




背景
此SQL运营反馈执行了一上午都没出结果,让我看看有没有优化方案,因为他们每月都需要执行一次统计数据。为了不影响生产环境,对相关表(expdp/impdp)导入到测试环境后15分钟就出结果了(可能是统计信息过旧或生产库中表碎片的原因,在此不做深入探究)。
- 初始SQL
select count(distinct c.cust_id)
from main_order t
join order_port a on t.port_id = a.port_id
join cust_info c on a.cust_id = c.cust_id
where t.tran_time >= to_date('2025-04-01', 'yyyy-mm-dd')
and t.tran_time < to_date('2025-07-01', 'yyyy-mm-dd')
and c.cust_id <> 'C00001';
返回结果:533
- 数据量
| 表名称 | 数据量 | 备注 |
|---|---|---|
| MAIN_ORDER | 367357262 | 分区字段:tran_time |
| ORDER_PORT | 799286 | - |
| CUST_INFO | 12133 | - |
- 索引
| 表名称 | 类型 | 索引名称 | 字段 |
|---|---|---|---|
| CUST_INFO | 主键 | PK_CUST_INFO | CUST_ID |
| ORDER_PORT | 主键 | PK_ORDER_PORT | PORT_ID |
| MAIN_ORDER | 普通 | AATD_IDX2 | PORT_ID |
开始改写
先理解SQL逻辑:汇总时间范围:202504-202506 三个月中,剔除测试商户号:C00001,有交易的商户数。
失败的改写
- 第一优化点:distinct 去重效率低(网上经验表示),建议使用group by 去重;此观点不绝对!
- 第二优化点:剔除测试商户号:C00001,可以汇总完后-1来实现,省略“<>”操作;此观点错误!
- 改写后SQL:
select count(*)-1
from (select t.port_id
from main_order t
where t.tran_time >= to_date('2025-04-01', 'yyyy-mm-dd')
and t.tran_time < to_date('2025-07-01', 'yyyy-mm-dd')
group by t.port_id) b
join order_port a on b.port_id = a.port_id
join cust_info c on a.cust_id = c.cust_id;
记录数:543(失败)
返回结果543与初始SQL的结果533多出了10条记录。用了一上午梳理逻辑都感觉没问题,最后查了下cust_info 表里的cust_id字段的数据,发现不是唯一值:C00001正好有11条重复值。改写不能只考虑SQL逻辑,还应该结合表里的数据。此改写SQL方案失败。
低效率的改写
- 总结问题二次改写SQL
select count(*)-1
from (select c.cust_id
from main_order t
join order_port a on t.port_id = a.port_id
join cust_info c on a.cust_id = c.cust_id
where t.tran_time >= to_date('2025-04-01', 'yyyy-mm-dd')
and t.tran_time < to_date('2025-07-01', 'yyyy-mm-dd')
group by c.cust_id);
记录数:533
- 刷新数据库内存
ALTER SYSTEM FLUSH BUFFER_CACHE;
ALTER SYSTEM FLUSH SHARED_POOL;
- 执行计划
Elapsed: 00:19:20.78
Execution Plan
----------------------------------------------------------
Plan hash value: 81192362
-----------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
-----------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | | 1361K (1)| 05:17:35 | | |
| 1 | SORT AGGREGATE | | 1 | | | | | | |
| 2 | VIEW | VM_NWVW_0 | 12015 | | | 1361K (1)| 05:17:35 | | |
| 3 | SORT GROUP BY NOSORT | | 12015 | 880K| | 1361K (1)| 05:17:35 | | |
| 4 | NESTED LOOPS | | 2407K| 172M| | 1361K (1)| 05:17:35 | | |
| 5 | NESTED LOOPS | | 25M| 172M| | 1361K (1)| 05:17:35 | | |
| 6 | MERGE JOIN | | 12108 | 520K| | 11760 (1)| 00:02:45 | | |
| 7 | SORT JOIN | | 12015 | 140K| | 31 (7)| 00:00:01 | | |
| 8 | INDEX FAST FULL SCAN | PK_CUST_INFO| 12015 | 140K| | 29 (0)| 00:00:01 | | |
|* 9 | SORT JOIN | | 798K| 24M| 61M| 11729 (1)| 00:02:45 | | |
| 10 | TABLE ACCESS FULL | ORDER_PORT | 798K| 24M| | 7330 (1)| 00:01:43 | | |
| 11 | PARTITION RANGE ITERATOR | | 2100 | | | 31 (0)| 00:00:01 | 115 | 117 |
|* 12 | INDEX RANGE SCAN | AATD_IDX2 | 2100 | | | 31 (0)| 00:00:01 | 115 | 117 |
| 13 | TABLE ACCESS BY LOCAL INDEX ROWID| MAIN_ORDER | 199 | 6169 | | 651 (1)| 00:00:10 | 1 | 1 |
