




深夜惊雷.客户炸群
深夜一声惊雷,窗外,大雨倾盆而下,雨滴噼里啪啦地打在窗户上,拿起手机一看,2套Oracl RAC 集群同时宕掉了,信息还在不停的刷新着。
急忙打开电脑连上vpn查看日志,同时打电话给上级领导汇报情况。不到10分钟客户群炸锅了。2个主业绩线数据库不可用,想想就汗如雨下。
现场分析
发现集群日志一直再报crs 盘IO error,当时第一反应是crs盘损坏了。
- grid 日志
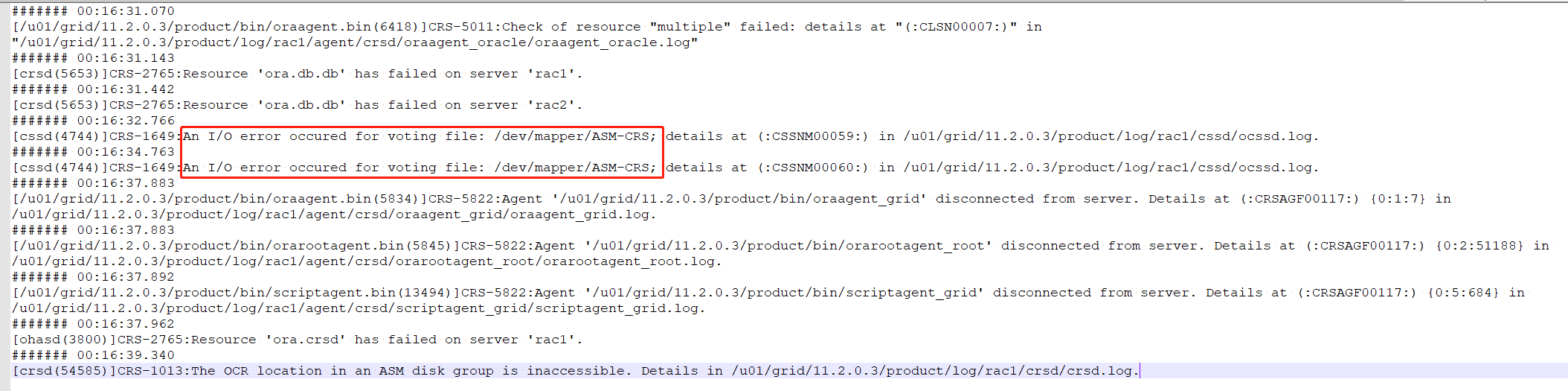
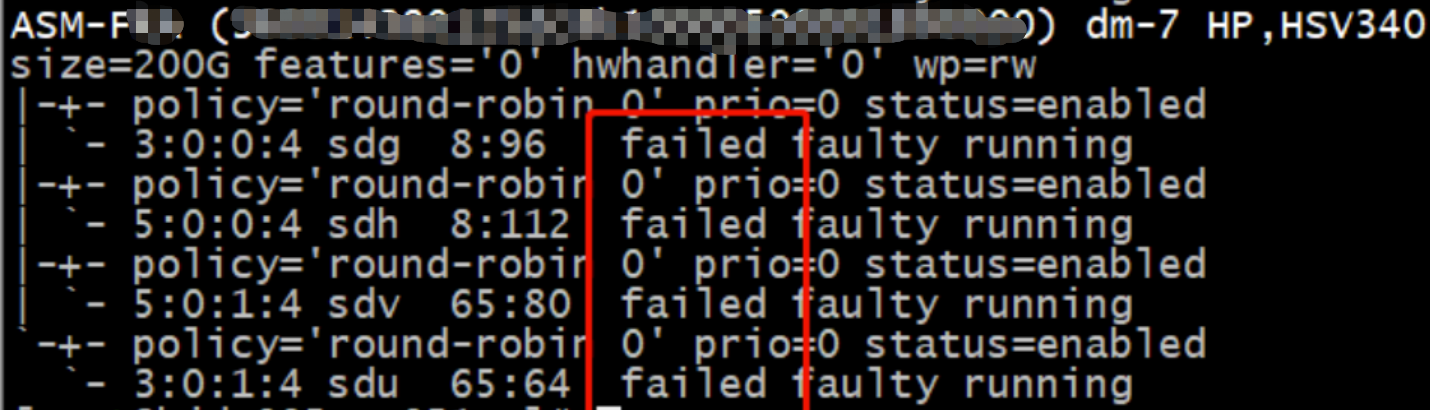
查看一下多路径的状态,发现所有的路径都是: failed ,当时方向指向了光纤交换机或存储,于是赶快给我们的存储工程师打电话确认,让其确认光纤和存储状态。
果然存储工程师反馈存储界面 三块硬盘状态都故障了 ,大大的“incredible”,三块硬盘一起坏了,这“幸运”职业生涯头一次啊。
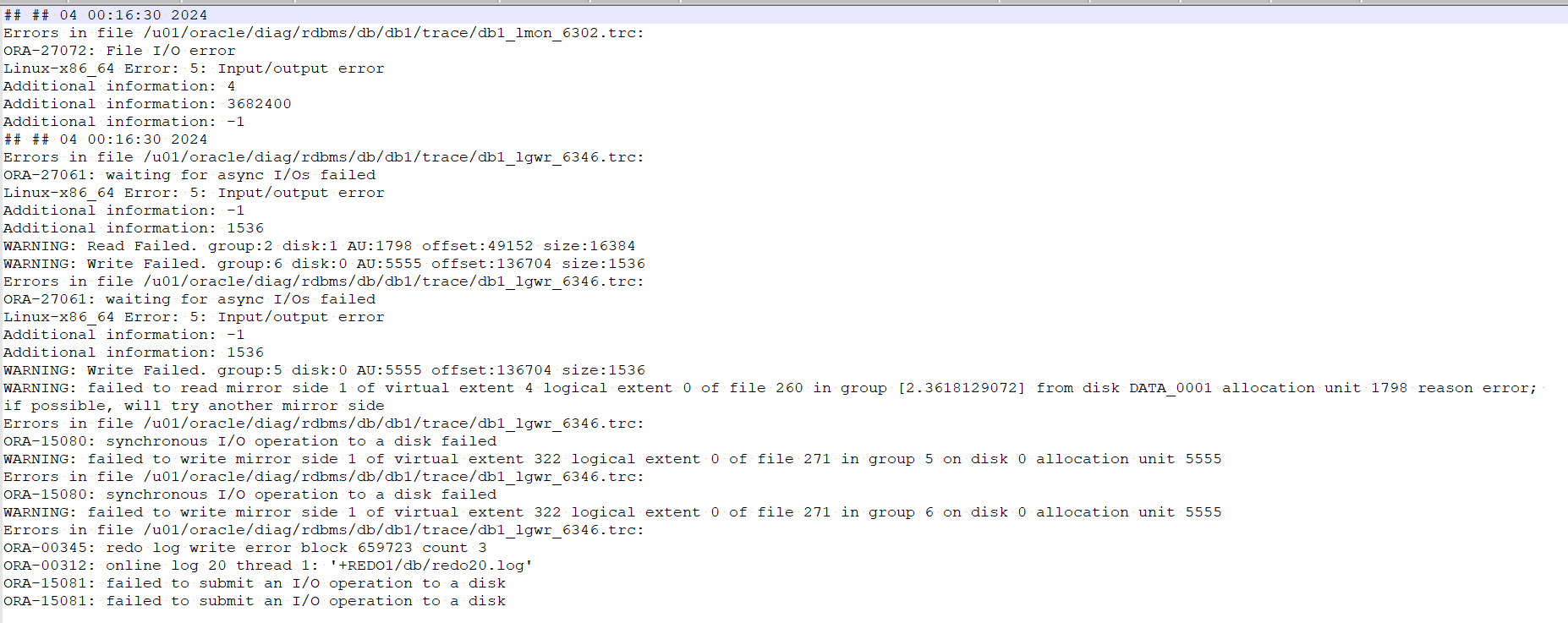
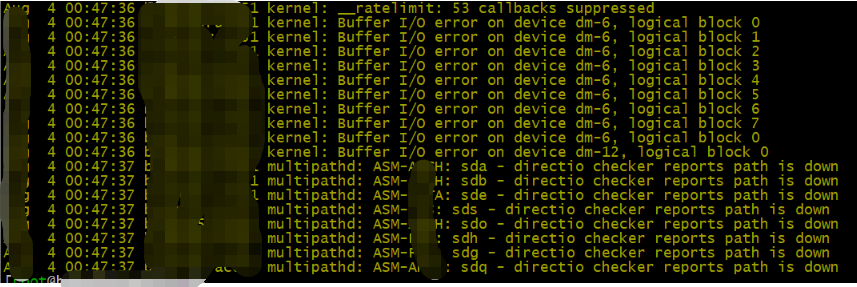
联系机房更换了硬盘没一会又故障了,联系厂商需要现场排查问题,考虑到业务不能再等了,于是领导决定启用备库恢复业务,RAC环境继续维修,如果能抢修过来到时候重做DG-RAC再切回来(此次领导与甲方沟通环节略)。于是来了一次Failover操作,幸亏我们每年都会做一次灾备演练,今年上个月演练完。
- Failover操作
