




openGauss 每日一练第 20 天学习打卡,学习 openGauss 全文索引基本操作!
学习目标
学习 openGauss 全文索引基本操作!
前面每日一练链接:
openGauss每日一练第 1 天 | 数据库和表的基本操作(一)
openGauss每日一练第 2 天 | 数据库和表的基本操作(二)
openGauss每日一练第 3 天 | 前三课作业实操练习
openGauss每日一练第 4 天 | 角色管理及课后作业
openGauss每日一练第 5 天 | 用户管理及课后作业
openGauss每日一练第 6 天 | 模式管理及课后作业
openGauss每日一练第 7 天 | 表空间管理及课后作业
openGauss每日一练第 8 天 | 分区表管理及课后作业
openGauss每日一练第 9 天 | 普通表索引管理及课后作业
openGauss每日一练第 10 天 | 分区表索引管理及课后作业
openGauss每日一练第 11 天 | 视图管理及课后作业
openGauss每日一练第 12 天 | 自定义数据类型管理及课后作业
openGauss每日一练第 13 天 | 数据导入操作及课后作业
openGauss每日一练第 14 天 | 数据导出操作及课后作业
openGauss每日一练第 15 天 | 定义存储过程和函数及课后作业
openGauss每日一练第 16 天 | 事务控制及课后作业
openGauss每日一练第 17 天 | 定义游标及课后作业
openGauss每日一练第 18 天 | 触发器及课后作业
openGauss每日一练第 19 天 | openGauss收集统计信息、打印执行计划、垃圾收集和 checkpoint 及课后作业
课程学习
学习 openGauss 全文索引基本操作!
openGauss 提供了两种数据类型用于支持全文检索。tsvector 类型表示为文本搜索优化的文件格式,tsquery 类型表示文本查询。
连接数据库
#第一次进入等待15秒
su - omm
gsql -r
1.tsvector
–把一个字符串按照空格进行分词,分词的顺序是按照长短和字母排序的, 自动去掉分词中重复的词条
SELECT 'The Fat Rats'::tsvector;
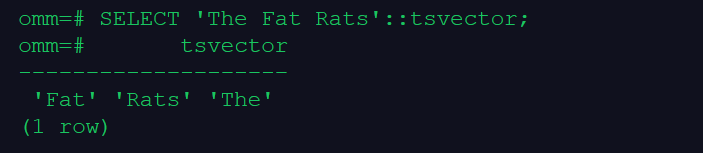
–词条位置常量也可以放到词汇中
SELECT 'a:1 fat:2 cat:3 sat:4 on:5 a:6 mat:7 and:8 ate:9 a:10 fat:11 rat:12'::tsvector;

–拥有位置的词汇甚至可以用一个权来标记,反映文档结构,这个权可以是A,B,C或D。默认的是D,因此输出中不会出现
SELECT 'a:1A fat:2B,4C cat:5D'::tsvector;
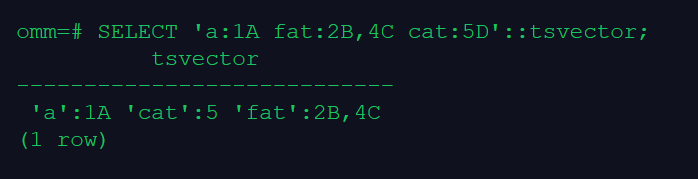
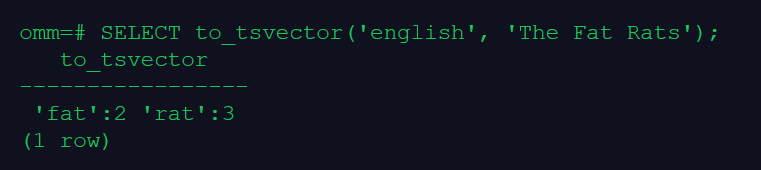
–to_tsvector 函数对这些单词进行规范化处理, 罗列出词条并连同它们文档中的位置
SELECT to_tsvector('english', 'The Fat Rats');