-----------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
9 - access("A"."CUST_ID"="C"."CUST_ID")
filter("A"."CUST_ID"="C"."CUST_ID")
12 - access("T"."port_id"="A"."port_id")
Statistics
----------------------------------------------------------
3010 recursive calls
0 db block gets
33845627 consistent gets
3750470 physical reads
0 redo size
529 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
276 sorts (memory)
0 sorts (disk)
1 rows processed
- 初始SQL执行计划
Elapsed: 00:15:47.82
Execution Plan
----------------------------------------------------------
Plan hash value: 1601498716
-------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | | 1360K (1)| 05:17:34 | | |
| 1 | SORT AGGREGATE | | 1 | 7 | | | | | |
| 2 | VIEW | VW_DAG_0 | 12014 | 84098 | | 1360K (1)| 05:17:34 | | |
| 3 | SORT GROUP BY NOSORT | | 12014 | 879K| | 1360K (1)| 05:17:34 | | |
| 4 | NESTED LOOPS | | 2407K| 172M| | 1360K (1)| 05:17:34 | | |
| 5 | NESTED LOOPS | | 25M| 172M| | 1360K (1)| 05:17:34 | | |
| 6 | MERGE JOIN | | 12107 | 520K| | 11760 (1)| 00:02:45 | | |
| 7 | SORT JOIN | | 12014 | 140K| | 31 (7)| 00:00:01 | | |
|* 8 | INDEX FAST FULL SCAN | PK_CUST_INFO | 12014 | 140K| | 29 (0)| 00:00:01 | | |
|* 9 | SORT JOIN | | 798K| 24M| 61M| 11729 (1)| 00:02:45 | | |
|* 10 | TABLE ACCESS FULL | ORDER_PORT | 798K| 24M| | 7330 (1)| 00:01:43 | | |
| 11 | PARTITION RANGE ITERATOR | | 2100 | | | 31 (0)| 00:00:01 | 115 | 117 |
|* 12 | INDEX RANGE SCAN | AATD_IDX2 | 2100 | | | 31 (0)| 00:00:01 | 115 | 117 |
| 13 | TABLE ACCESS BY LOCAL INDEX ROWID| MAIN_ORDER | 199 | 6169 | | 651 (1)| 00:00:10 | 1 | 1 |
-------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
8 - filter("C"."CUST_ID"<>'C00001')
9 - access("A"."CUST_ID"="C"."CUST_ID")
filter("A"."CUST_ID"="C"."CUST_ID")
10 - filter("A"."CUST_ID"<>'C00001')
12 - access("T"."port_id"="A"."port_id")
Statistics
----------------------------------------------------------
3047 recursive calls
0 db block gets
28411428 consistent gets
3056785 physical reads
0 redo size
543 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
269 sorts (memory)
0 sorts (disk)
1 rows processed
- 效率对比
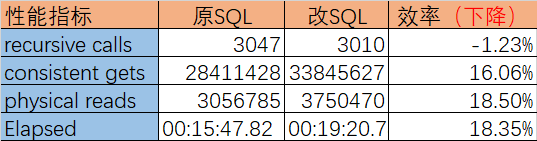
结果一致都是533,但执行耗时及消耗没有提升反而下降:18%,因此改写失败。
其它改写失败方案:
- 使用c.cust_id <> ‘C00001’ 条件比不使用提升2min,因此前面提到的用count(*)-1代替条件的思路错误。
- 执行计划ORDER_PORT表一直是全表扫描,但CUST_ID字段有唯一索引,于是指定索引耗时: 00:14:55.26仅提升1min,仍然不理想。
select /*+ INDEX(a PK_CUST_ID) */
成功优化方案-TABLE ACCESS FULL
突发奇想:删除索引全表扫描,观察一下效率。没想到剧情反转:索引才是查询效率的障碍!!!(最终验证结果是索引导致表连接方式的改变,导致性能下降)
- 执行计划
Elapsed: 00:01:46.39
Execution Plan
----------------------------------------------------------
Plan hash value: 44104297
-------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | | 1976K (1)| 07:41:07 | | |
| 1 | SORT AGGREGATE | | 1 | 7 | | | | | |
| 2 | VIEW | VW_DAG_0 | 12014 | 84098 | | 1976K (1)| 07:41:07 | | |
| 3 | HASH GROUP BY | | 12014 | 879K| 193M| 1976K (1)| 07:41:07 | | |
|* 4 | HASH JOIN | | 2407K| 172M| | 1963K (1)| 07:38:05 | | |
