原因找到了;
文章推荐
- 故障处理
《Oracle HASH JOIN 引起的TEMP爆满分析总结》
《expdp/impdp 任务终止不能靠Ctrl+C》
《Oracle_索引重建—优化索引碎片》
《Oracle 自动收集统计信息机制》
《DBA_TAB_MODIFICATIONS表的刷新策略测试》
《FY_Recover_Data.dbf》
《Oracle RAC 集群迁移文件操作.pdf》
《Oracle Date 字段索引使用测试.dbf》
《Oracle 诊断案例 :因应用死循环导致的CPU过高》
《记录一起索引rebuild与收集统计信息的事故》
《RAC DG删除备库redo时报ORA-01623》
《问答榜上引发的Oracle并行的探究(一)》
《问答榜上引发的Oracle并行的探究(二)》
《DG 同步延迟之奇怪的经典报错:ORA-16191》 - 等待事件
《log file sync》 等待事件问题分析汇总
《ASH报告发现:os thread startup 等待事件分析》 - 监控&脚本
《DG standby time 监控脚本部署》
《Oracle 慢SQL监控脚本》
《Oracle 慢SQL监控测试及监控脚本.pdf》
《oracle 监控表空间脚本 每月10号0点至06点不报警》
《Oracle 脚本实现简单的审计功能》 - 安装系列
《ORACLE_19C_linux安装.pdf》
《Oracle 19c-手工建库.pdf》
《19c单库升级19.11补丁.pdf》
《19c_rac补丁《19.11-p32841500》.pdf 》
《oracle_图形-单实例11.2.0.4升级19.3.pdf》
《oracle_11.2.0.3升级11.2.0.4–单实例升级.pdf》
《oracle_静默-单实例 11.2.0.4升级19.3.pdf》
《CentOS_6.7系统一步一步 RAC 11.2.0.4升级19.3.pdf》
《整理后_RAC_11.2.0.4升级19c.pdf》
欢迎赞赏支持或留言指正

最后修改时间:2024-09-03 17:37:07
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