2.tsquery
SELECT 'fat & rat'::tsquery;
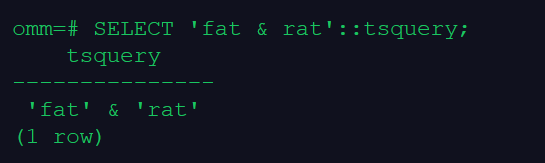
–规范化转为tsquery类型
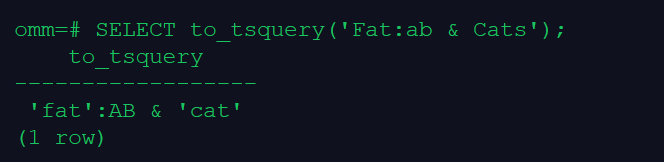
SELECT to_tsquery('Fat:ab & Cats');
3.基本文本匹配
–全文检索基于匹配算子@@,当一个 tsvector 匹配到一个 tsquery 时,则返回 true, tsvector 和 tsquery 两种数据类型可以任意排序。
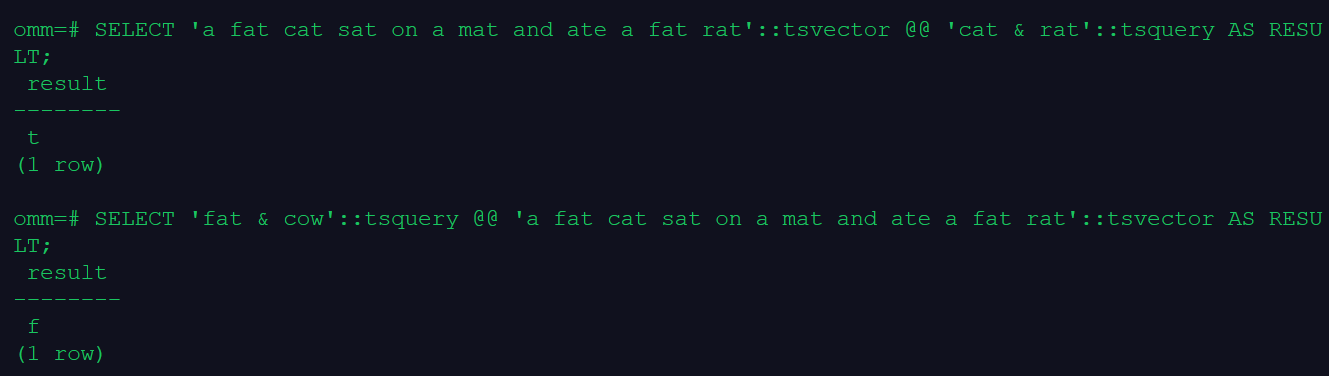
SELECT 'a fat cat sat on a mat and ate a fat rat'::tsvector @@ 'cat & rat'::tsquery AS RESULT;
SELECT 'fat & cow'::tsquery @@ 'a fat cat sat on a mat and ate a fat rat'::tsvector AS RESULT;
– to_tsvector 和 to_tsquery 标准化处理
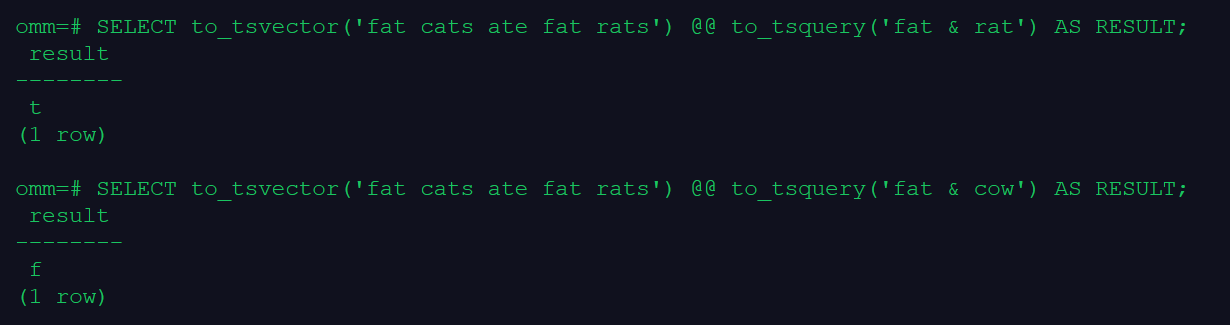
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('fat & rat') AS RESULT;
SELECT to_tsvector('fat cats ate fat rats') @@ to_tsquery('fat & cow') AS RESULT;
4.分词器
–查看所有分词器
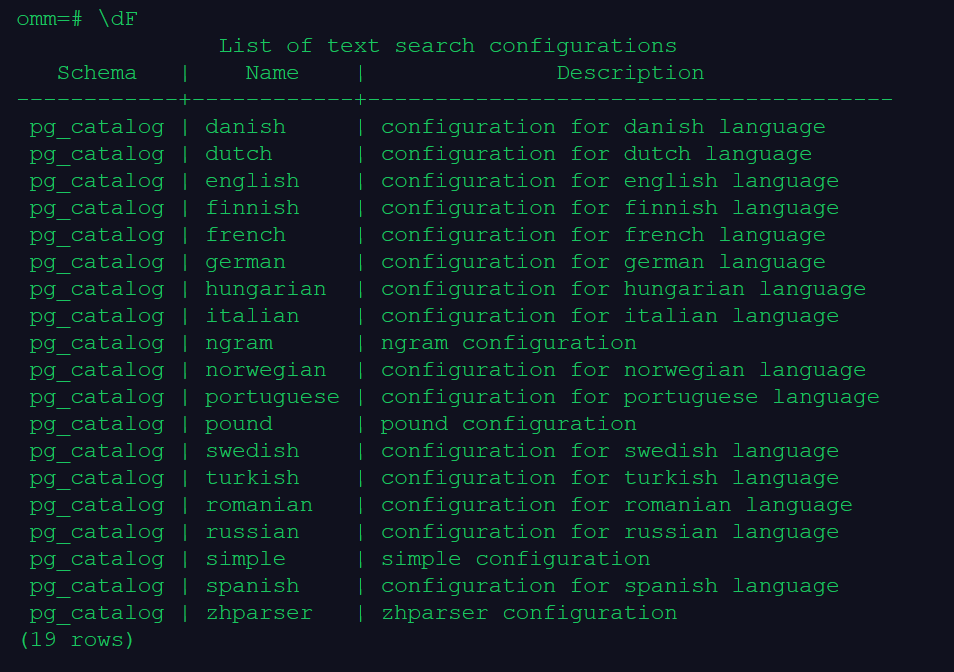
\dF
omm=# \dF
List of text search configurations
Schema | Name | Description
------------+------------+---------------------------------------
pg_catalog | danish | configuration for danish language
pg_catalog | dutch | configuration for dutch language
pg_catalog | english | configuration for english language
pg_catalog | finnish | configuration for finnish language
pg_catalog | french | configuration for french language
pg_catalog | german | configuration for german language
pg_catalog | hungarian | configuration for hungarian language
pg_catalog | italian | configuration for italian language