|* 5 | HASH JOIN | | 12107 | 520K| | 7753 (1)| 00:01:49 | | |
|* 6 | TABLE ACCESS FULL | CUST_INFO | 12014 | 140K| | 416 (1)| 00:00:06 | | |
|* 7 | TABLE ACCESS FULL | ORDER_PORT | 798K| 24M| | 7330 (1)| 00:01:43 | | |
| 8 | PARTITION RANGE ITERATOR| | 158M| 4696M| | 1954K (1)| 07:36:00 | 115 | 117 |
| 9 | TABLE ACCESS FULL | MAIN_ORDER | 158M| 4696M| | 1954K (1)| 07:36:00 | 115 | 117 |
-------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("T"."port_id"="A"."port_id")
5 - access("A"."CUST_ID"="C"."CUST_ID")
6 - filter("C"."CUST_ID"<>'C00001')
7 - filter("A"."CUST_ID"<>'C00001')
Statistics
----------------------------------------------------------
1311 recursive calls
0 db block gets
3041240 consistent gets
3038903 physical reads
0 redo size
543 bytes sent via SQL*Net to client
520 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
237 sorts (memory)
0 sorts (disk)
1 rows processed
- HIT 指定a,c,t全部全表扫描
SELECT /*+ FULL(a) FULL(c) FULL(t)*/
多次尝试后发现,只有FULL(t)时,表连接方式为HASH JOIN,执行计划如下:
Elapsed: 00:01:58.35
Execution Plan
----------------------------------------------------------
Plan hash value: 498325925
---------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |TempSpc| Cost (%CPU)| Time | Pstart| Pstop |
---------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 7 | | 1975K (1)| 07:41:01 | | |
| 1 | SORT AGGREGATE | | 1 | 7 | | | | | |
| 2 | VIEW | VW_DAG_0 | 12014 | 84098 | | 1975K (1)| 07:41:01 | | |
| 3 | HASH GROUP BY | | 12014 | 879K| 193M| 1975K (1)| 07:41:01 | | |
|* 4 | HASH JOIN | | 2407K| 172M| | 1962K (1)| 07:38:00 | | |
|* 5 | HASH JOIN | | 12107 | 520K| | 7345 (1)| 00:01:43 | | |
|* 6 | INDEX FAST FULL SCAN | PK_CUST_INFO | 12014 | 140K| | 8 (0)| 00:00:01 | | |
|* 7 | TABLE ACCESS FULL | ORDER_PORT | 798K| 24M| | 7330 (1)| 00:01:43 | | |
| 8 | PARTITION RANGE ITERATOR| | 158M| 4696M| | 1954K (1)| 07:36:00 | 115 | 117 |
| 9 | TABLE ACCESS FULL | MAIN_ORDER | 158M| 4696M| | 1954K (1)| 07:36:00 | 115 | 117 |
---------------------------------------------------------------------------------------------------------------------
- 初始化SQL效率对比提升88%

这里就涉及到排序合并连接(SORT JOIN & MERGE JOIN)与HASH JOIN的知识点。 - HASH JOIN的知识点,关注文章:《性能优化-不合理的索引》有总结。
排序合并连接(SORT JOIN & MERGE JOIN)
- 连接算法:
1、Sort 阶段:两边集合按照连接字段进行排序
2、Merge 阶段:排序好的两边集合进行相互合并(Merge)操作。
3、两张表只会访问0次(索引能返回数据,就不需要再回表)或者1次;
4、Sort 、Merge 均在PGA中操作,PGA空间不够时会使用临时表空间。 - 支持排序合并连接的连接条件:支持>、>=和<、<=、<>之类的连接条件。
- 排序合并连接就是为了解决非等值关联,并行返回数据量大的情况
- HINT用法:
SELECT /*+ordered use_merge(t2)*/ * FROM T1 INNER JOIN ON T1.ID = T2.ID
总结
- 1、去重操作:group by 比 distinct 效率高的观点,不绝对视情况而定;
- 2、索引并不能解决所有的性能问题,有时可能会导致性能问题;切记盲目相信索引;
- 3、表的连接方式合适才是影响性能的关键,此示例:HASH JOIN比SORT&MERGE JOIN性能更好;
- 4、两表等值关联:返回数据量少:走NL连接更快,返回数据量多:大部分情况Hash连接比排序合并连接快;
引用
Oracle表连接优化思路-嵌套查询/哈希连接/排序合并连接等
2019云和恩墨大讲堂:8.1 Join原理与优化
测试文档下载
Oracle 表连接NESTED LOOPS、HASH JOIN、排序合并.pdf
欢迎赞赏支持或留言指正

最后修改时间:2025-08-07 11:00:02
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
