




前言
最近接到个查询任务,需要根据交易类型表(type_order)关联交易表(main_order)进行统计202407-202506时间段的笔数。开发提供的SQL在备库查询了2个小时才有的结果,通过在主库查看执行计划两张表全部为全表扫描,为了不影响主库负载,于是把表导到压测库看看加个索引是不是能提供效率。但结果出乎意料…

示例操作:
- 表数据介绍:
SYS@twodb:1634> select count(*) from type_order;
COUNT(*)
----------
95
SYS@twodb:1634> select count(*) from main_order ;
COUNT(*)
----------
188936311
- 原SQL及执行计划
SYS@twodb:1634> select count(*) from main_order t
2 join type_order d on t.txn_code = d.txn_code and t.txn_channel = d.txn_channel
3 where t.trans_time >= TO_TIMESTAMP('20240701', 'yyyymmdd')
4 and t.trans_time < TO_TIMESTAMP('20250701', 'yyyymmdd')
5 and t.txn_status = 1000
6 and d.prod_id in ('p1','p2','p3','p4','p5','p6','p7', 'p8','p9');
Elapsed: 00:02:07.13
Execution Plan
----------------------------------------------------------
Plan hash value: 1221874830
-----------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-----------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 43 | 1320K (2)| 05:08:10 | | |
| 1 | SORT AGGREGATE | | 1 | 43 | | | | |
|* 2 | HASH JOIN | | 4499K| 184M| 1320K (2)| 05:08:10 | | |
|* 3 | TABLE ACCESS FULL | type_order | 9 | 171 | 3 (0)| 00:00:01 | | |
| 4 | PARTITION RANGE ITERATOR| | 145M| 3341M| 1319K (2)| 05:07:55 | 106 | 117 |
|* 5 | TABLE ACCESS FULL | main_order | 145M| 3341M| 1319K (2)| 05:07:55 | 106 | 117 |
-----------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("T"."txn_code"="D"."txn_code" AND "T"."txn_channel"="D"."txn_channel")
3 - filter("D"."prod_id"='p3' OR "D"."prod_id"='p4' OR
"D"."prod_id"='p6' OR "D"."prod_id"='p7' OR "D"."prod_id"='p2' OR
"D"."prod_id"='p5' OR "D"."prod_id"='p1' OR "D"."prod_id"='p8' OR
"D"."prod_id"='p9')
5 - filter("T"."txn_status"=1000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
3933934 consistent gets
3933857 physical reads
0 redo size
530 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
- 创建索引
SYS@twodb:1634> create index idx_order_1 on main_order (txn_code, txn_channel) nologging local;
Index created
- 创建索引后的执行计划
SYS@twodb:1634> /
Elapsed: 00:10:45.61
Execution Plan
----------------------------------------------------------
Plan hash value: 2168199550
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 43 | 74806 (1)| 00:17:28 | | |
| 1 | SORT AGGREGATE | | 1 | 43 | | | | |
| 2 | NESTED LOOPS | | 4499K| 184M| 74806 (1)| 00:17:28 | | |
| 3 | NESTED LOOPS | | 4499K| 184M| 74806 (1)| 00:17:28 | | |
|* 4 | TABLE ACCESS FULL | type_order | 9 | 171 | 3 (0)| 00:00:01 | | |
| 5 | PARTITION RANGE ITERATOR | | 266K| | 676 (1)| 00:00:10 | 106 | 117 |
|* 6 | INDEX RANGE SCAN | IDX_ORDER_1 | 266K| | 676 (1)| 00:00:10 | 106 | 117 |
|* 7 | TABLE ACCESS BY LOCAL INDEX ROWID| main_order | 499K| 11M| 21328 (1)| 00:04:59 | 1 | 1 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - filter("D"."prod_id"='p3' OR "D"."prod_id"='p4' OR "D"."prod_id"='p6' OR
"D"."prod_id"='p7' OR "D"."prod_id"='p2' OR "D"."prod_id"='p5' OR