pg_catalog | ngram | ngram configuration
pg_catalog | norwegian | configuration for norwegian language
pg_catalog | portuguese | configuration for portuguese language
pg_catalog | pound | pound configuration
pg_catalog | swedish | configuration for swedish language
pg_catalog | turkish | configuration for turkish language
pg_catalog | romanian | configuration for romanian language
pg_catalog | russian | configuration for russian language
pg_catalog | simple | simple configuration
pg_catalog | spanish | configuration for spanish language
pg_catalog | zhparser | zhparser configuration
(19 rows)
–查看默认分词器
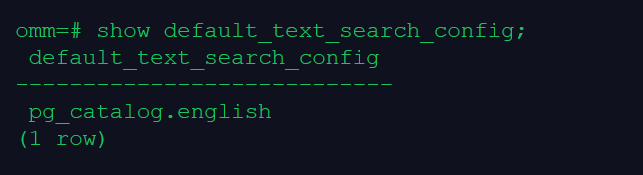
show default_text_search_config;
5.表和索引
CREATE SCHEMA tsearch;
CREATE TABLE tsearch.pgweb(id int, body text, title text, last_mod_date date);
INSERT INTO tsearch.pgweb VALUES(1, 'China, officially the People''s Republic of China(PRC), located in Asia, is the world''s most populous state.', 'China', '2010-1-1');
INSERT INTO tsearch.pgweb VALUES(2, 'America is a rock band, formed in England in 1970 by multi-instrumentalists Dewey Bunnell, Dan Peek, and Gerry Beckley.', 'America', '2010-1-1');
INSERT INTO tsearch.pgweb VALUES(3, 'England is a country that is part of the United Kingdom. It shares land borders with Scotland to the north and Wales to the west.', 'England','2010-1-1');
–将 body 字段中包含 america 的行打印出来
SELECT id, body, title FROM tsearch.pgweb WHERE to_tsvector(body) @@ to_tsquery('america');