- 调整process(以前是双节点RAC,连接需要考虑)
- 程序修改配置,启动程序,测试,上线的同时,我调整数据库redo大小,组数…。
- 禁用thread 2
alter database disable thread 2;
- 重新搭建备库继续保持容灾性。
- 存储被厂商拉回检查了。
- 重新规划架构,按业务线分离存储,各一套RAC环境,避免相互影响,否则人手真不够用。
总结
- 存储日志其实在今天中午已经有日志异常提醒了,只是监控不完善。
- 共用环境确实能节省成本,但风险也是共担的,压力也是双份的。
- 启动完备库后,需要考虑全面进行调整,例如在启用备库,维护RAC的同时避免和程序连接误连RAC导致数据不致,需要将RAC的防火墙闭掉所有应用IP。
- 一份经历,一份经验,一篇总结,一份收获。
文章推荐
-
实验笔记:
《Update 影响 Select 效率示例》
《Oracle 多表关联update》
《Oracle 查看Redo产生多少》
《Oracle 总结:为什么不走索引(一)》
《Oracle 总结:为什么不走索引(二)》 -
故障处理
《Oracle HASH JOIN 引起的TEMP爆满分析总结》
《expdp/impdp 任务终止不能靠Ctrl+C》
《Oracle_索引重建—优化索引碎片》
《Oracle 自动收集统计信息机制》
《DBA_TAB_MODIFICATIONS表的刷新策略测试》
《FY_Recover_Data.dbf》
《Oracle RAC 集群迁移文件操作.pdf》