"D"."prod_id"='p1' OR "D"."prod_id"='p8' OR "D"."prod_id"='p9')
6 - access("T"."txn_code"="D"."txn_code" AND "T"."txn_channel"="D"."txn_channel")
7 - filter("T"."txn_status"=1000)
Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
10146784 consistent gets
4662946 physical reads
8116 redo size
530 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
前后对比
- 全表扫描要比走索引效率高80%
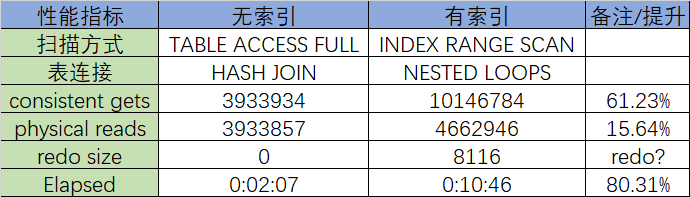
HASH JOIN
-
HASH连接的算法:
1、Build 阶段:读取小表(Build Input)生成Hash表;
2、Probe 阶段:读取大表(Probe Input)探查Hash表并进行连接;
3、Build 操作在PGA中进行,不够时使用临时表空间;
4、被驱动表(被驱动表不需要读入PGA中),对被驱动表的连接列也进行hash运算,然后到PGA中去探测Hash表进行连接; -
HINT用法:
SELECT /*+leading(t1) use_hash(t2)*/ *
FROM T1
INNER JOIN ON T1.ID = T2.ID;
- 注意
1、当表数据太大PGA放不下,会使用临时表空间,从而影响性能。示例:Oracle HASH JOIN 引起的TEMP爆满分析总结;
2、驱动顺序:小的结果集先访问,大的结果集后访问,才能保证被驱动表的访问次数降到最低,才能保障性能;
3、驱动表和被驱动表都只会访问0次(索引能返回数据,就不需要再回表)或者1次;
4、HASH连接的驱动表与被驱动表的连接列都不需要创建索引;
5、HASH连接主要用于处理两表等值关联;
6、海量数据连接非常快;
NESTED LOOPS
- 嵌套循环的算法:
有驱动顺序,驱动表返回多少条记录,被驱动表就访问多少次,嵌套循环连接中无须排序。 - HINT用法:t1为驱动表,t2为被驱动表
select /*+leading(t1) use_nl(t2)*/ *
from t1
join t2 on t1.id=t2.id;
- 注意:
1、非常依赖索引,被驱动表索引只能:INDEX UNIQUE SCAN、INDEX RANGE SCAN。不能:TABLE ACCESS FULL、INDEX FULL SCAN、INDEX SKIP SCAN、INDEX FAST FULL SCAN,否则消耗太高,容易跑不出数据。
2、DBLINK永远不能作为NL的被驱动表。
3、小结果集做驱动表,大结果集做被驱动表,才能保障性能。
4、两表使用外连接进行关联,如果是NESTED LOOPS,那么无法更改驱动表,驱动表将会被固定在主表。
5、连接条件是instr、LIKE、substr、regexp_like只能走NESTED LOOPS
小结:
- 两表关联返回少量数据应该走嵌套循环,两表关联返回大量数据应该走HASH连接。
- 此示例:type_order表1条数据对应main_order表多条数据,关联返回的结果集1.34亿条数据,因此HASH连接相对效率要高。
- HASH看体积,NL看行数。HASH看体积,因为HASH是要全部放内存的。HASH因为单个进程最大2G,所以要看体积。
- HASH连接驱动表非常大优化方案:开并行,并行之后就不是一个进程在HASH。
查询为什么产生redo?
在Oracle数据库中,尽管SELECT语句通常是只读操作,理论上不应对数据产生修改,但在特定场景下仍可能触发redo日志的生成。这些情况主要源于Oracle内部机制对数据一致性、事务管理和存储结构的维护需求。以下是SELECT产生redo的主要原因:
- 1、延迟块清除(Delayed Block Cleanout)
当事务提交后,如果修改的数据块已被刷出内存(如因DBWR进程写入磁盘),后续SELECT读取这些块时,Oracle需要清除块上的事务信息(如ITL条目中的锁标志和行头锁定位),此清理操作会生成redo日志。这在处理大事务修改的块时尤为常见。 - 2、维护读一致性(Read Consistency)
为实现查询开始时刻的数据一致性视图,SELECT可能访问undo数据块来重建旧版本数据。如果undo数据块首次被加载到内存,此过程可能记录undo表空间的变化产生redo。 - 3、直接路径读取(Direct Path Reads)
在处理大批量数据扫描(如全表扫描或排序操作)时,Oracle可能绕过buffer cache采用直接路径读取。若此过程需要分配临时段(例如用于排序或哈希连接),临时段的分配动作会生成redo日志。 - 4、递归SQL操作(Recursive SQL)
Oracle内部自动执行的维护操作(如数据字典统计信息更新或索引重建),可能在SELECT访问对象时触发后台修改系统表,间接产生redo日志。 - 5、Lost Write Detection机制
为防止数据写入丢失,Oracle在特定场景(如启用自动检测功能)下,SELECT读取块时会校验块完整性,若检测到潜在丢失写入风险,则生成redo日志以记录校验信息,导致大量redo产生。 - 6、块清理操作(Block Cleanout)
对于延迟清理状态的“脏块”(如先前DML操作未完全提交的块),SELECT读取时需要完成清理事务标记(如设置commit SCN),该操作会修改块头部并生成redo。
尽管这些情况在OLTP系统中相对少见,但高并发事务或大负载查询仍可能显著增加redo日志量。优化建议包括减少大事务提交频率、避免不必要的全表扫描,或调整参数如_db_block_checking以减轻检测机制的开销。
为什么INDEX RANGE SCAN + NESTED LOOPS 会产生REDO?未找到对应的情况,后续如果有思路再补充。
- ash报告截图:没有“Direct Path Reads”事件

总结&疑问
- 1、索引优化不是万能的;
- 2、没想明白为什么在备库查需要2个小时,导出来放压测库只需要2分种?
- 3、此次的查询为什么会产生redo,没有搞明白,和总结的特征都不对症!
希望大家有思路的话,可以留言沟通,成长于在不断的学习。
引用
2019云和恩墨大讲堂:8.1 Join原理与优化
Oracle执行select会产生redo吗?
Oracle表连接优化思路-嵌套查询/哈希连接/排序合并连接等
测试文档下载
Oracle 表连接NESTED LOOPS、HASH JOIN、排序合并.pdf
欢迎赞赏支持或留言指正