–检索出在 title 或者 bod y字段中包含 china 和 asia 的行
SELECT title FROM tsearch.pgweb WHERE to_tsvector(title || ' ' || body) @@ to_tsquery('china & asia');

–为了加速文本搜索,可以创建 GIN 索引(指定 english 配置来解析和规范化字符串)
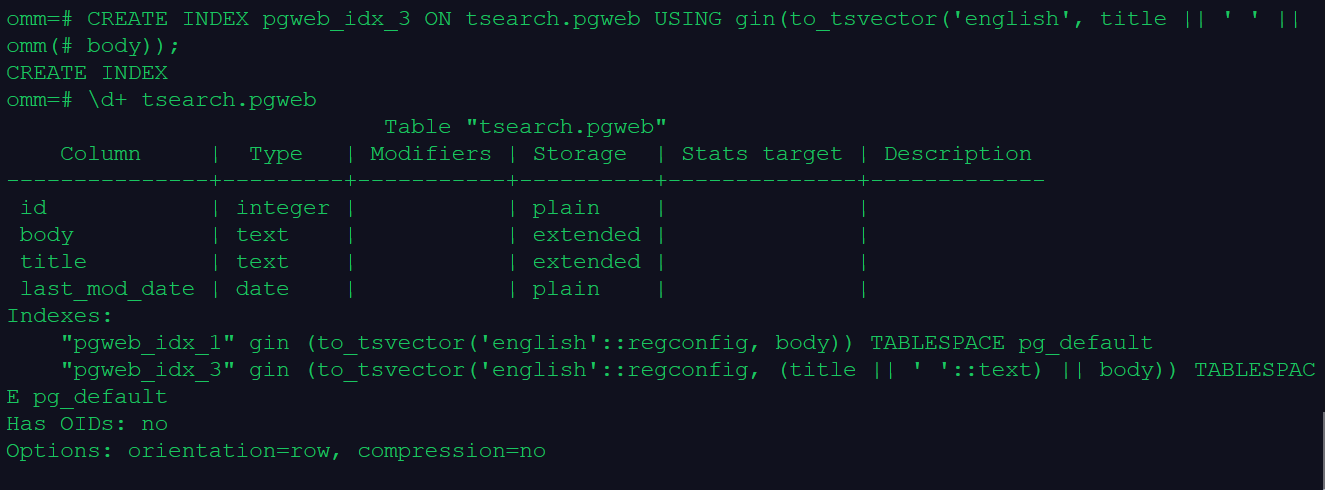
CREATE INDEX pgweb_idx_1 ON tsearch.pgweb USING gin(to_tsvector('english', body));
–连接列的索引
CREATE INDEX pgweb_idx_3 ON tsearch.pgweb USING gin(to_tsvector('english', title || ' ' ||
body));
–查看索引定义
\d+ tsearch.pgweb
omm=# CREATE INDEX pgweb_idx_3 ON tsearch.pgweb USING gin(to_tsvector('english', title || ' ' ||
omm(# body));
CREATE INDEX
omm=# \d+ tsearch.pgweb
Table "tsearch.pgweb"
Column | Type | Modifiers | Storage | Stats target | Description
---------------+---------+-----------+----------+--------------+-------------
id | integer | | plain | |
body | text | | extended | |
title | text | | extended | |
last_mod_date | date | | plain | |
Indexes:
"pgweb_idx_1" gin (to_tsvector('english'::regconfig, body)) TABLESPACE pg_default
"pgweb_idx_3" gin (to_tsvector('english'::regconfig, (title || ' '::text) || body)) TABLESPACE pg_default
Has OIDs: no
Options: orientation=row, compression=no
6.清理数据
drop schema tsearch cascade;
课程作业
1.用 tsvector @@ tsquery 和 tsquery @@ tsvector 完成两个基本文本匹配
--The simplest answer is often the correct one. 最简单的答案往往是对的。
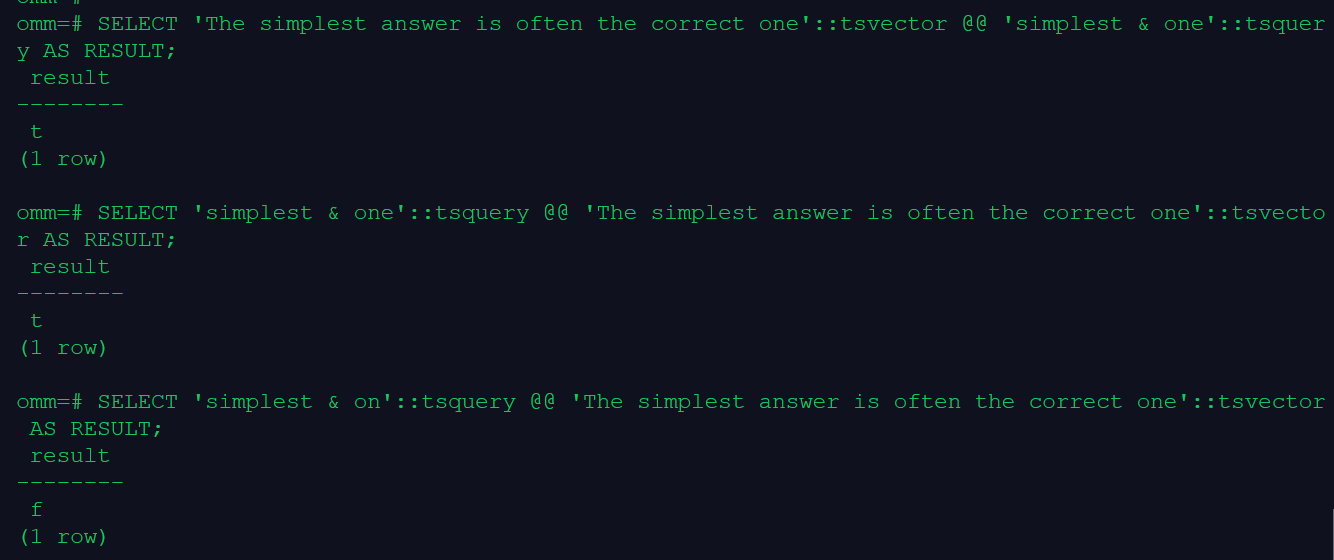