《Oracle Date 字段索引使用测试.dbf》
《Oracle 诊断案例 :因应用死循环导致的CPU过高》
《记录一起索引rebuild与收集统计信息的事故》
《RAC DG删除备库redo时报ORA-01623》
《问答榜上引发的Oracle并行的探究(一)》
《问答榜上引发的Oracle并行的探究(二)》
《DG 同步延迟之奇怪的经典报错:ORA-16191》 -
等待事件
《log file sync》 等待事件问题分析汇总
《ASH报告发现:os thread startup 等待事件分析》 -
监控&脚本
《DG standby time 监控脚本部署》
《Oracle 慢SQL监控脚本》
《Oracle 慢SQL监控测试及监控脚本.pdf》
《oracle 监控表空间脚本 每月10号0点至06点不报警》
《Oracle 脚本实现简单的审计功能》 -
安装系列
《ORACLE_19C_linux安装.pdf》
《Oracle 19c-手工建库.pdf》
《19c单库升级19.11补丁.pdf》
《19c_rac补丁《19.11-p32841500》.pdf 》
《oracle_图形-单实例11.2.0.4升级19.3.pdf》
《oracle_11.2.0.3升级11.2.0.4–单实例升级.pdf》
《oracle_静默-单实例 11.2.0.4升级19.3.pdf》
《CentOS_6.7系统一步一步 RAC 11.2.0.4升级19.3.pdf》
《整理后_RAC_11.2.0.4升级19c.pdf》
欢迎赞赏支持或留言指正