SELECT 'The simplest answer is often the correct one'::tsvector @@ 'simplest & one'::tsquery AS RESULT;
SELECT 'simplest & one'::tsquery @@ 'The simplest answer is often the correct one'::tsvector AS RESULT;
SELECT 'simplest & on'::tsquery @@ 'The simplest answer is often the correct one'::tsvector AS RESULT;
2.创建表且至少有两个字段的类型为 text 类型,在创建索引前进行全文检索
CREATE TABLE jiekexu_web(id int, body text, title text, last_mod_date date);
INSERT INTO jiekexu_web VALUES(1, 'China, officially the People''s Republic of China(PRC), located in Asia, is the world''s most populous state.', 'China', '2010-1-1');
INSERT INTO jiekexu_web VALUES(2, 'America is a rock band, formed in England in 1970 by multi-instrumentalists Dewey Bunnell, Dan Peek, and Gerry Beckley.', 'America', '2010-1-1');
INSERT INTO jiekexu_web VALUES(3, 'England is a country that is part of the United Kingdom. It shares land borders with Scotland to the north and Wales to the west.', 'England','2010-1-1');
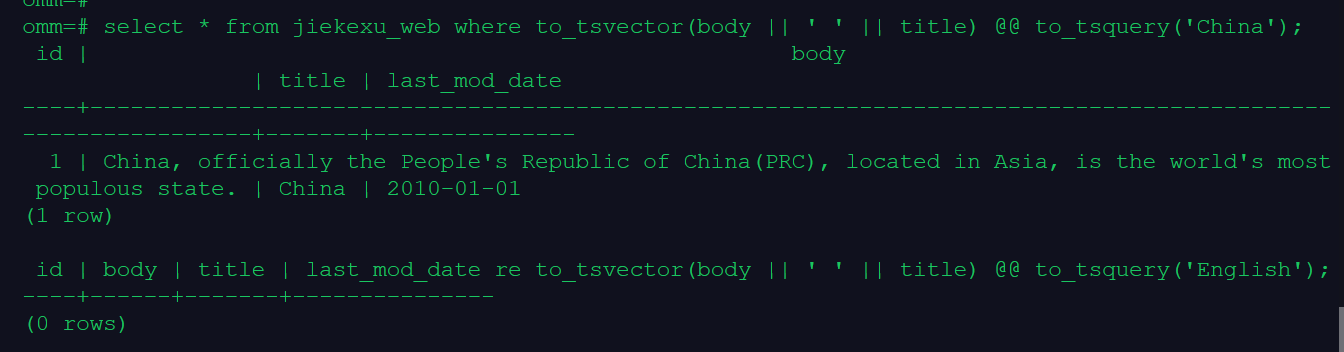
select * from jiekexu_web where to_tsvector(body || ' ' || title) @@ to_tsquery('China');
select * from jiekexu_web where to_tsvector(body || ' ' || title) @@ to_tsquery('English');
3.创建GIN索引
CREATE INDEX idx_jiekexu_web_body ON jiekexu_web USING gin(to_tsvector('english', body));
\d+ idx_jiekexu_web_body

4.清理数据
drop table jiekexu_web;
欧耶,第二十课全文索引及课后作业练习题完成啦!明天最后一课见!!!今天的内容对于传统 DBA 而言感觉还是有点难度的,后期再得看看相关资料,巩固巩固。
